![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)










































































































































































































































































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)
























































































![Roku clarifies how ‘Pause Ads’ work amid issues with some HDR content [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/roku-pause-ad-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)




















































































How to Train Your ̶D̶r̶a̶g̶o̶n̶ ̶ Model
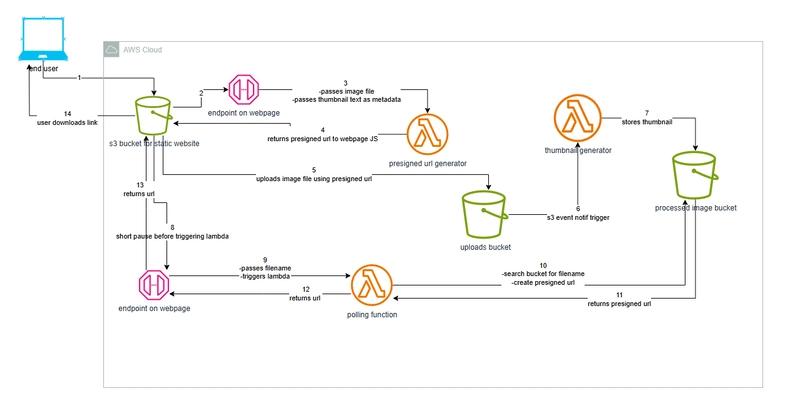
In one of my previous posts, we’ve discussed how we can utilize the AWS Bedrock suite of services to provision and run Agents that are 100% serverless. We were able to achieve it because AWS was kind enough to host some of the most popular models for us, granting access on a pay-per-usage model. This might work for rapid prototyping or PoCs, but using this payment model in production will have 3 major disadvantages. First, you will hit quota limit pretty fast. Since this model is shared, AWS limits the number of requests you can do in a given time slot. For example, Cross-Region InvokeModel tokens per minute for Anthropic Claude 3.5 Sonnet V2 is limited to 800,000. That might sound like a lot, but note that this limit is for a whole minute, for all requests (i.e. is shared by all sessions you might open to that model in a region). I’ve even hit this limit during my PoC! Second, is pricing. The pricier models, like the various versions of Claude Sonnet models, can run up quite a bill. You are charged per 1,000 input/output tokens (batching is a bit cheaper) and per caching. I’ve tried conversing with my Claude 3.5 Sonnet V2 based agent, and as the context grew I reached $0.1 per interaction (question\answer). Third, is speed. This is not true for all models, but it is for the large, multi-purpose ones. They can take a good 30 seconds to think, reason and generate responses sometimes. That’s understandable, as those models are very large and are shared. For real, production, loads that’s probably not acceptable. Now, we understand that not everyone can just host ChatGPT 4.5 on their laptop, and paying AWS to host a dedicated huge LLM just for you is not going to be cheap. The solution? Creating your own models. It might sound like something that only AI engineers can do, but using AWS Model Distillation in the Bedrock suite — this process can be quick, cheap and very easy. In this blog we’ll learn how to distill, host, and query your very own LLM using AWS Bedrock & Provisioned Throughput. AWS Model Distillation Model distillation is a machine learning technique where knowledge from a large, complex model (teacher) is transferred to a smaller, simpler model (student). The student model learns by mimicking the outputs or internal representations of the teacher, aiming to achieve similar performance with reduced computational resources. This approach enables deployment of efficient models suitable for resource-constrained environments without significantly sacrificing accuracy — for a very specific use case. Quick side note here — I personally think this is what this whole “AI” frenzy will eventually come down to — small, fast, specialized models that run everywhere, and can collaborate with other models if they need to do something outside of their expertise. Luckily for us, AWS Bedrock offers a very easy, fully managed process that allows you to train your own models to suit your specific business flow. The resulting model will (hopefully) mimic the larger, slower, expensive model that trained it, for the specific task it was trained on. This is also the place to note that the trainer and trainee models must be of the same model family. You can’t use AWS’ Nova Pro to train AI21 Labs’ Jamba 1.5 Mini, for example. For the purposes of this blog, we will use Nova Pro to train a Nova Micro, because I already used Claude 3.5 for my AI real-estate agents and have some conversation history I can use (which we are going to use to train Nova Micro). The training dataset needs to be in a very specific JSONL format, which can take some time to prepare. I used another model, Gemini 2.5 Pro, ironically, to structure the prompts from my chat history in a format that Bedrock Model Distillation can read. Other Training Methods A quick side note here about Fine-tuning and Continued Pre-training, which are two additional training methods that AWS Bedrock offers. Fine-tuning is somewhat similar to Distillation, but focuses on a specific task. You have something that the model does, and you want to make it better at doing exactly that. Model distillation is about focus — strip the dead weight from a bigger, more capable model, and only keep what you need from it, instead of training the larger model to be better at doing something very specific. Continued pre-training is a broader training option, used when you need a model to become familiar with your industry, company and professional jargon. This method is most relevant when embedding an Agent into your company and you want the base model (say, GPT-4.1) to “know” what your employees are talking about when they use industry or company specific lingo. Creating a Distilled Model Distilling a model using the AWS Bedrock console is very easy. Going to the “Custom Models” tab reveals all the available jobs that you can run to customize models. We are going to select “Model Distillation”. Then, we will select the teacher mode, th

