![[The AI Show Episode 148]: Microsoft’s Quiet AI Layoffs, US Copyright Office’s Bombshell AI Guidance, 2025 State of Marketing AI Report, and OpenAI Codex](https://www.marketingaiinstitute.com/hubfs/ep%20148%20cover%20%281%29.png)


![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)









































































































































































































































.jpg?#)

























_Prostock-studio_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)










































































































![Apple's iPhone Shift to India Accelerates With $1.5 Billion Foxconn Investment [Report]](https://www.iclarified.com/images/news/97357/97357/97357-640.jpg)
![Apple Releases iPadOS 17.7.8 for Older Devices [Download]](https://www.iclarified.com/images/news/97358/97358/97358-640.jpg)































































AI-Driven SQL Dataset Optimization: Best Practices & Updates for Modern Applications
Preface When we conduct AI research in the field of SQL, we find that the improvement of application capabilities in the SQL field largely depends on high-quality datasets. We need to synthesize data based on this to generate training sets and evaluation sets for specific problems. To help more developers quickly access resources, we have sorted out a list of publicly available Text2SQL datasets in recent years and share them with you here. We have organized the papers and dataset addresses of the datasets in chronological order, including representative Text2SQL datasets in recent years. Among them, representatives of the evaluation set: Spider, BIRD-SQL, we have also associated the leaderboard in our list. Next, I will focus on introducing the latest dataset in 2025, and will continue to collect and bring the latest information to everyone. Introduction to New Datasets NL2SQL-Bugs NL2SQL-BUGs is the first benchmark dataset focusing on detecting semantic errors in NL2SQL translation, aiming to solve the problem that the SQL queries generated by existing models have semantic errors that are not recognized by the system. This dataset constructs a two-level classification system (9 categories and 31 subcategories) through expert annotation, containing 2,018 instances (with error annotations). Experiments found that the current large model's average detection accuracy is only 75.16%, and successfully identified 122 existing annotation errors in the BIRD and Spider benchmarks. This achievement provides an important validation set for error detection and correction of NL2SQL systems. OmniSQL SynSQL-2.5M is the dataset released in the OmniSQL paper, which the author believes is currently the largest cross-domain text-to-SQL synthetic dataset. It is built using pure synthetic data technology, containing 2.5 million high-quality samples, covering 16,583 databases and a large number of diverse SQL syntax structures. This dataset is generated based on open-source large models, providing high-quality data that can be directly used for training, and is open under the Apache 2.0 license. The OmniSQL series of large models (7B/14B/32B) are also released. Developers can also use this dataset to train their own models. TINYSQL TinySQL is a progressive text-to-SQL dataset aimed at solving the problem that existing SQL datasets are too complex and not suitable for mechanism interpretability research. By controlling the complexity of SQL commands and language variants, it provides query tasks from basic to advanced levels, supporting model behavior analysis. This dataset helps researchers understand how Transformers learn and generate SQL queries, and evaluate the reliability of interpretability methods. Application scenarios include model mechanism analysis, interpretability technology verification, and improvement of synthetic dataset design. Datasets Lists

Preface
When we conduct AI research in the field of SQL, we find that the improvement of application capabilities in the SQL field largely depends on high-quality datasets. We need to synthesize data based on this to generate training sets and evaluation sets for specific problems. To help more developers quickly access resources, we have sorted out a list of publicly available Text2SQL datasets in recent years and share them with you here.
We have organized the papers and dataset addresses of the datasets in chronological order, including representative Text2SQL datasets in recent years. Among them, representatives of the evaluation set: Spider, BIRD-SQL, we have also associated the leaderboard in our list.
Next, I will focus on introducing the latest dataset in 2025, and will continue to collect and bring the latest information to everyone.
Introduction to New Datasets
NL2SQL-Bugs
NL2SQL-BUGs is the first benchmark dataset focusing on detecting semantic errors in NL2SQL translation, aiming to solve the problem that the SQL queries generated by existing models have semantic errors that are not recognized by the system. This dataset constructs a two-level classification system (9 categories and 31 subcategories) through expert annotation, containing 2,018 instances (with error annotations). Experiments found that the current large model's average detection accuracy is only 75.16%, and successfully identified 122 existing annotation errors in the BIRD and Spider benchmarks. This achievement provides an important validation set for error detection and correction of NL2SQL systems.
OmniSQL
SynSQL-2.5M is the dataset released in the OmniSQL paper, which the author believes is currently the largest cross-domain text-to-SQL synthetic dataset. It is built using pure synthetic data technology, containing 2.5 million high-quality samples, covering 16,583 databases and a large number of diverse SQL syntax structures. This dataset is generated based on open-source large models, providing high-quality data that can be directly used for training, and is open under the Apache 2.0 license. The OmniSQL series of large models (7B/14B/32B) are also released. Developers can also use this dataset to train their own models.

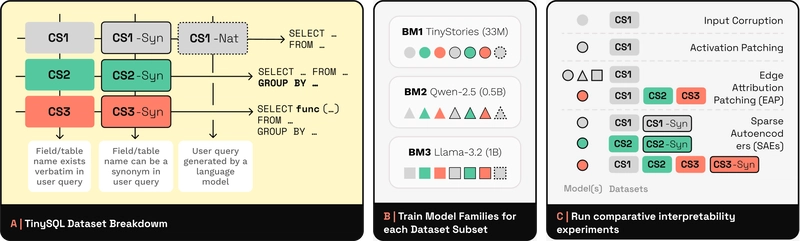
TINYSQL
TinySQL is a progressive text-to-SQL dataset aimed at solving the problem that existing SQL datasets are too complex and not suitable for mechanism interpretability research. By controlling the complexity of SQL commands and language variants, it provides query tasks from basic to advanced levels, supporting model behavior analysis. This dataset helps researchers understand how Transformers learn and generate SQL queries, and evaluate the reliability of interpretability methods. Application scenarios include model mechanism analysis, interpretability technology verification, and improvement of synthetic dataset design.