






















































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)









































































































(1).jpg?#)
































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












































































































![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)




























































































In-Depth Go Concurrency: A Practical Guide to Goroutine Performance
Hey there, fellow Go enthusiasts! If you’re building high-performance apps or wrestling with concurrency challenges, you’ve likely heard of goroutines—Go’s secret sauce for lightweight, efficient concurrency. In this guide, we’ll dive deep into goroutines, explore how they work, and share practical techniques to optimize their performance in real-world projects. Whether you’re a Go newbie looking to level up or a seasoned dev troubleshooting concurrency woes, this one’s for you. Who’s This For? Developers comfy with Go basics, eager to master concurrency Engineers debugging goroutine quirks in production Anyone aiming to write faster, more reliable Go code What You’ll Learn How goroutines tick under the hood Proven optimization tricks for concurrent code How to spot and fix common goroutine pitfalls Tips to design slick, scalable systems Let’s get started! II. Goroutine Basics: A Quick Refresher 1. What Makes Goroutines Special? Lightweight Magic Think of goroutines as the nimble electric scooters of concurrency—way lighter than the bulky trucks of traditional threads. Spinning up a goroutine takes just ~2KB of stack space (compared to ~1MB for threads), and it can grow dynamically up to 1GB if needed. Here’s a quick taste: func main() { go func() { fmt.Println("Hey from a goroutine!") }() time.Sleep(time.Second) // Give it a sec to run } The GMP Scheduling Trick Go’s runtime uses a clever GMP model to manage goroutines: G (Goroutine): Your tasks M (Machine): OS threads doing the heavy lifting P (Processor): Scheduling middlemen Picture it like an assembly line: Ps assign Gs to Ms, keeping everything humming efficiently. Unlike OS threads, Go’s runtime handles the scheduling, so you can launch millions of goroutines without breaking a sweat. Goroutines vs. Threads: The Showdown Feature Goroutine Thread Startup Cost ~2KB ~1MB Scheduling Go Runtime OS Max Instances Millions Thousands Communication Channels Shared Memory Launch Time Microseconds Milliseconds 2. Where Goroutines Shine Crunching Tasks Concurrently Got a bunch of independent jobs? Goroutines make it a breeze: func processItems(items []Item) { var wg sync.WaitGroup for _, item := range items { wg.Add(1) go func(i Item) { // Pass item to avoid closure gotchas defer wg.Done() processItem(i) }(item) } wg.Wait() } Going Async Need non-blocking ops? Pair goroutines with channels: func asyncProcess() chan Result { ch := make(chan Result) go func() { ch

Hey there, fellow Go enthusiasts! If you’re building high-performance apps or wrestling with concurrency challenges, you’ve likely heard of goroutines—Go’s secret sauce for lightweight, efficient concurrency. In this guide, we’ll dive deep into goroutines, explore how they work, and share practical techniques to optimize their performance in real-world projects. Whether you’re a Go newbie looking to level up or a seasoned dev troubleshooting concurrency woes, this one’s for you.
Who’s This For?
- Developers comfy with Go basics, eager to master concurrency
- Engineers debugging goroutine quirks in production
- Anyone aiming to write faster, more reliable Go code
What You’ll Learn
- How goroutines tick under the hood
- Proven optimization tricks for concurrent code
- How to spot and fix common goroutine pitfalls
- Tips to design slick, scalable systems
Let’s get started!
II. Goroutine Basics: A Quick Refresher
1. What Makes Goroutines Special?
Lightweight Magic
Think of goroutines as the nimble electric scooters of concurrency—way lighter than the bulky trucks of traditional threads. Spinning up a goroutine takes just ~2KB of stack space (compared to ~1MB for threads), and it can grow dynamically up to 1GB if needed. Here’s a quick taste:
func main() {
go func() {
fmt.Println("Hey from a goroutine!")
