








































































































































































![[The AI Show Episode 147]: OpenAI Abandons For-Profit Plan, AI College Cheating Epidemic, Apple Says AI Will Replace Search Engines & HubSpot’s AI-First Scorecard](https://www.marketingaiinstitute.com/hubfs/ep%20147%20cover.png)































































































































































































































































_Gang_Liu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































![Review: Sonnet Echo 13 Thunderbolt 5 SSD Dock – 140W MacBook charging, 2.5GbE, up to 6000 MB/s SSD speed [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/Sonnet-Echo-13-Thunderbolt-5-SSD-Dock-Review-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

















![Apple Planning Bezel-Free iPhone With 'Four-Sided Bending' Display [Report]](https://www.iclarified.com/images/news/97321/97321/97321-640.jpg)

![Apple Working on Brain-Controlled iPhone With Synchron [Report]](https://www.iclarified.com/images/news/97312/97312/97312-640.jpg)



























































































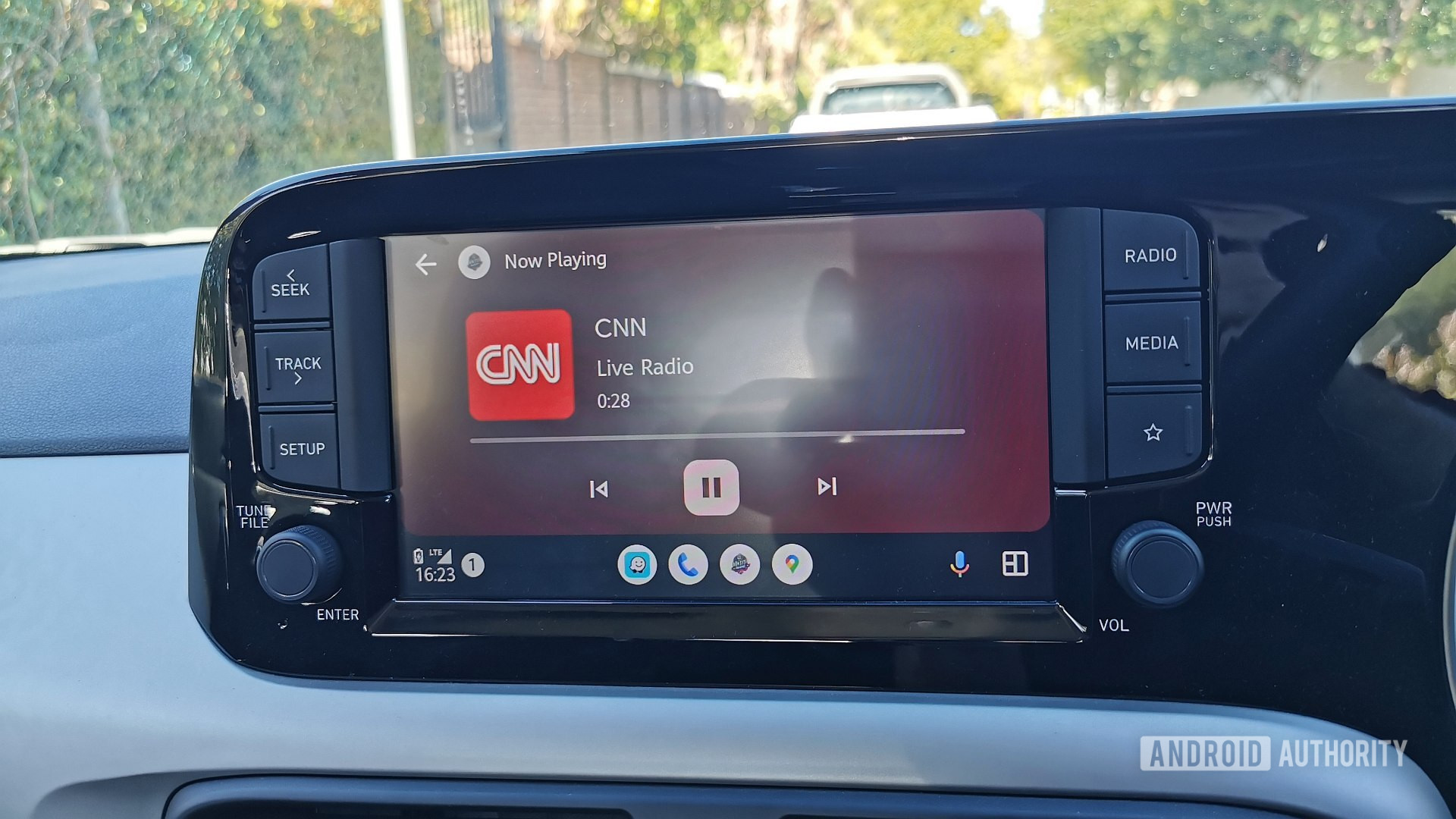
How YouTube handles downloading video
One thing I’ve always been curious about regarding YouTube Premium is how you can download videos and access them offline. But YouTube doesn’t just hand you an .mp4 or similar file. Instead, you need to log in again, head to your downloads section, and access them from there. The big question is: where are these videos stored? How is the storage done? And more interestingly, how can we implement a (much simpler) version of this ourselves? Let’s break it down into a few simple steps: Splitting the video into smaller chunks for better storage and streaming Storing the chunks in IndexedDB — with some encoding and extras Retrieving and playing the video offline (after decryption and some more extras) That’s it! The Core Mechanism YouTube is hands down one of the most badass services out there. Explaining what’s happening behind the scenes (not even counting the algorithm and monetization side) is really difficult. But here’s the simplified version: A content creator uploads a video — let’s say in 4K quality. YouTube’s internal services automatically convert that video into multiple qualities and store them somewhere (we don’t know exactly where). So although the original was uploaded in high quality, lower-quality versions are also saved. That makes sense — different devices, bandwidths, and user conditions. Once it’s stored, users can access it. When you play a video, you’ve probably noticed that a portion ahead of where you’re watching is already downloaded (or better yet, buffered). YouTube follows a few rules here: Even if the video is ~54 minutes long, it doesn’t buffer the whole thing. If you’re watching at minute 2, buffering till minute 40 is unnecessary — it