







































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)

































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)


















![Re-designing a Git/development workflow with best practices [closed]](https://i.postimg.cc/tRvBYcrt/branching-example.jpg)






















































































(1).jpg?#)


















![The Material 3 Expressive redesign of Google Clock leaks out [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/03/Google-Clock-v2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






























































































![What Google Messages features are rolling out [May 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2023/12/google-messages-name-cover.png?resize=1200%2C628&quality=82&strip=all&ssl=1)













![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)


























































































Essential Patterns for Resilient Distributed Systems
Moving from a monolithic architecture to a distributed system introduces complexities that can catch even experienced developers off guard. What seemed like straightforward operations in a single container suddenly become potential points of failure when spread across multiple services. After years of building, scaling, and sometimes painfully debugging distributed systems in production environments, I've collected hard-earned lessons that can help you avoid common pitfalls. This article focuses on practical patterns for service communication, queue implementation, latency management, and failure handling—concepts that become increasingly critical as your system grows. Effective Communication Between Services Microservices communicate with each other using lightweight protocols such as HTTP/REST, gRPC, or message queues. This promotes interoperability and makes it easier to integrate new services or replace existing ones. However, this distributed communication introduces challenges: Network congestion and latency: The use of many small, granular services can result in more interservice communication Long dependency chains: If the chain of service dependencies gets too long (service A calls B, which calls C...), the additional latency can become a problem Service resilience: If any component crashes during processing, requests can be lost You will need to design APIs carefully to address these challenges. Avoid overly chatty APIs, think about serialization formats, and look for places to use asynchronous communication patterns like queue-based load leveling. The Critical Role of Queues Once you've broken down your architecture from a single container to 2+ containers, that's usually the time to introduce queues between service calls. Queues help services to handle spikes in traffic that would otherwise overwhelm your systems. Without queues, traffic bursts that hit a service directly will cause the service to accept all requests until it fails catastrophically. A queue creates back-pressure, while also buying us time to auto-scale services. In a microservice architecture, it is common to forward non-latency-critical requests to message queues. This decouples the latency-critical portion of the application from those that could be processed asynchronously. Commands may be placed on a queue for asynchronous processing, rather than being processed synchronously. Implementation Examples Popular queue technologies include: Apache Kafka - Excellent for high-throughput event streaming RabbitMQ - Great for traditional message queuing with complex routing AWS SQS - Simple managed queuing service with minimal configuration Google Pub/Sub - Scalable event ingestion and delivery system Ensuring Message Delivery If any of the components crashes before successfully processing and handing over the event to its next component, then the event is dropped and never makes it into the final destination. To minimize the chance of data loss, persist in-transit events and remove or dequeue the events only when the next component has acknowledged the receipt of the event. These features are usually known as client acknowledge mode and last participant support. Understanding Latency in Distributed Systems Latency is the duration that a request is waiting to be handled. Until the request is handled, it is latent - inactive or dormant. A high latency indicates problems in the networking or