





































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)
















































































































(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






























_NicoElNino_Alamy.png?#)
.webp?#)
.webp?#)
































































































![New iOS 19 Leak Allegedly Reveals Updated Icons, Floating Tab Bar, More [Video]](https://www.iclarified.com/images/news/96958/96958/96958-640.jpg)

![Apple to Source More iPhones From India to Offset China Tariff Costs [Report]](https://www.iclarified.com/images/news/96954/96954/96954-640.jpg)
![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)
























































































































Beyond "One-Word, One-Meaning": Contextual Embeddings
For a long time, computers treated words like fixed puzzle pieces, each with one unchanging meaning. But as any language lover will tell you, words are more like chameleons — they adapt their color based on their surroundings. Today, we're diving into how contextual embeddings are changing the game in Natural Language Processing (NLP), making machines not just hear our words, but really understand them. The "Word Chameleon" Problem Words are like chameleons. They change their "color" (meaning) depending on their environment (the sentence). This is called polysemy (multiple meanings). Consider the word "break": "The vase broke." (Shatter) "Dawn broke." (Begin) "The news broke." (Announced) "He broke the record." (Surpass) "She broke the law." (Violate) "The burglar broke into the house." (Forced entry) "The newscaster broke into the movie broadcast." (Interrupt) "We broke even." (No profit or loss) One word, many meanings! A computer that thinks "break" always means "shatter" is going to be very confused. And it's not just "break." Think of "flat" (beer, tire, note, surface), "throw" (party, fight, ball, fit), or even the subtle differences in "crane" (bird vs. machine). The context defines the meaning. Static Embeddings: The Early Days Before contextual embeddings, we had static embeddings. Think of them as a digital dictionary, but instead of definitions, each word gets a unique vector (a list of numbers). Word2Vec: Learns by predicting either a word from its surrounding words (CBOW) or the surrounding words from a word (Skip-gram). The idea: "a word is known by the company it keeps." GloVe: Looks at how often words appear together across the entire corpus, not just in small windows. These were a huge improvement over just treating words as random strings. But… they were still "one-word, one-meaning". The Problem: "Bank" always had the same vector, no matter the context. "Apple" was just "apple," whether fruit or company. This is like a dictionary with only one definition per word — not very useful for real language! Enter Contextual Embeddings: Words That Change Color Contextual embeddings are the solution. They generate a different vector for a word each time it appears, based on the surrounding words. The vector adapts to the context. This is where the magic truly begins. How It Works Several groundbreaking models made this revolution happen: ELMo (Embeddings from Language Models): One of the first to really nail this. ELMo uses bidirectional LSTMs. An LSTM (Long Short-Term Memory) is a type of neural network that's good at remembering things from earlier in a sequence — perfect for understanding context. "Bidirectional" means it reads the sentence both forwards and backwards. It even combines information from multiple layers of the network, capturing different aspects of meaning (like syntax and semantics). BERT (Bidirectional Encoder Representations from Transformers): The game-changer. BERT uses the Transformer architecture, which relies on self-attention. Instead of processing words one by one, self-attention lets each word "look at" all the other words in the sentence, figuring out which are most important for understanding its meaning. This is key for BERT's bidirectionality. BERT is trained on two clever tasks: Masked Language Modeling (MLM): Some words are randomly replaced with a "[MASK]" token, and BERT has to guess the original word. This forces it to understand context from both sides. Next Sentence Prediction (NSP): BERT predicts whether two given sentences follow each other. This helps it learn relationships between sentences. GPT (Generative Pre-trained Transformer): Famous for generating text (like writing articles or poems!), GPT also produces great contextual embeddings. It also uses the Transformer, but it's primarily unidirectional (left-to-right), focusing on predicting