may only buffer up to minute 6. This prevents wasting resources and allows flexible streaming based on connection quality. This logic also works great for live streams. To provide the best user experience, YouTube breaks videos into much smaller chunks. I don’t know the exact logic — maybe a 1-hour video becomes 60 one-minute chunks or 120 thirty-second chunks, or even depends on size/length. But this chunking definitely happens, and we’ll replicate that later. Also, we can’t just pass an MP4 file to a tag and call it a day. If we’re streaming in chunks, we need a way to feed these into the player. This is where the MediaSource API comes in (which YouTube uses too). It gives us full control over playback, allows us to dynamically push video chunks, adjust bitrate, etc. So far, we’ve outlined a simplified view of YouTube’s logic. (These are my findings — happy to hear yours too!) The vision We’re not YouTube, but we’re curious enough to build something similar. We won’t deal with video streaming here. We’ll focus solely on when a Premium user downloads a video completely for offline use. But as you know, YouTube doesn’t give you a downloadable MP4. Instead, it stores the video (encrypted) in something like IndexedDB. Videos are chunked and stored in IndexedDB, which supports storing Blobs and ArrayBuffers — perfect for saving video data. When it’s time to play the video, these chunks are aggregated using a reduce function and played into a tag or more advance MediaSource. const chunk = { videoId: "Prince Rouge", chunkIndex: 5, quality: "720p", data: Blob // or ArrayBuffer } Later, to replay the video, this ArrayBuffer or Blob will be reassembled, and fed into the MediaSource. Note that here, the chunkIndex is 5, meaning this is the fifth chunk out of n total chunks of the full video. Why these tools? Why IndexedDB? For browser-side storage, we have: localStorage — limited to ~5MB sessionStorage — also small, not shared across tabs cookies — meant for other use cases That leaves IndexedDB as the only viable choice for large binary storage. Why Blob & ArrayBuffer? You need to deal with file objects — that’s where Blob comes in. ArrayBuffer acts as a bridge (not exactly but similar) between Blob and MediaSource. You convert a blob to buffer, then feed it to MediaSource or . const res = await fetch('video.mp4'); const blob = await res.blob(); // And later const reader = new FileReader(); reader.readAsArrayBuffer(blob); Why MediaSource? The basic tag only works with a complete file URL. But with MediaSource, we can: Add video data chunk by chunk Buffer dynamically Load from memory (or disk), workers, databases Stream in real time Build fully custom video players const mediaSource = new MediaSource(); video.src = URL.createObjectURL(mediaSource); mediaSource.addEventListener("sourceopen", () => { const sourceBuffer = mediaSource.addSourceBuffer('video/mp4; codecs="avc1.42E01E"'); // Append chunks manually fetchChunk().then((chunk) => { sourceBuffer.appendBuffer(chunk); }); }); That's it. Orchestration — Putting It All Together You can see a full sample app Here — it’s bootstrapped with Vite. To keep it simple: The user

