










































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)




























































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)


































































































































_Piotr_Adamowicz_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)














































































-xl-xl-xl.jpg)










![Walmart’s $30 Google TV streamer is now in stores and it supports USB-C hubs [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/onn-4k-plus-store-reddit.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple to Launch AI-Powered Battery Saver Mode in iOS 19 [Report]](https://www.iclarified.com/images/news/97309/97309/97309-1280.jpg)

![Apple Officially Releases macOS Sequoia 15.5 [Download]](https://www.iclarified.com/images/news/97308/97308/97308-640.jpg)























































































How to Automate Compliance and Fraud Detection in Finance with MLOps
These days, businesses are under increasing pressure to comply with stringent regulations while also combating fraudulent activities. The high volume of data and the intricate requirements of real-time fraud detection and compliance reporting are fre...

These days, businesses are under increasing pressure to comply with stringent regulations while also combating fraudulent activities. The high volume of data and the intricate requirements of real-time fraud detection and compliance reporting are frequently a challenge for traditional systems to manage.
This is where MLOps (Machine Learning Operations) comes into play. It can help teams streamline these processes and elevate automation to the forefront of financial security and regulatory adherence.
In this article, we will investigate the potential of MLOps for automating compliance and fraud detection in the finance sector.
I’ll show you step by step how financial institutions can deploy a machine learning model for fraud detection and integrate it into their operations to ensure continuous monitoring and automated alerts for compliance. I’ll also demonstrate how to deploy this solution in a cloud-based environment using Google Colab, ensuring that it is both user-friendly and accessible, whether you are a beginner or more advanced.
Here’s what we’ll cover:
What is MLOps?
Machine Learning Operations, or MLOps for short, is a methodology that integrates DevOps with Machine Learning (ML). The whole machine learning model lifecycle, including development, training, deployment, monitoring, and maintenance, can be automated with its help.
MLOps has several main goals: continuous optimization, scalability, and the delivery of operational value over time.
The financial industry provides great use cases for MLOps processes and techniques, as these can help businesses manage complicated data pipelines, deploy models in real-time, and evaluate their performance – all while making sure they're compliant with regulations.
Why is MLOps Important in Finance?
Financial institutions are subject to various rules including Anti-Money Laundering (AML), Know Your Customer (KYC), and Fraud Prevention Regulations – so they have to carefully manage private information. Ignoring these rules might result in severe fines and loss of reputation.
Detecting fraud in financial transactions also calls for advanced systems capable of real-time identification of suspicious activity.