that the server cannot handle a series of requests and is probably overloaded. Our goal is to have the lowest latency possible. Caching is a great tool when you want to improve request latency or reduce costs. But without giving enough thought when introducing cache, it can set your service up for disaster. Latency is typically defined as the amount of time needed for a package to be transferred across the network. This time includes: Network overhead Processing time Latency and response time are often used synonymously, but they are not the same: The response time is what the client sees: besides the actual time to process the request (the service time), it includes network delays and queueing delays. Latency is the duration that a request is waiting to be handled—during which it is latent, awaiting service. The question you answer when you talk about latency is: "How fast?" How fast the request can be made How fast can you get your resource or data from the server Queueing Latency In distributed systems, queueing latency is an often-overlooked component of the total time a request takes. As messages wait in queues to be processed, this waiting time adds to the overall latency experienced by users. Monitor queue depth and processing rate to ensure this doesn't become a bottleneck. Low Latency in Cache Achieving low latency in caching systems often involves pre-established connections: Cache clients maintain a pool of open connections to
Moving from a monolithic architecture to a distributed system introduces complexities that can catch even experienced developers off guard. What seemed like straightforward operations in a single container suddenly become potential points of failure when spread across multiple services.
After years of building, scaling, and sometimes painfully debugging distributed systems in production environments, I've collected hard-earned lessons that can help you avoid common pitfalls. This article focuses on practical patterns for service communication, queue implementation, latency management, and failure handling—concepts that become increasingly critical as your system grows.
Effective Communication Between Services
Microservices communicate with each other using lightweight protocols such as HTTP/REST, gRPC, or message queues. This promotes interoperability and makes it easier to integrate new services or replace existing ones.
However, this distributed communication introduces challenges:
- Network congestion and latency: The use of many small, granular services can result in more interservice communication
- Long dependency chains: If the chain of service dependencies gets too long (service A calls B, which calls C...), the additional latency can become a problem
- Service resilience: If any component crashes during processing, requests can be lost
You will need to design APIs carefully to address these challenges. Avoid overly chatty APIs, think about serialization formats, and look for places to use asynchronous communication patterns like queue-based load leveling.
The Critical Role of Queues
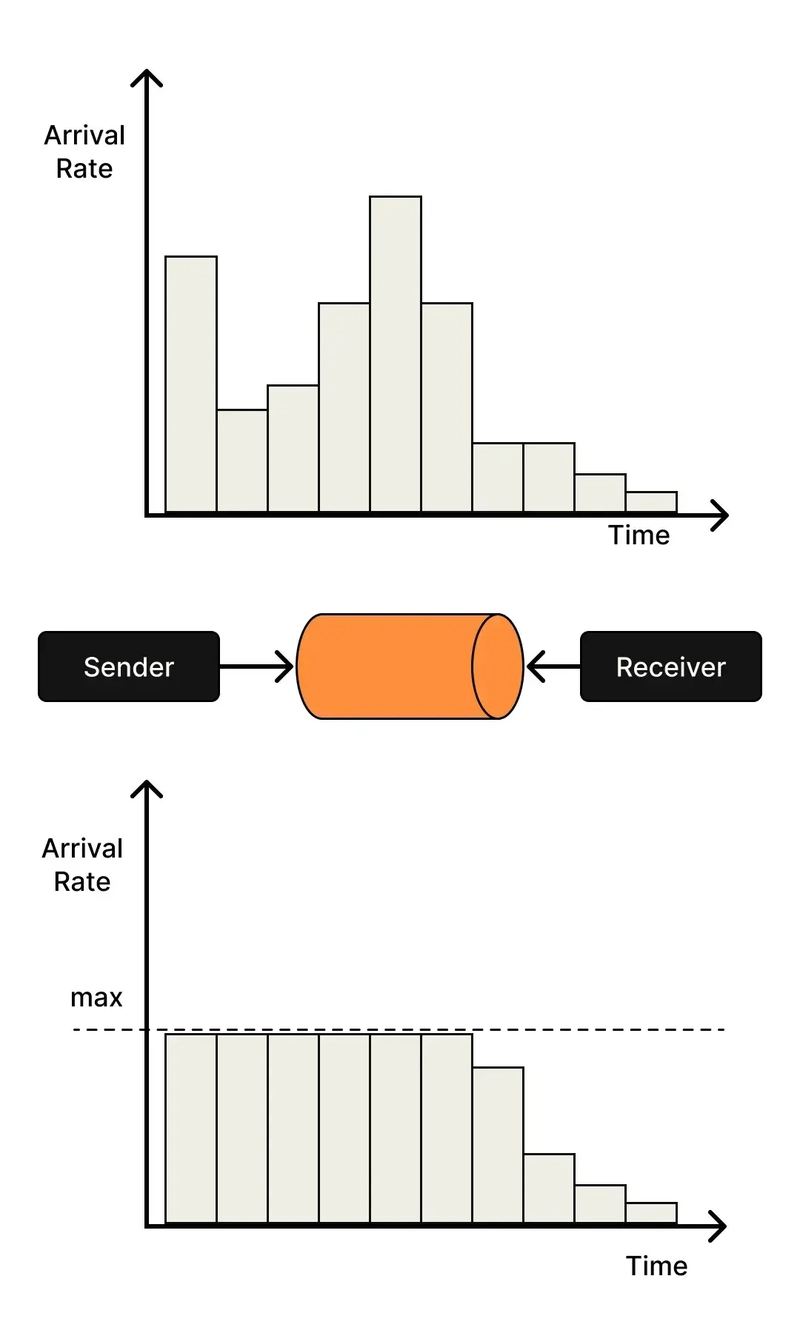
Once you've broken down your architecture from a single container to 2+ containers, that's usually the time to introduce queues between service calls. Queues help services to handle spikes in traffic that would otherwise overwhelm your systems.
Without queues, traffic bursts that hit a service directly will cause the service to accept all requests until it fails catastrophically. A queue creates back-pressure, while also buying us time to auto-scale services.
In a microservice architecture, it is common to forward non-latency-critical requests to message queues. This decouples the latency-critical portion of the application from those that could be processed asynchronously. Commands may be placed on a queue for asynchronous processing, rather than being processed synchronously.
Implementation Examples
Popular queue technologies include:
- Apache Kafka - Excellent for high-throughput event streaming
- RabbitMQ - Great for traditional message queuing with complex routing
- AWS SQS - Simple managed queuing service with minimal configuration
- Google Pub/Sub - Scalable event ingestion and delivery system
Ensuring Message Delivery
If any of the components crashes before successfully processing and handing over the event to its next component, then the event is dropped and never makes it into the final destination. To minimize the chance of data loss, persist in-transit events and remove or dequeue the events only when the next component has acknowledged the receipt of the event. These features are usually known as client acknowledge mode and last participant support.