the next word. This makes it amazing at generating text. GPT-2, GPT-3, GPT-4: Bigger and better versions of GPT. These models are huge (billions of parameters) and trained on massive amounts of text. And Many More!: RoBERTa (a more robust BERT), ALBERT (a smaller BERT), XLNet (combines the best of GPT and BERT), ELECTRA (very efficient training), T5 (treats everything as text-to-text), and many others. These models are all pre-trained on massive amounts of text, learning general language patterns. Then, they can be fine-tuned for specific tasks (like answering questions or classifying sentiment). Context in Action: Examples Let's see how this works in practice: "I need to go to the bank to deposit a check." (Financial) "Let's sit on the river bank and watch the ducks." (River edge) A static embedding gives "bank" the same vector in both. A contextual embedding (like BERT or ELMo) gives different vectors. The vector for "bank" in the first sentence will be
For a long time, computers treated words like fixed puzzle pieces, each with one unchanging meaning. But as any language lover will tell you, words are more like chameleons — they adapt their color based on their surroundings. Today, we're diving into how contextual embeddings are changing the game in Natural Language Processing (NLP), making machines not just hear our words, but really understand them.
The "Word Chameleon" Problem
Words are like chameleons. They change their "color" (meaning) depending on their environment (the sentence). This is called polysemy (multiple meanings).
Consider the word "break":
- "The vase broke." (Shatter)
- "Dawn broke." (Begin)
- "The news broke." (Announced)
- "He broke the record." (Surpass)
- "She broke the law." (Violate)
- "The burglar broke into the house." (Forced entry)
- "The newscaster broke into the movie broadcast." (Interrupt)
- "We broke even." (No profit or loss)
One word, many meanings! A computer that thinks "break" always means "shatter" is going to be very confused. And it's not just "break." Think of "flat" (beer, tire, note, surface), "throw" (party, fight, ball, fit), or even the subtle differences in "crane" (bird vs. machine). The context defines the meaning.
Static Embeddings: The Early Days
Before contextual embeddings, we had static embeddings. Think of them as a digital dictionary, but instead of definitions, each word gets a unique vector (a list of numbers).
Word2Vec:
- Learns by predicting either a word from its surrounding words (CBOW) or the surrounding words from a word (Skip-gram). The idea: "a word is known by the company it keeps."
GloVe:
- Looks at how often words appear together across the entire corpus, not just in small windows.
These were a huge improvement over just treating words as random strings. But… they were still "one-word, one-meaning".
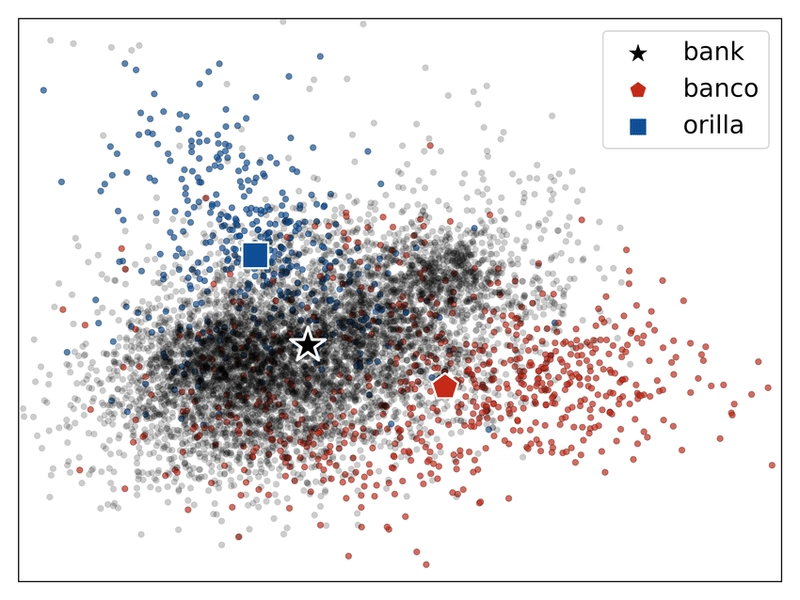
The Problem: "Bank" always had the same vector, no matter the context. "Apple" was just "apple," whether fruit or company. This is like a dictionary with only one definition per word — not very useful for real language!
Enter Contextual Embeddings: Words That Change Color
Contextual embeddings are the solution. They generate a different vector for a word each time it appears, based on the surrounding words. The vector adapts to the context. This is where the magic truly begins.
How It Works
Several groundbreaking models made this revolution happen:
ELMo (Embeddings from Language Models):
One of the first to really nail this. ELMo uses bidirectional LSTMs. An LSTM (Long Short-Term Memory) is a type of neural network that's good at remembering things from earlier in a sequence — perfect for understanding context. "Bidirectional" means it reads the sentence both forwards and backwards. It even combines information from multiple layers of the network, capturing different aspects of meaning (like syntax and semantics).
BERT (Bidirectional Encoder Representations from Transformers):
The game-changer. BERT uses the Transformer architecture, which relies on self-attention. Instead of processing words one by one, self-attention lets each word "look at" all the other words in the sentence, figuring out which are most important for understanding its meaning. This is key for BERT's bidirectionality.
BERT is trained on two clever tasks:
- Masked Language Modeling (MLM): Some words are randomly replaced with a "[MASK]" token, and BERT has to guess the original word. This forces it to understand context from both sides.
- Next Sentence Prediction (NSP): BERT predicts whether two given sentences follow each other. This helps it learn relationships between sentences.
GPT (Generative Pre-trained Transformer):