One thing I’ve always been curious about regarding YouTube Premium is how you can download videos and access them offline. But YouTube doesn’t just hand you an .mp4 or similar file. Instead, you need to log in again, head to your downloads section, and access them from there.
The big question is: where are these videos stored? How is the storage done? And more interestingly, how can we implement a (much simpler) version of this ourselves?
Let’s break it down into a few simple steps:
- Splitting the video into smaller chunks for better storage and streaming
- Storing the chunks in IndexedDB — with some encoding and extras
- Retrieving and playing the video offline (after decryption and some more extras)
That’s it!
The Core Mechanism
YouTube is hands down one of the most badass services out there. Explaining what’s happening behind the scenes (not even counting the algorithm and monetization side) is really difficult. But here’s the simplified version:
A content creator uploads a video — let’s say in 4K quality. YouTube’s internal services automatically convert that video into multiple qualities and store them somewhere (we don’t know exactly where). So although the original was uploaded in high quality, lower-quality versions are also saved. That makes sense — different devices, bandwidths, and user conditions.
Once it’s stored, users can access it. When you play a video, you’ve probably noticed that a portion ahead of where you’re watching is already downloaded (or better yet, buffered).
YouTube follows a few rules here:
- Even if the video is ~54 minutes long, it doesn’t buffer the whole thing.
- If you’re watching at minute 2, buffering till minute 40 is unnecessary — it may only buffer up to minute 6.
- This prevents wasting resources and allows flexible streaming based on connection quality.
- This logic also works great for live streams.
To provide the best user experience, YouTube breaks videos into much smaller chunks. I don’t know the exact logic — maybe a 1-hour video becomes 60 one-minute chunks or 120 thirty-second chunks, or even depends on size/length. But this chunking definitely happens, and we’ll replicate that later.
Also, we can’t just pass an MP4 file to a tag and call it a day. If we’re streaming in chunks, we need a way to feed these into the player. This is where the MediaSource API comes in (which YouTube uses too). It gives us full control over playback, allows us to dynamically push video chunks, adjust bitrate, etc.
So far, we’ve outlined a simplified view of YouTube’s logic. (These are my findings — happy to hear yours too!)
The vision
We’re not YouTube, but we’re curious enough to build something similar.
We won’t deal with video streaming here. We’ll focus solely on when a Premium user downloads a video completely for offline use. But as you know, YouTube doesn’t give you a downloadable MP4. Instead, it stores the video (encrypted) in something like IndexedDB.

Videos are chunked and stored in IndexedDB, which supports storing Blobs and ArrayBuffers — perfect for saving video data.
When it’s time to play the video, these chunks are aggregated using a reduce function and played into a tag or more advance MediaSource.
const chunk = {
videoId: "Prince Rouge",
chunkIndex: 5,
quality: "720p",
data: Blob // or ArrayBuffer
}
Later, to replay the video, this ArrayBuffer or Blob will be reassembled, and fed into the MediaSource. Note that here, the chunkIndex is 5, meaning this is the fifth chunk out of n total chunks of the full video.
Why these tools?
Why IndexedDB?
For browser-side storage, we have:
-
localStorage— limited to ~5MB -
sessionStorage— also small, not shared across tabs -
cookies— meant for other use cases
That leaves IndexedDB as the only viable choice for large binary storage.
Why Blob & ArrayBuffer?
You need to deal with file objects — that’s where Blob comes in.
ArrayBuffer acts as a bridge (not exactly but similar) between Blob and MediaSource. You convert a blob to buffer, then feed it to MediaSource or .
const res = await fetch('video.mp4');
const blob = await res.blob();
// And later
const reader = new FileReader();
reader.readAsArrayBuffer(blob);
Why MediaSource?
The basic tag only works with a complete file URL. But with MediaSource, we can:
- Add video data chunk by chunk
- Buffer dynamically
- Load from memory (or disk), workers, databases
- Stream in real time
- Build fully custom video players
const mediaSource = new MediaSource();
video.src = URL.createObjectURL(mediaSource);
mediaSource.addEventListener("sourceopen", () => {
const sourceBuffer = mediaSource.addSourceBuffer('video/mp4; codecs="avc1.42E01E"');
// Append chunks manually
fetchChunk().then((chunk) => {
sourceBuffer.appendBuffer(chunk);
});
});
That's it.
Orchestration — Putting It All Together
You can see a full sample app Here — it’s bootstrapped with Vite.