In one of my previous posts, we’ve discussed how we can utilize the AWS Bedrock suite of services to provision and run Agents that are 100% serverless.
We were able to achieve it because AWS was kind enough to host some of the most popular models for us, granting access on a pay-per-usage model. This might work for rapid prototyping or PoCs, but using this payment model in production will have 3 major disadvantages.
First, you will hit quota limit pretty fast. Since this model is shared, AWS limits the number of requests you can do in a given time slot. For example, Cross-Region InvokeModel tokens per minute for Anthropic Claude 3.5 Sonnet V2 is limited to 800,000. That might sound like a lot, but note that this limit is for a whole minute, for all requests (i.e. is shared by all sessions you might open to that model in a region). I’ve even hit this limit during my PoC!
Second, is pricing. The pricier models, like the various versions of Claude Sonnet models, can run up quite a bill. You are charged per 1,000 input/output tokens (batching is a bit cheaper) and per caching. I’ve tried conversing with my Claude 3.5 Sonnet V2 based agent, and as the context grew I reached $0.1 per interaction (question\answer).
Third, is speed. This is not true for all models, but it is for the large, multi-purpose ones. They can take a good 30 seconds to think, reason and generate responses sometimes. That’s understandable, as those models are very large and are shared. For real, production, loads that’s probably not acceptable.
Now, we understand that not everyone can just host ChatGPT 4.5 on their laptop, and paying AWS to host a dedicated huge LLM just for you is not going to be cheap. The solution? Creating your own models.
It might sound like something that only AI engineers can do, but using AWS Model Distillation in the Bedrock suite — this process can be quick, cheap and very easy.
In this blog we’ll learn how to distill, host, and query your very own LLM using AWS Bedrock & Provisioned Throughput.
AWS Model Distillation
Model distillation is a machine learning technique where knowledge from a large, complex model (teacher) is transferred to a smaller, simpler model (student). The student model learns by mimicking the outputs or internal representations of the teacher, aiming to achieve similar performance with reduced computational resources. This approach enables deployment of efficient models suitable for resource-constrained environments without significantly sacrificing accuracy — for a very specific use case.
Quick side note here — I personally think this is what this whole “AI” frenzy will eventually come down to — small, fast, specialized models that run everywhere, and can collaborate with other models if they need to do something outside of their expertise.
Luckily for us, AWS Bedrock offers a very easy, fully managed process that allows you to train your own models to suit your specific business flow. The resulting model will (hopefully) mimic the larger, slower, expensive model that trained it, for the specific task it was trained on. This is also the place to note that the trainer and trainee models must be of the same model family. You can’t use AWS’ Nova Pro to train AI21 Labs’ Jamba 1.5 Mini, for example.
For the purposes of this blog, we will use Nova Pro to train a Nova Micro, because I already used Claude 3.5 for my AI real-estate agents and have some conversation history I can use (which we are going to use to train Nova Micro).
The training dataset needs to be in a very specific JSONL format, which can take some time to prepare. I used another model, Gemini 2.5 Pro, ironically, to structure the prompts from my chat history in a format that Bedrock Model Distillation can read.
Other Training Methods
A quick side note here about Fine-tuning and Continued Pre-training, which are two additional training methods that AWS Bedrock offers. Fine-tuning is somewhat similar to Distillation, but focuses on a specific task. You have something that the model does, and you want to make it better at doing exactly that. Model distillation is about focus — strip the dead weight from a bigger, more capable model, and only keep what you need from it, instead of training the larger model to be better at doing something very specific.
Continued pre-training is a broader training option, used when you need a model to become familiar with your industry, company and professional jargon. This method is most relevant when embedding an Agent into your company and you want the base model (say, GPT-4.1) to “know” what your employees are talking about when they use industry or company specific lingo.
Creating a Distilled Model
Distilling a model using the AWS Bedrock console is very easy. Going to the “Custom Models” tab reveals all the available jobs that you can run to customize models. We are going to select “Model Distillation”.