Understanding Latency in Distributed Systems
Latency is the duration that a request is waiting to be handled. Until the request is handled, it is latent - inactive or dormant. A high latency indicates problems in the networking or that the server cannot handle a series of requests and is probably overloaded. Our goal is to have the lowest latency possible.
Caching is a great tool when you want to improve request latency or reduce costs. But without giving enough thought when introducing cache, it can set your service up for disaster.
Latency is typically defined as the amount of time needed for a package to be transferred across the network. This time includes:
- Network overhead
- Processing time
Latency and response time are often used synonymously, but they are not the same:
- The response time is what the client sees: besides the actual time to process the request (the service time), it includes network delays and queueing delays.
- Latency is the duration that a request is waiting to be handled—during which it is latent, awaiting service.
The question you answer when you talk about latency is: "How fast?"
- How fast the request can be made
- How fast can you get your resource or data from the server
Queueing Latency
In distributed systems, queueing latency is an often-overlooked component of the total time a request takes. As messages wait in queues to be processed, this waiting time adds to the overall latency experienced by users. Monitor queue depth and processing rate to ensure this doesn't become a bottleneck.
Low Latency in Cache
Achieving low latency in caching systems often involves pre-established connections:
- Cache clients maintain a pool of open connections to the cache servers
- When the application needs to make a cache request, it borrows a connection from the pool instead of establishing a new TCP one
- This is because a TCP handshake could nearly double the cache response times. Borrowing the connection avoids the overhead of the TCP handshake on each request.
- Keeping connections open consumes memory and other resources on both the client and server
- Therefore, it's important to carefully tune the number of connections to balance resource usage with the ability to handle traffic spikes.
Response Time
Response time is the total time it takes for the web service to respond to the sent request, including all networking latencies. Response time is the sum of processing time and encountered latencies.
Processing time is usually the time taken by the server from receiving the last byte of the request and returning the first byte of the response. It does not include the time it takes the request to get from the client to the server or the time it takes to get from the server back to the client.
If we are talking about an API, the server usually does not start processing until it receives and reads all the bytes from the request. Since the server needs to parse it and understand how it can satisfy it, once it started to render the response (sent the first byte), it does not control the network latency.
Design for Failure
Network failures, rate limiting, downstream service crashes—there are countless ways your services can fail in a distributed environment. You should expect these failures and build systems that handle them gracefully:
- Create retry policies for API calls to handle transient exceptions
- Implement circuit breakers to stop calling failing services until they recover
- Use dead-letter queues to isolate persistently failing messages for investigation
Remember that in distributed systems, failure isn't exceptional—it's inevitable. Your architecture should treat failures as normal occurrences rather than edge cases.
Circuit Breaker Pattern Example
Here's a naive implementation of a circuit breaker middleware for Hono in Node.js (don't use in production, it's just for conceptual understanding):
import { Hono } from 'hono';
import { HTTPException } from 'hono/http-exception';
// Circuit Breaker Middleware
const circuitBreaker = (options = {}) => {
const {
failureThreshold = 5,
resetTimeout = 30000,
fallbackResponse = { error: 'Service unavailable' },
statusCode = 503
} = options;
// Shared state between all requests
const state = {
failureCount: 0,
status: 'CLOSED', // CLOSED, OPEN, HALF-OPEN
lastFailureTime: null
};
return async (c, next) => {
// Check if circuit is OPEN
if (state.status === 'OPEN') {
