









































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)













































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























































































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)













































































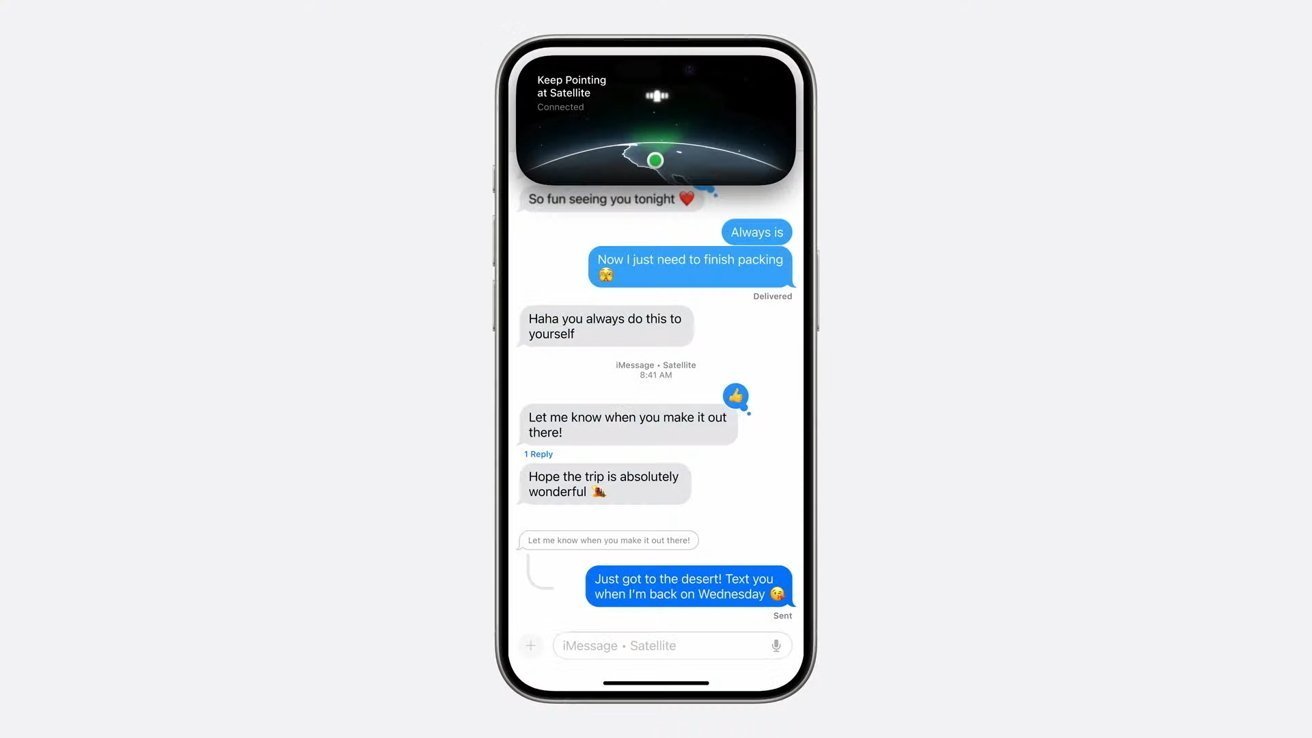




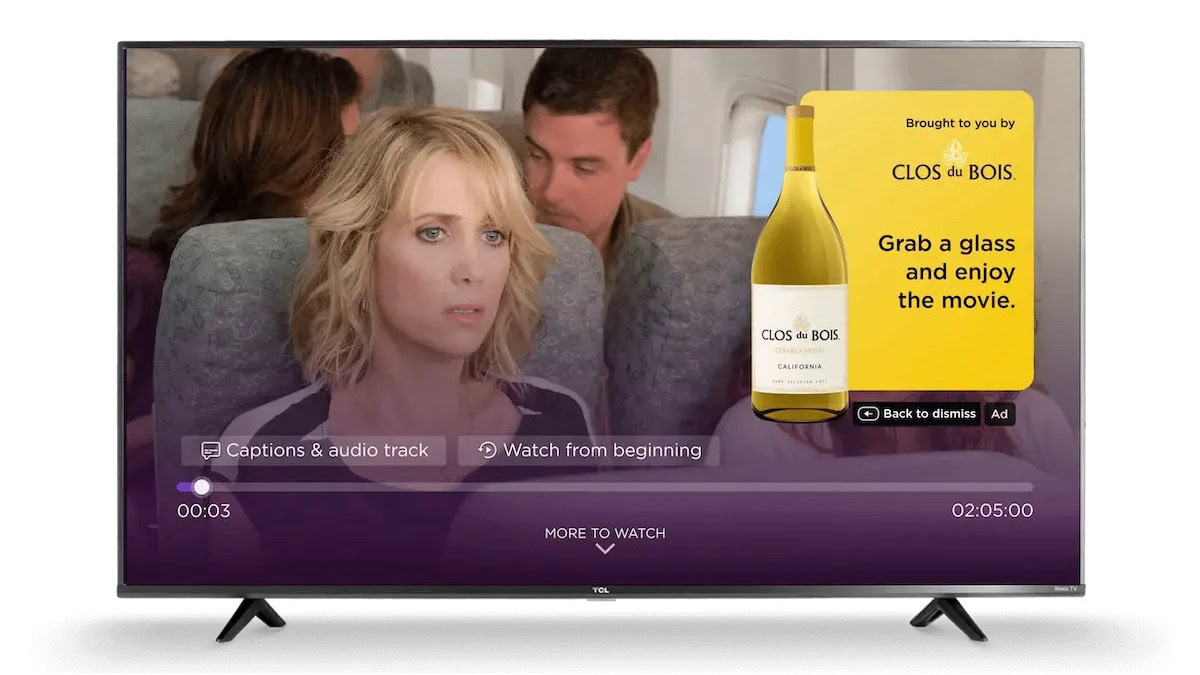
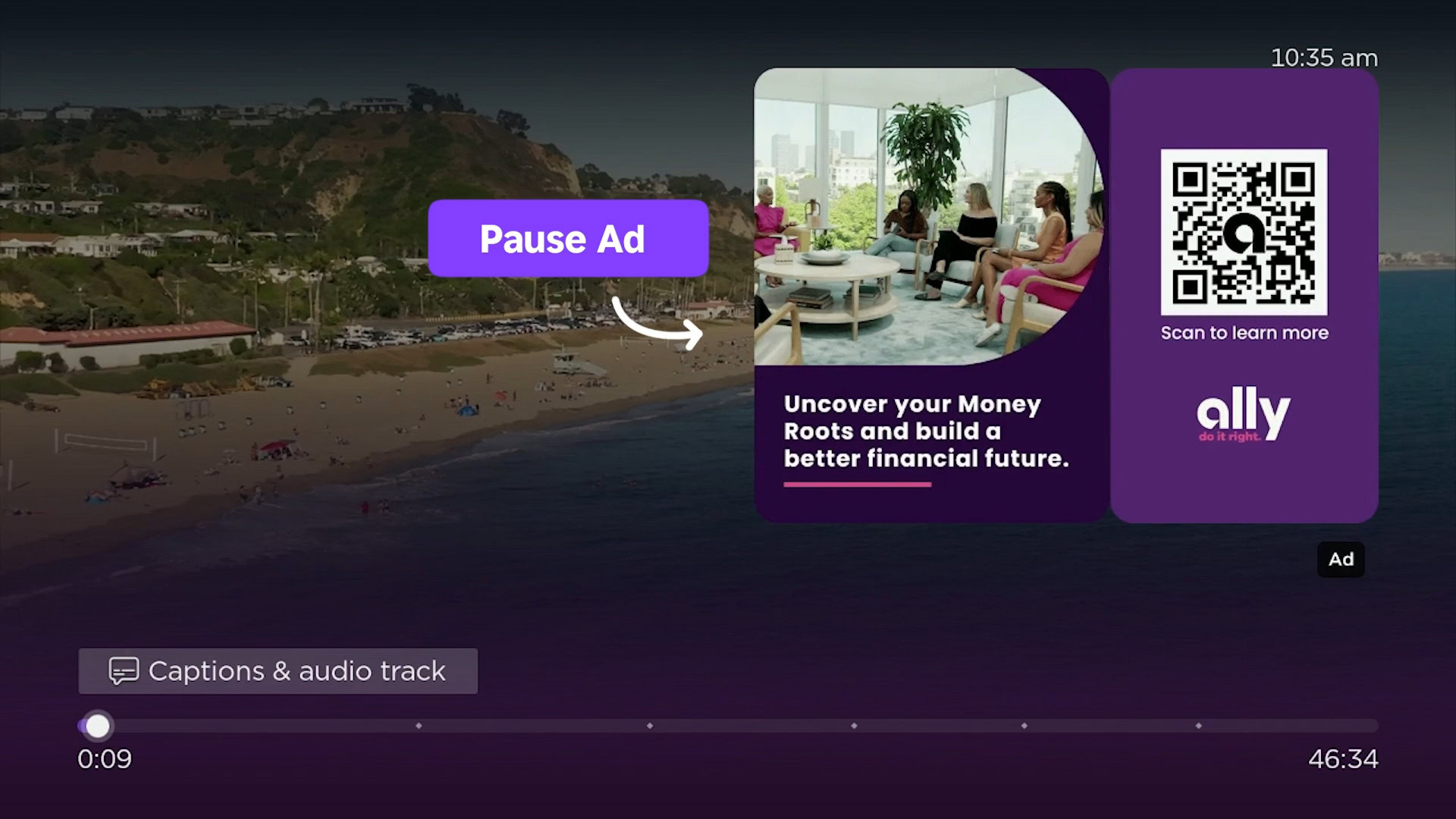