}()
time.Sleep(time.Second) // Give it a sec to run
}
The GMP Scheduling Trick
Go’s runtime uses a clever GMP model to manage goroutines:
- G (Goroutine): Your tasks
- M (Machine): OS threads doing the heavy lifting
- P (Processor): Scheduling middlemen
Picture it like an assembly line: Ps assign Gs to Ms, keeping everything humming efficiently. Unlike OS threads, Go’s runtime handles the scheduling, so you can launch millions of goroutines without breaking a sweat.
Goroutines vs. Threads: The Showdown
| Feature | Goroutine | Thread |
|---|---|---|
| Startup Cost | ~2KB | ~1MB |
| Scheduling | Go Runtime | OS |
| Max Instances | Millions | Thousands |
| Communication | Channels | Shared Memory |
| Launch Time | Microseconds | Milliseconds |
2. Where Goroutines Shine
Crunching Tasks Concurrently
Got a bunch of independent jobs? Goroutines make it a breeze:
func processItems(items []Item) {
var wg sync.WaitGroup
for _, item := range items {
wg.Add(1)
go func(i Item) { // Pass item to avoid closure gotchas
defer wg.Done()
processItem(i)
}(item)
}
wg.Wait()
}
Going Async
Need non-blocking ops? Pair goroutines with channels:
func asyncProcess() chan Result {
ch := make(chan Result)
go func() {
ch <- heavyWork() // Long-running task
}()
return ch
}
Boosting Performance
Parallelize across CPU cores for a speed boost:
func parallelCompute(data []int) []int {
cores := runtime.NumCPU()
var wg sync.WaitGroup
result := make([]int, len(data))
chunk := len(data) / cores
for i := 0; i < cores; i++ {
wg.Add(1)
start := i * chunk
go func(s int) {
defer wg.Done()
for j := s; j < s+chunk && j < len(data); j++ {
result[j] = compute(data[j])
}
}(start)
}
wg.Wait()
return result
}
IV. Real-World Wins: Goroutines in Action
Let’s move beyond theory and see how goroutines solve real problems. Here are two case studies from the trenches—optimized APIs and big data crunching—complete with code and results.
1. Turbocharging a High-Concurrency API
Imagine you’re building an API that’s getting hammered with requests. The old setup chokes at 1000 QPS (queries per second), with sluggish responses and ballooning memory use. Enter goroutines and a worker pool.
The Fix
We built a lean APIServer with rate limiting and a worker pool to handle requests efficiently:
type APIServer struct {
pool *WorkerPool
limiter *rate.Limiter
}
func NewAPIServer(workers int, rps int) *APIServer {
return &APIServer{
pool: NewWorkerPool(workers),
limiter: rate.NewLimiter(rate.Limit(rps), rps*2), // Burst buffer
}
}
func (s *APIServer) HandleRequest(w http.ResponseWriter, r *http.Request) {
if !s.limiter.Allow() {
http.Error(w, "Chill out—too many requests!", http.StatusTooManyRequests)
return
}
task := Task{
ID: uuid.New().String(),
Result: make(chan string),
}
select {
case s.pool.tasks <- task:
select {
case res := <-task.Result:
fmt.Fprintf(w, res)
case <-time.After(3 * time.Second):
http.Error(w, "Timeout—try again!", http.StatusGatewayTimeout)
}
default:
http.Error(w, "Server’s swamped!", http.StatusServiceUnavailable)
}
}
// Assume WorkerPool from earlier section
The Payoff
| Metric | Before | After | Boost |
|---|---|---|---|
| QPS | 1000 | 5000 | 400% |
| Response Time | 200ms | 50ms | 75% faster |
| Memory Footprint | 2GB | 800MB | 60% leaner |
Takeaway: A worker pool caps resource use, while rate limiting keeps traffic sane. Timeout checks ensure no request hangs forever.
2. Crushing Large-Scale Data Processing
Now picture a 10GB log file you need to process—line by line, fast. Sequential reads won’t cut it. Let’s parallelize it with goroutines and batching.
The Solution
A DataProcessor that splits work across workers:
type DataProcessor struct {
tasks chan []string
results chan string
wg sync.WaitGroup
batchSize int
}
func NewDataProcessor(workers, batchSize int) *DataProcessor {
dp := &DataProcessor{
tasks: make(chan []string, workers),
results: make(chan string, 100),
batchSize: batchSize,
}
dp.Start(workers)
return dp
}
func (dp *DataProcessor) Start(workers int) {
for i := 0; i < workers; i++ {
dp.wg.Add(1)
go func() {
defer dp.wg.Done()
for batch := range dp.tasks {
for _, line := range batch {
dp.results <- processLine(line) // e.g., parse and summarize
}
}
}()
}
}
func (dp *DataProcessor) ProcessFile(filename string) ([]string, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close()
scanner := bufio.NewScanner(file)
batch := []string{}
for scanner.Scan() {
batch = append(batch, scanner.Text())
if len(batch) >= dp.batchSize {
dp.tasks <- batch
batch = []string{}
}
}
if len(batch) > 0 {
dp.tasks <- batch
}
close(dp.tasks)
go func() { dp.wg.Wait(); close(dp.results) }()
var results []string
for r := range dp.results {
results = append(results, r)
}
return results, scanner.Err()
}
// Usage
func main() {
dp := NewDataProcessor(4, 1000) // 4 workers, 1000-line batches
results, err := dp.ProcessFile("huge.log")
if err != nil {
log.Fatal(err)
}
fmt.Printf("Processed %d lines!\n", len(results))
}
The Result
- Before: 20 minutes on a single thread.