Famous for generating text (like writing articles or poems!), GPT also produces great contextual embeddings. It also uses the Transformer, but it's primarily unidirectional (left-to-right), focusing on predicting the next word. This makes it amazing at generating text.
- GPT-2, GPT-3, GPT-4: Bigger and better versions of GPT. These models are huge (billions of parameters) and trained on massive amounts of text.
- And Many More!: RoBERTa (a more robust BERT), ALBERT (a smaller BERT), XLNet (combines the best of GPT and BERT), ELECTRA (very efficient training), T5 (treats everything as text-to-text), and many others.
These models are all pre-trained on massive amounts of text, learning general language patterns. Then, they can be fine-tuned for specific tasks (like answering questions or classifying sentiment).
Context in Action: Examples
Let's see how this works in practice:
- "I need to go to the bank to deposit a check." (Financial)
- "Let's sit on the river bank and watch the ducks." (River edge)
A static embedding gives "bank" the same vector in both. A contextual embedding (like BERT or ELMo) gives different vectors. The vector for "bank" in the first sentence will be similar to vectors for "money," "finance," etc. The vector in the second will be similar to "river," "shore," etc. The computer gets it! The surrounding words (the context) provide the clues that the model uses to create the right representation.
Under the Hood (Simplified!)
Here's the simplified secret sauce:
- Deep Neural Networks (DNNs): Lots of layers of interconnected "neurons," inspired by the brain. The "deep" part lets them learn complex patterns.
- Recurrent Neural Networks (RNNs) and LSTMs: Good for sequential data (like sentences). LSTMs are a special type that can "remember" things over longer sequences. ELMo uses these.
- Transformers and Self-Attention: The real magic. Instead of processing words one by one, a Transformer looks at all words simultaneously, using self-attention to figure out which words are most important to each other. This is how BERT and GPT work.
- Pre-training: Like sending the model to a massive "language school." They're trained on huge amounts of text to learn general language patterns.
- Contextualization: When you give the model a sentence, it uses its pre-trained knowledge and the specific context to create a unique vector for each word. This is the "dynamic" part.
- Fine-tuning: For specific tasks, you can further train (fine-tune) the model on a smaller, task-specific dataset.
Beyond English: Multilingual BERT (mBERT)
It's trained on 104 languages at the same time. And here's the amazing part: it works across languages even without being explicitly told how.
This "cross-linguality" means that "dog" in English and "perro" in Spanish will have similar vectors. You can train a model on, say, English data, and then use it on Spanish without any further training! This is called zero-shot cross-lingual transfer.
This is a huge deal for languages with less data available online. We can leverage the resources of English to build models for, say, Swahili. Research has even shown that you can remove the "language identity" from mBERT's embeddings, making them even more language-neutral.
Large Language Models (LLMs)
The trend is clear: bigger models, more data. Models like GPT-4, Gemini, Llama, and now DeepSeek have billions (or even trillions!) of parameters. They're trained on so much text it's mind-boggling, and they're showing "emergent abilities" — things smaller models just can't do, like:
- Few-shot learning: Learning new tasks with just a few examples.
- Basic reasoning: Answering questions that require some common sense.
- Better translation: Even more fluent and accurate translations.
These models are expensive to train, but they're pushing the boundaries of what's possible. The large input size of newer models (~32,000 words for GPT-4) allows it to take the context of large documents, such as books, into account when creating embeddings. This has given rise to Vector databases for searching large numbers of documents.
The Future is Contextual
The shift from static to contextual embeddings is more than just a technical upgrade — it's a fundamental change in how we build and interact with language AI. By capturing the dynamic nature of language, we're creating systems that understand our words as we mean them, opening up exciting possibilities in translation, search, chatbots, and beyond.
As researchers continue to refine these models, the boundary between human and machine language understanding is blurring. The future promises even more sophisticated systems that can interact with us in a truly human-like way.
Further Exploration
Ready to dive deeper? Here are some resources to fuel your journey:
- A Survey on Contextual Embeddings
- Original Research Papers (BERT, ELMo, GPT):
Happy embedding, and welcome to the contextual future of language!