![Roku clarifies how ‘Pause Ads’ work amid issues with some HDR content [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/roku-pause-ad-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![Look at this Chrome Dino figure and its adorable tiny boombox [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/chrome-dino-youtube-boombox-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)



























































































SQL Query Optimization for Data Engineers
Moving data efficiently can make the difference between a smooth system and a frustratingly slow one. Optimizing your SQL queries not only speeds up your jobs, but also reduces cloud costs and improves system scalability. In this post, I'll share 7 practical SQL optimization tips you can apply immediately, with real-world examples. I. Always SELECT Only the Columns You Need It’s easy to get lazy and use SELECT *, especially when you're exploring data. However, pulling all columns increases the amount of data transferred across the network and the memory needed to process it. On wide tables, this can severely impact performance. Bad example: SELECT * FROM orders; Better: SELECT order_id, order_date, total_amount FROM orders; II. Use Proper Indexes Indexes are critical for query performance, especially when filtering (WHERE), joining (JOIN), or sorting (ORDER BY). If your query frequently filters on a column, it’s a strong candidate for indexing. Example: CREATE INDEX idx_orders_customer_id ON orders(customer_id); Pro tip: Always check your queries with EXPLAIN to verify whether your indexes are actually being used. A missing or unused index can make queries 10x slower. III. Avoid Unnecessary JOINs JOINs are powerful — but they can be costly, especially across large tables. If you're joining tables just to retrieve a field you don't actually use, or if the JOIN isn't adding value to your result set, rethink the query. Best practices: Fetch only what you truly need Consider denormalization if two tables are always accessed together Use INNER JOIN instead of LEFT JOIN when you don't need unmatched rows Example: Instead of this: SELECT o.order_id, c.customer_name FROM orders o LEFT JOIN customers c ON o.customer_id = c.customer_id; If you know every order has a customer, prefer: SELECT o.order_id, c.customer_name FROM orders o INNER JOIN customers c ON o.customer_id = c.customer_id; IV. Filter Early With WHERE Clauses Always narrow down your data as early as possible. The earlier you apply your WHERE filters, the less data the database engine needs to process — making the query faster and lighter. Example: SELECT customer_id, order_id FROM orders WHERE order_date > '2025-01-01'; Filtering after joining or fetching lots of rows will cause unnecessary load. Make filtering a priority. V. Limit Result Sets When Exploring When you're writing queries to explore data or debug issues, always add a LIMIT to avoid pulling millions of rows by accident. Example: SELECT * FROM orders WHERE total_amount > 1000 LIMIT 100; This tiny habit prevents unnecessary load on your database and keeps you from crashing your local environment. VI. Analyze Execution Plans (EXPLAIN) Want to know why a query is slow? Use your database’s execution plan tools. In PostgreSQL and MySQL, running EXPLAIN shows how the database will execute your query whether it will do a sequential scan (slow) or an index scan (fast). Example: EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 123; Look out for: Seq Scan → sequentially scanning the whole table (bad for large tables) Index Scan → using indexes efficiently (good) High-cost operations like sorts, nested loops, or large hash joins Learning to read execution plans is one of the best investments you can make as a data engineer. VII. Batch Large Updates and Inserts Updating or inserting millions of rows at once can lock tables and overwhelm resources. Instead, break large operations into smaller batches. Example: Instead of: INSERT INTO large_table SELECT * FROM very_large_temp_table; Use a batching strategy: INSERT INTO large_table SELECT * FROM very_large_temp_table WHERE id BETWEEN 1 AND 10000; -- Repeat with next batch This keeps locks short, memory usage reasonable, and reduces the risk of timeouts.