- After: 5 minutes with 4 cores—75% faster.
- Memory stayed flat thanks to batching and bounded channels.
Takeaway: Split big tasks into chunks, feed them to a worker pool, and collect results via channels. It’s scalable and keeps resource use predictable.
V. Watch Your Step: Common Goroutine Pitfalls
Goroutines are awesome, but they come with traps that can bite you if you’re not careful. Let’s spotlight two big ones—concurrency safety and performance hiccups—and show you how to sidestep them.
1. Concurrency Safety: Don’t Let Races Ruin Your Day
The Data Race Nightmare
Ever seen a counter mysteriously jump to the wrong value? That’s a data race—multiple goroutines stomping on shared data. Here’s a classic oops:
func main() {
counter := 0
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
counter++ // Race alert! Multiple goroutines clash here
}()
}
wg.Wait()
fmt.Println(counter) // Spoiler: not 100
}
Fix It with Sync
Lock it down with a mutex:
type SafeCounter struct {
mu sync.Mutex
count int
}
func (c *SafeCounter) Inc() {
c.mu.Lock()
defer c.mu.Unlock()
c.count++
}
func main() {
c := SafeCounter{}
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
c.Inc()
}()
}
wg.Wait()
fmt.Println(c.count) // 100, guaranteed
}
Or go atomic for lightweight ops:
var count atomic.Int32
func main() {
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
count.Add(1)
}()
}
wg.Wait()
fmt.Println(count.Load()) // 100, no sweat
}
Deadlock Drama
Goroutines can also grind to a halt in a deadlock—each waiting for the other forever:
func main() {
ch1, ch2 := make(chan int), make(chan int)
go func() { ch1 <- 1; <-ch2 }() // Stalls waiting for ch2
go func() { ch2 <- 1; <-ch1 }() // Stalls waiting for ch1
time.Sleep(time.Second) // Deadlock city
}
Fix it with select to break the standoff:
func main() {
ch1, ch2 := make(chan int), make(chan int)
go func() {
select {
case ch1 <- 1:
fmt.Println(<-ch2)
case v := <-ch2:
ch1 <- v
}
}()
go func() {
select {
case ch2 <- 1:
fmt.Println(<-ch1)
case v := <-ch1:
ch2 <- v
}
}()
time.Sleep(time.Second)
}
Takeaway: Use sync.Mutex or atomic for shared data, and lean on select to keep channels flowing.
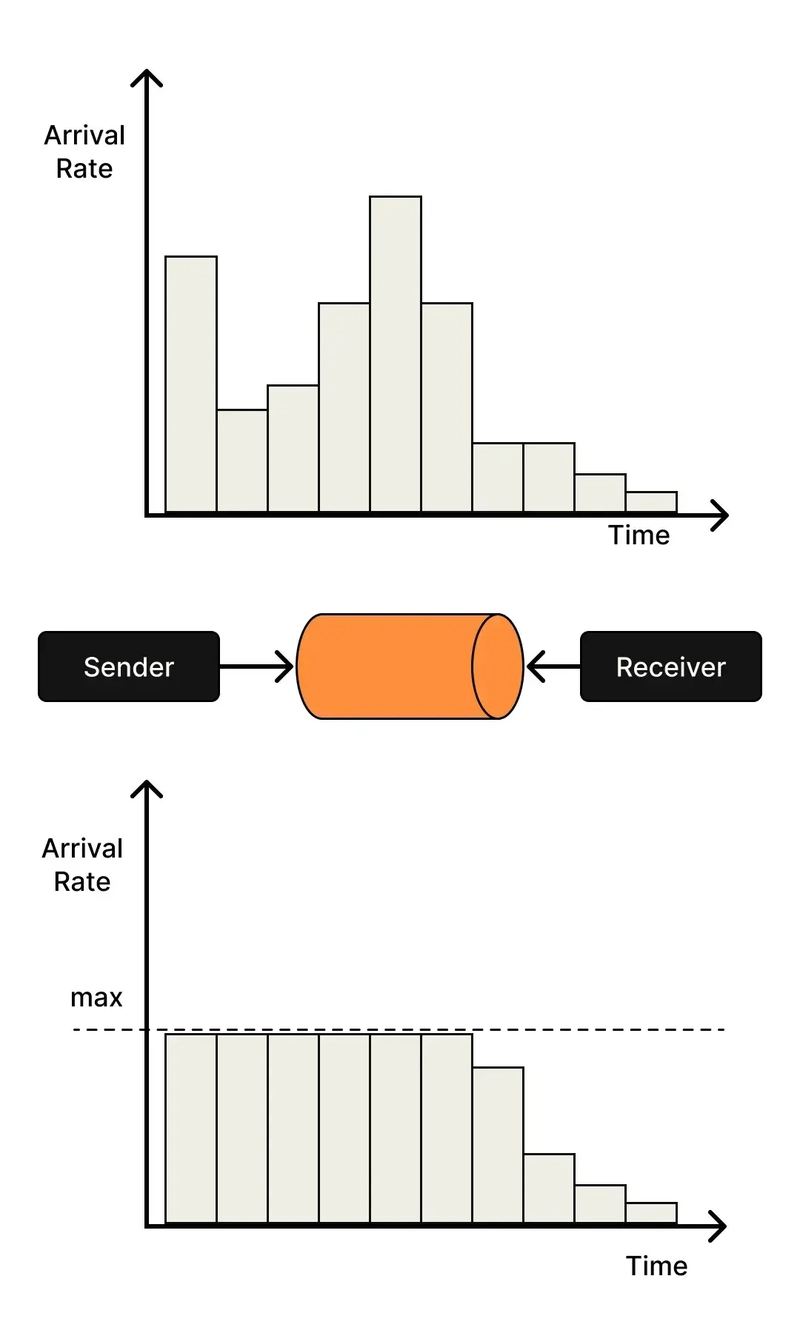
2. Performance Bottlenecks: Keep It Snappy
Channel Missteps
Channels are great, but misuse them and your app crawls. Overly small buffers block too much; oversized ones waste memory. Here’s a pipeline tweak:
type Pipeline struct {
buffer int
}
func (p *Pipeline) Run(data []int) []int {
in := make(chan int, p.buffer)
out := make(chan int, p.buffer)
// Stage 1: Feed data
go func() {
for _, d := range data {
in <- d
}
close(in)
}()
// Stage 2: Process
go func() {
for d := range in {
out <- d * 2
}
close(out)
}()
// Collect
var results []int
for r := range out {
results = append(results, r)
}
return results
}
// Usage
func main() {
p := Pipeline{buffer: 10} // Tune this!
fmt.Println(p.Run([]int{1, 2, 3})) // [2 4 6]
}
The Overhead Trap
Spawning a goroutine per tiny task? That’s overkill—context switching adds up. Batch them instead:
func processBatch(items []Item) {
var wg sync.WaitGroup
chunks := splitIntoChunks(items, 100) // Batch size: 100
for _, chunk := range chunks {
wg.Add(1)
go func(c []Item) {
defer wg.Done()
for _, item := range c {
processItem(item)
}
}(chunk)
}
wg.Wait()
}
Takeaway: Match channel buffers to your workload (start small, test, adjust), and batch tiny tasks to cut goroutine overhead.
VI. Debugging & Monitoring: Taming the Goroutine Beast
When goroutines go rogue—races, leaks, or slowdowns—you need the right tools to track them down. Let’s dive into debugging and monitoring tricks to keep your concurrent Go code in line.
1. Debugging Like a Detective
Catch Races with the Race Detector
Data races are sneaky, but Go’s built-in race detector has your back. Run it with a simple flag:
// Test file: counter_test.go
func TestCounter(t *testing.T) {
counter := 0
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
counter++ // Race detector will scream here
}()
}
wg.Wait()
}
// Run it
// go test -race ./...
Output: It’ll flag any concurrent writes—fix them with a mutex or atomic ops (see the last section!).
Profile with Pprof
Slow app? Use pprof to see where the bottlenecks hide. Add it to your code:
func main() {
// Start pprof server
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
// Your app logic here
for i := 0; i < 1000; i++ {
go func() { time.Sleep(time.Second) }() // Simulate work
}
time.Sleep(10 * time.Second) // Let it run
}
// Profile it
// go tool pprof http://localhost:6060/debug/pprof/profile?seconds=5
Then visualize with go tool pprof -web. You’ll see CPU hogs and memory guzzlers in a snap.
Takeaway: -race catches concurrency bugs; pprof pinpoints performance culprits.