// Check if reset timeout has elapsed
if (Date.now() - state.lastFailureTime > resetTimeout) {
// Move to HALF-OPEN state to test if the system has recovered
state.status = 'HALF-OPEN';
console.log('Circuit moved to HALF-OPEN state');
} else {
// Circuit is OPEN - return fallback response
console.log('Circuit OPEN - returning fallback response');
return c.json(fallbackResponse, statusCode);
}
}
try {
// Attempt to process the request
await next();
// Request succeeded - reset failure count if in HALF-OPEN
if (state.status === 'HALF-OPEN') {
state.status = 'CLOSED';
state.failureCount = 0;
console.log('Circuit returned to CLOSED state');
}
} catch (error) {
// Request failed - increment failure count
state.failureCount++;
state.lastFailureTime = Date.now();
// Check if we should OPEN the circuit
if (state.failureCount >= failureThreshold || state.status === 'HALF-OPEN') {
state.status = 'OPEN';
console.log(`Circuit OPENED after ${state.failureCount} failures`);
}
// Re-throw the error for further handling
throw error;
}
};
};
Example of usage:
// Example usage in a Hono app
const app = new Hono();
// Apply circuit breaker to a route that calls an external service
app.get('/api/external-data',
circuitBreaker({
failureThreshold: 3,
resetTimeout: 10000
}),
async (c) => {
try {
// Call to external service that might fail
const response = await fetch('https://external-api.example.com/data');
if (!response.ok) {
throw new HTTPException(response.status, { message: 'External API error' });
}
const data = await response.json();
return c.json(data);
} catch (error) {
// Let the circuit breaker middleware handle the error
throw new HTTPException(503, { message: 'Service temporarily unavailable' });
}
}
);
// Apply circuit breaker to a whole group of routes
const apiGroup = new Hono()
.use('/*', circuitBreaker())
.get('/users', (c) => c.json({ users: [] }))
.get('/products', (c) => c.json({ products: [] }));
app.route('/api', apiGroup);
export default app;
This implementation provides a middleware-based approach that works well with Hono's architecture and modern Node.js applications. It tracks failures across all requests to protected routes and automatically recovers by testing connections after the specified timeout.
Design for Idempotency
Message queues typically guarantee "at least once" delivery, which means duplicates are expected. If your consumers aren't idempotent, you'll process the same events multiple times—potentially charging customers twice or creating duplicate records.
Relying on "exactly once" delivery is a recipe for inconsistency. You need to assume duplicates will happen and handle them gracefully through techniques like:
- Using unique transaction IDs to detect and skip duplicate processing
- Designing database operations that won't cause problems when repeated
- Implementing compensation mechanisms for non-idempotent operations
I once had to debug a nasty bug in an AWS Lambda function that wasn't idempotent, and it was a tremendous pain to track down and fix. The lesson was clear: build idempotency into your services from day one.
Finding the Right Balance in System Architecture
We often hear about over-architected systems. This often occurs when we try to plan for every possible scenario that could ever occur through the life of an application. To try and support every conceivable use is a fool's errand. When we try to build these systems we add unnecessary complexity and often make development harder, rather than easier.
At the same time, we don't want to build a system that offers no flexibility at all. It may be faster to just build it without future thought, but adding new features can be just as time consuming later on. Trying to find the right balance is the hardest part of application architecture. We want to create a flexible application that allows growth but we don't want to waste time on all possibilities.
The principles I've outlined above shouldn't be interpreted as a call to over-engineer your systems from day one. Rather, they represent pragmatic patterns that address real problems you'll encounter as you scale distributed systems. The art lies in knowing when to apply them.
Conclusion
Building distributed systems at scale requires a different mindset than developing monolithic applications. By implementing effective service communication, using queues between services, optimizing latency, designing for failure, and ensuring idempotency, you can create resilient systems that stand up to the challenges of production environments.