MLOps can help to solve these issues in the following ways:
MLOps lets financial institutions automatically track transactions for regulatory compliance, guaranteeing they follow changing legislation.
MLOps helps to create and implement machine learning models that can identify fraudulent transactions in real-time.
MLOps runs automated processes, enabling organizations to expand their fraud detection systems with as little human involvement as possible through automation.
What You’ll Need:
To follow along with this tutorial, ensure that you have the following:
Python installed, along with basic ML libraries such as scikit-learn, Pandas, and NumPy.
A sample dataset of financial transactions, which we will use to train a fraud detection model (You can use this sample dataset if you don’t have one on hand).
Google Colab (for cloud-based execution), which is free to use and doesn't require installation.
Step 1: Set Up Google Colab and Prepare the Data
Google Colab is an ideal choice for beginners and advanced users alike, because it’s cloud-based and doesn’t require installation. To start get started using it, follow these steps:
Access Google Colab:
Visit Google Colab and sign-in with your Google account.
Create a New Notebook:
In the Colab interface, go to File and then select New Notebook to create a fresh notebook.
Import Libraries and Load the Dataset
Now, let’s import the necessary libraries and load our fraud detection dataset. We'll assume the dataset is available as a CSV file, and we'll upload it to Colab.
Import libraries:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
Upload the Dataset:
from google.colab import files
uploaded = files.upload()
# Load dataset into pandas DataFrame
data = pd.read_csv('data.csv')
print(data.head())
Step 2: Data Preprocessing
Data preprocessing is essential to prepare the dataset for model training. This involves handling missing values, encoding categorical variables, and normalizing numerical features.
Why is Preprocessing Important?
Data preprocessing lets you take care of various data issues that could affect your results. During this process, you’ll:
Handle missing values: Financial datasets often have missing values. Filling in these missing values (for example, with the median) ensures that the model doesn’t encounter errors during training.
Convert categorical data: Machine learning algorithms require numerical input, so categorical features (like transaction type or location) need to be converted into numeric format using one-hot encoding.
Normalize data: Some machine learning models, like Random Forest, are not sensitive to feature scaling, but normalization helps maintain consistency and allows us to compare the importance of different features. This step is especially critical for models that rely on gradient descent.
Here’s an example:
# Handle missing data by filling with the median value for each column
data.fillna(data.median(), inplace=True)
# Convert categorical columns to numeric using one-hot encoding
data = pd.get_dummies(data, drop_first=True)
# Normalize numerical columns for scaling
data['normalized_amount'] = (data['Amount'] - data['Amount'].mean()) / data['Amount'].std()
# Separate features and target variable
X = data.drop(columns=['Class'])
y = data['Class']
# Split data into training and testing sets (80% train, 20% test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("Data preprocessing completed.")
Step 3: Train a Fraud Detection Model
We'll now train a RandomForestClassifier and evaluate its performance.