Then, we will select the teacher mode, the student model, and our dataset to be used for training. As mentioned before, the teacher and student models must be of the same model family, i.e. you must use models from the same vendor.
The distillation job can run for quite a while, depending on your dataset, but at the end of it you should have a distilled model in your Models tab.


Congratulations! It’s a model!

Running Your Model
Now, this is a bit of a “gotcha”. To run a model, you need to purchase Provisioned Throughput. That means that AWS will provision some resources, 100% dedicated for your model — and it may cost you a very pretty penny.
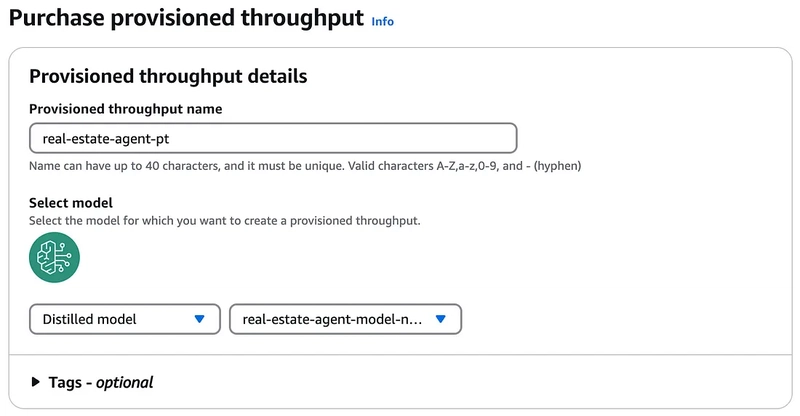
I had issues purchasing Provisioned Throughput myself, and even reached out through internal channels for AWS Builders and got some help from a Principal AI Architect on the Bedrock team (thanks guys!). Because purchasing Provisioned Throughput can cost you literally hundreds of thousands of dollars per month for some of the larger models — it’s not the go-to solution for most individuals — even most companies.
A smaller Nova Micro did not break my bank, but pricing quotes are not to be taken lightly here. Only those with consistently steady, predictable, production-grade throughput should opt in for purchasing reserved throughput over Inference.
However, we are experimenting here, and we need to check out the result of our distillation job, so… let’s do it!
Comparing Model Results
Once we have purchased Provisioned Throughput, you can run your custom model.

We will use the “Chat” option, and compare the AWS-hosted Nova Pro model vs. our distilled Nova Micro-based model.

As we can see, our custom Nova Micro model was twice as fast and provided more accurate information. Our distilled model took 1527ms, while Nova Pro took 2623ms. Also, it used ILS as the main currency (but still converted to USD, for some reason) because the prices in its training data were in ILS. The only thing I’m not sure about is the fact that Nova Micro said its information is updated for the year 2023, when my listing information was very recent. Post in the comments if you know why that happened.
I am not going to use this model for my real-estate agents, for now. Provisioned Throughput is still very expensive to just leave running and forget about it. However, I hear that AWS is working on a new version, internally dubbed as “Provisioned Throughput 2” which will be available in Q3 of 2025. I don’t know exactly what’s going to be different there, but it will “make Provisioned Throughput a viable option for more of our customers”.
I’ll be sure to check that out once it’s available.
Closing Thoughts
In this short technical blog, we have created a custom, one-of-a-kind, language model. It’s still very pricy to run 24/7, but if you have a production-grade, predictably and long running GenAI backed workload — this can really save you a pretty penny, while offering a lot more throughput.
P.S.
Did I mention this whole project was done using only the web browser?