Moving data efficiently can make the difference between a smooth system and a frustratingly slow one. Optimizing your SQL queries not only speeds up your jobs, but also reduces cloud costs and improves system scalability.
In this post, I'll share 7 practical SQL optimization tips you can apply immediately, with real-world examples.
I. Always SELECT Only the Columns You Need
It’s easy to get lazy and use SELECT *, especially when you're exploring data.
However, pulling all columns increases the amount of data transferred across the network and the memory needed to process it. On wide tables, this can severely impact performance.
Bad example:
SELECT * FROM orders;
Better:
SELECT order_id, order_date, total_amount FROM orders;
II. Use Proper Indexes
Indexes are critical for query performance, especially when filtering (WHERE), joining (JOIN), or sorting (ORDER BY).
If your query frequently filters on a column, it’s a strong candidate for indexing.
Example:
CREATE INDEX idx_orders_customer_id ON orders(customer_id);
Pro tip: Always check your queries with EXPLAIN to verify whether your indexes are actually being used. A missing or unused index can make queries 10x slower.
III. Avoid Unnecessary JOINs
JOINs are powerful — but they can be costly, especially across large tables.
If you're joining tables just to retrieve a field you don't actually use, or if the JOIN isn't adding value to your result set, rethink the query.
Best practices:
- Fetch only what you truly need
- Consider denormalization if two tables are always accessed together
- Use INNER JOIN instead of LEFT JOIN when you don't need unmatched rows
Example:
Instead of this:
SELECT o.order_id, c.customer_name
FROM orders o
LEFT JOIN customers c ON o.customer_id = c.customer_id;
If you know every order has a customer, prefer:
SELECT o.order_id, c.customer_name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
IV. Filter Early With WHERE Clauses
Always narrow down your data as early as possible.
The earlier you apply your WHERE filters, the less data the database engine needs to process — making the query faster and lighter.
Example:
SELECT customer_id, order_id
FROM orders
WHERE order_date > '2025-01-01';
Filtering after joining or fetching lots of rows will cause unnecessary load. Make filtering a priority.
V. Limit Result Sets When Exploring
When you're writing queries to explore data or debug issues, always add a LIMIT to avoid pulling millions of rows by accident.
Example:
SELECT * FROM orders
WHERE total_amount > 1000
LIMIT 100;
This tiny habit prevents unnecessary load on your database and keeps you from crashing your local environment.
VI. Analyze Execution Plans (EXPLAIN)
Want to know why a query is slow?
Use your database’s execution plan tools.
In PostgreSQL and MySQL, running EXPLAIN shows how the database will execute your query whether it will do a sequential scan (slow) or an index scan (fast).
Example:
EXPLAIN ANALYZE
SELECT * FROM orders WHERE customer_id = 123;
Look out for:
- Seq Scan → sequentially scanning the whole table (bad for large tables)
- Index Scan → using indexes efficiently (good)
- High-cost operations like sorts, nested loops, or large hash joins
Learning to read execution plans is one of the best investments you can make as a data engineer.
VII. Batch Large Updates and Inserts
Updating or inserting millions of rows at once can lock tables and overwhelm resources.
Instead, break large operations into smaller batches.
Example:
Instead of:
INSERT INTO large_table
SELECT * FROM very_large_temp_table;
Use a batching strategy:
INSERT INTO large_table
SELECT * FROM very_large_temp_table
WHERE id BETWEEN 1 AND 10000;
-- Repeat with next batch
This keeps locks short, memory usage reasonable, and reduces the risk of timeouts.