What is a Random Forest Classifier?
A Random Forest is an ensemble learning method that creates a collection (forest) of decision trees, typically trained with different parts of the data. It aggregates their predictions to improve accuracy and reduce overfitting.
This method is a popular choice for fraud detection because it can handle high-dimensional data. It’s also quite robust against overfitting.
Here’s how you can implement the Random Forest Classifier:
# Initialize the Random Forest Classifier
rf_model = RandomForestClassifier(n_estimators=150, random_state=42)
# Train the model on the training data
rf_model.fit(X_train, y_train)
# Predict on the test data
y_pred = rf_model.predict(X_test)
# Evaluate model performance
print("Model Evaluation:\n", classification_report(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
# Plot confusion matrix for visual understanding
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots()
cax = ax.matshow(cm, cmap='Blues')
fig.colorbar(cax)
plt.title("Confusion Matrix")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()
How the model is evaluated:
Classification report: Shows metrics like precision, recall, and F1-score for the fraud and non-fraud classes.
Confusion matrix: Helps visualize the performance of the model by showing the true positives, false positives, true negatives, and false negatives.
Step 4: Retrain the Model with New Data
Once you have trained your model, it’s important to retrain it periodically with new data to ensure that it continues to detect emerging fraud patterns.
What is Retraining?
Retraining the model ensures that it adapts to new, unseen data and improves over time. In the case of fraud detection, retraining is crucial because fraud tactics evolve over time, and your model needs to stay up-to-date to recognize new patterns.
Here’s how you can do this:
# Simulate loading new fraud data
new_data = pd.read_csv('new_fraud_data.csv')
# Apply preprocessing steps to new data (like filling missing values, encoding, normalization)
new_data.fillna(new_data.median(), inplace=True)
new_data = pd.get_dummies(new_data, drop_first=True)
new_data['normalized_amount'] = (new_data['transaction_amount'] - new_data['transaction_amount'].mean()) / new_data['transaction_amount'].std()
# Concatenate old and new data for retraining
X_new = new_data.drop(columns=['fraud_label'])
y_new = new_data['fraud_label']
# Retrain the model with the updated dataset
X_combined = pd.concat([X_train, X_new], axis=0)
y_combined = pd.concat([y_train, y_new], axis=0)
rf_model.fit(X_combined, y_combined)
# Re-evaluate the model
y_pred_new = rf_model.predict(X_test)
print("Updated Model Evaluation:\n", classification_report(y_test, y_pred_new))
Step 5: Automated Alert System
To automate fraud detection, we’ll send an email whenever a suspicious transaction is detected.
How the Alert System Works
The email alert system uses SMTP to send an email whenever fraud is detected. When the model identifies a suspicious transaction, it triggers an automated alert to notify the compliance team for further investigation.
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
# Function to send an email alert
def send_alert(email_subject, email_body):
sender_email = "your_email@example.com"
receiver_email = "compliance_team@example.com"
password = "your_password"
msg = MIMEMultipart()
msg['From'] = sender_email
msg['To'] = receiver_email
msg['Subject'] = email_subject
msg.attach(MIMEText(email_body, 'plain'))
# Send email using SMTP
try:
server = smtplib.SMTP_SSL('smtp.example.com', 465)
server.login(sender_email, password)
text = msg.as_string()
server.sendmail(sender_email, receiver_email, text)
server.quit()
print("Fraud alert email sent successfully.")
except Exception as e:
print(f"Failed to send email: {str(e)}")
# Example: Check for fraud and trigger an alert
suspicious_transaction_details = "Transaction ID: 12345, Amount: $5000, Suspicious Activity Detected."
send_alert("Fraud Detection Alert", f"A suspicious transaction has been detected: {suspicious_transaction_details}")
Step 6: Visualize Model Performance
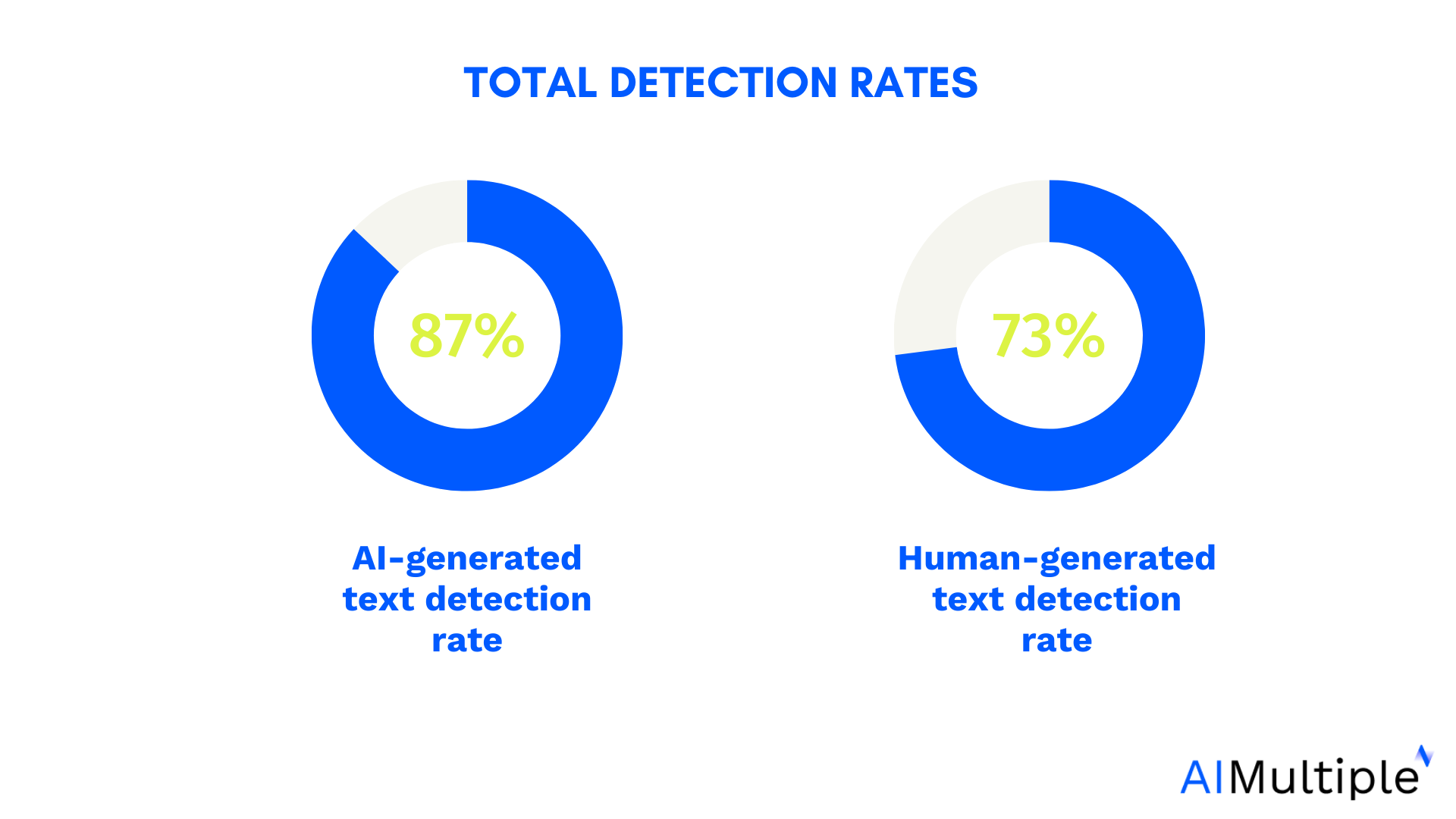
Finally, we will visualize the performance of the model using an ROC curve (Receiver Operating Characteristic Curve), which helps evaluate the trade-off between the true positive rate and false positive rate.
Visualizing the performance of a machine learning model is an essential step in understanding how well the model is doing, especially when it comes to evaluating its ability to detect fraudulent transactions.
What is an ROC curve?
An ROC curve shows how well a model performs across all classification thresholds. It plots the True Positive Rate (TPR) versus the False Positive Rate (FPR). The area under the ROC curve (AUC) provides a summary measure of model performance.
from sklearn.metrics import roc_curve, auc
# Calculate ROC curve
fpr, tpr, thresholds = roc_curve(y_test, rf_model.predict_proba(X_test)[:,1])
roc_auc = auc(fpr, tpr)
# Plot ROC curve
plt.figure(figsize=(8,6))
plt.plot(fpr, tpr, color='blue', label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()
The ROC curve gives us a comprehensive picture of how well our model is distinguishing between the two classes across various thresholds. By evaluating this curve, we can make decisions on how to tune the model’s threshold to find the best balance between detecting fraud and minimizing false alarms (that is, minimizing false positives).
Conclusion
By following this guide, you’ve learned how to leverage MLOps to automate fraud detection and ensure compliance in the financial industry using Google Colab. This cloud-based environment makes it easy to work with machine learning models without the hassle of local setups or configurations.
From automating data preprocessing to deploying models in production, MLOps offers an end-to-end solution that improves efficiency, scalability, and accuracy in detecting fraudulent activities.
By integrating real-time monitoring and continuous updates, financial institutions can stay ahead of fraud threats while ensuring regulatory compliance with minimal manual effort.
Key Takeaways
MLOps automates the whole machine learning model lifecycle by integrating machine learning with DevOps.
Simplifies regulatory compliance and fraud detection, letting banks spot fraudulent transactions automatically.
Maintains fraud detection systems current with fresh data through constant monitoring and model retraining.
Machine learning model development and testing may be done on Google Colab, a free cloud-based platform that provides access to GPUs and TPUs. No local installation is required.
Allows for automated workflows to detect suspicious behavior and send out alerts in real-time, allowing for fraud detection and alerting.
Continuous integration/continuous delivery pipelines guarantee continuous system improvement by automating the testing and deployment of new fraud detection models.
Financial organizations may save money using MLOps because cloud-based systems like Google Colab lower infrastructure expenses.