To keep it simple:
- The user selects a video (they don’t upload it, we just store it into the internal browser db)
- We split it into 1MB chunks
- Save each chunk in
IndexedDBwith a key - Reconstruct and play it using
Steps:
- Build UI (Tailwind-based, so skipping details)
- Chunk the video
- Save to
IndexedDB - Retrieve and feed to
on play - (Optional) Remove from IndexedDB
There’s also a debug button to show database content using a tag (or check Application tab in DevTools).
Chunking
We have a function that reads the file from input, turns it into ArrayBuffer, and slices it into 1MB chunks. A simple while loop handles the chunking.
const arrayBuffer = await videoFile.arrayBuffer();
const chunkSize = 1024 * 1024; // 1MB chunks
const chunks = [];
let offset = 0;
while (offset < arrayBuffer.byteLength) {
const size = Math.min(chunkSize, arrayBuffer.byteLength - offset);
const chunk = arrayBuffer.slice(offset, offset + size);
chunks.push(chunk);
offset += size;
}
Storing
We split the video into:
- Metadata (e.g. filename, size, total chunks)
- Actual chunks
Here's the sample of a metadata object:
const metadata = {
id: videoId,
title: videoFile.name,
mimeType: videoFile.type,
size: arrayBuffer.byteLength,
chunkCount: chunks.length, // this is important
dateAdded: new Date().toISOString()
};
Now we get to the part where we store data in IndexedDB. Here, you can either use an ORM-like library such as idb, or work with it directly. Since we’re not launching Apollo here, I chose not to use any library.
First, we need to create a database, and then reuse that same instance to run queries on it — whether it's saving data, reading, deleting, or anything else.
let dbInstance = null;
// Initialize the database once and store the connection
const initDB = () => {
return new Promise((resolve, reject) => {
if (dbInstance) {
// Using existing database connection
resolve(dbInstance);
return;
}
const request = indexedDB.open('VideoStorageDB', 1);
request.onerror = (event) => {
console.error("IndexedDB error:", event.target.error);
reject(event.target.error);
};
request.onupgradeneeded = (event) => {
// Upgrading database schema
const db = event.target.result;
// Create the metadata store
if (!db.objectStoreNames.contains('metadata')) {
db.createObjectStore('metadata', { keyPath: 'id' });
}
// Create the chunks store
if (!db.objectStoreNames.contains('chunks')) {
db.createObjectStore('chunks', { keyPath: 'id' });
}
};
request.onsuccess = (event) => {
dbInstance = event.target.result;
// Handle connection errors
dbInstance.onerror = (event) => {
console.error("Database error:", event.target.error);
};
resolve(dbInstance);
};
});
};
We use a simple singleton pattern to initialize and reuse the database instance.
const storeCompleteVideo = async (metadata, chunks) => {
try {
const db = await initDB();
return new Promise((resolve, reject) => {
const transaction = db.transaction(['metadata', 'chunks'], 'readwrite');
transaction.onerror = (event) => {
reject(event.target.error);
};
transaction.oncomplete = () => {
console.log(`Video ${metadata.id} stored successfully with all ${chunks.length} chunks`);
resolve(metadata);
};
const metadataStore = transaction.objectStore('metadata');
const chunksStore = transaction.objectStore('chunks');
// INJA 1
metadataStore.put(metadata);
// INJA 2
for (let i = 0; i < chunks.length; i++) {
const chunkData = {
id: `${metadata.id}_chunk_${i}`,
videoId: metadata.id,
chunkIndex: i,
data: chunks[i] // ArrayBuffer chunk
};
chunksStore.put(chunkData);
}
});
} catch (error) {
console.error('Error storing video:', error);
throw error;
}
};
Alright, in the code, I marked two spots with comments: INJA1 and INJA2 (I always debug using this word