2. Monitoring: Eyes on Your Goroutines
Track Runtime Stats
Want to know how many goroutines are running or how much memory you’re chewing? Tap into runtime:
type Metrics struct {
Goroutines int
HeapMB float64
}
func GetMetrics() Metrics {
var m runtime.MemStats
runtime.ReadMemStats(&m)
return Metrics{
Goroutines: runtime.NumGoroutine(),
HeapMB: float64(m.HeapAlloc) / 1024 / 1024,
}
}
func main() {
go func() {
ticker := time.NewTicker(2 * time.Second)
for range ticker.C {
m := GetMetrics()
fmt.Printf("Goroutines: %d, Heap: %.2f MB\n", m.Goroutines, m.HeapMB)
}
}()
// Spin some goroutines
for i := 0; i < 50; i++ {
go func() { time.Sleep(time.Hour) }()
}
time.Sleep(10 * time.Second)
}
Spot Leaks Early
Goroutines piling up? Could be a leak. Add a simple check:
func watchGoroutines() {
go func() {
for range time.Tick(5 * time.Second) {
if n := runtime.NumGoroutine(); n > 100 {
log.Printf("Warning: %d goroutines running—possible leak?", n)
}
}
}()
}
Takeaway: Log key metrics like goroutine count and heap size—catch leaks before they swamp you.
VII. Best Practices: Your Goroutine Cheat Sheet
You’ve got the tools and tricks—now let’s boil it down to a handy checklist for writing top-notch concurrent Go code. These are the golden rules to keep your goroutines humming.
1. Code Like a Pro
Name Stuff Clearly
Good names save headaches. Stick to Go conventions:
type WorkerPool struct {
maxWorkers int // Private, lowercase
Tasks chan Job // Public, uppercase
}
const (
DefaultTimeout = 30 * time.Second // CamelCase constants
)
Organize Smart
Keep your project tidy:
myapp/
├── cmd/ # Entry points
│ └── main.go
├── internal/ # Private code
│ └── worker/
│ └── pool.go
├── pkg/ # Reusable stuff
│ └── logger/
└── config/ # Settings
└── config.go
Takeaway: Clear names and structure make your code a joy to maintain.
2. Performance Checklist
Before You Launch
Run these checks to avoid launch-day disasters:
func PreLaunchChecks() error {
// Check file descriptors
var rLimit syscall.Rlimit
if err := syscall.Getrlimit(syscall.RLIMIT_NOFILE, &rLimit); err != nil {
return err
}
if rLimit.Cur < 10000 {
return fmt.Errorf("Need more file descriptors: got %d", rLimit.Cur)
}
// Check CPU
if runtime.NumCPU() < 2 {
return errors.New("Need at least 2 cores")
}
return nil
}
func main() {
if err := PreLaunchChecks(); err != nil {
log.Fatal(err)
}
fmt.Println("Ready to roll!")
}
Optimization Must-Dos
- Limit Goroutines: Use pools, not a free-for-all.
- Buffer Channels Right: Small for sync, bigger for bursts.
- Batch Tiny Tasks: Fewer goroutines = less overhead.
- Watch GC: Reuse objects to ease garbage collection pressure.
Takeaway: A quick pre-flight check and smart tuning keep your app fast and stable.
VIII. Keep Learning: Resources & What’s Next for Goroutines
You’re now armed with goroutine know-how, but the journey doesn’t stop here. Here’s where to dig deeper and what to watch for as Go’s concurrency evolves.
1. Level-Up Resources
Must-Read Books
- Concurrency in Go by Katherine Cox-Buday: The go-to for mastering goroutines and channels.
- High-Performance Go: Tips to squeeze every ounce of speed from your code.
Killer Tools
- go-torch: Flame graphs to spot hot spots.
- goleak: Hunt down goroutine leaks.
- Prometheus + Grafana: Monitor your app like a pro.
Takeaway: These goodies will sharpen your skills and toolkit.
2. The Future of Go Concurrency
What’s Cooking?
- Smarter Scheduling: Think NUMA-aware goroutines that play nice with modern hardware.
- Better Tools: Expect slicker debuggers and performance analyzers.
- Ecosystem Growth: More libraries for concurrency patterns and cloud-native apps.
Stay Ahead
Keep an eye on Go’s releases—each one tweaks the runtime and adds goodies. The community’s pushing for tighter integration with distributed systems, so concurrency’s only getting cooler.
Takeaway: Go’s concurrency story is still unfolding—stay plugged in!
3. Final Nuggets of Wisdom
- Don’t Overdo It: Concurrency isn’t a magic bullet—profile first.
- Clean Up: Always handle errors and free resources.
- Measure Twice: Test and monitor to prove your optimizations work.
Wrap-Up: Go Forth and Concurrent!
Goroutines and channels make concurrency in Go a breeze—powerful yet approachable. With the practices we’ve covered, you’re ready to build fast, robust systems that scale. But remember: profile before you parallelize, and keep it simple where you can. The future’s bright for Go concurrency—keep learning, experimenting, and sharing your wins with the community!
What’s your favorite goroutine trick? Drop it in the comments—I’d love to hear!