





















































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)















































































































































































































































































_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































![Craft adds Readwise integration for working with book notes and highlights [50% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/craft3.jpg.png?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)































































































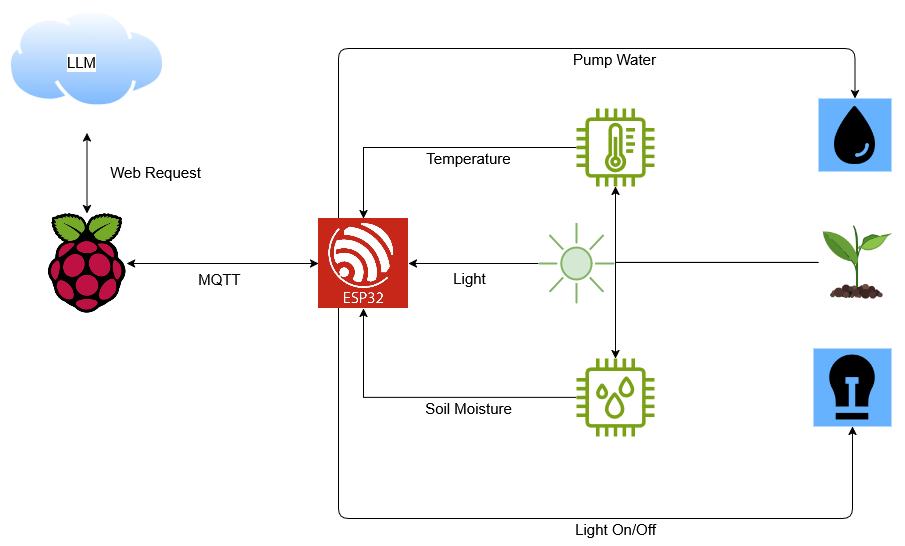
Build Code-RAGent, an agent for your codebase
Introduction Recently, I've been hooked up with automating data ingestion into vector databases, and I came up with ingest-anything, which I talked about in my last post. After Chonkie released CodeChunker, I decided to include code ingestion within ingest-anything, and you can read about it in this LinkedIn post, where I announced the new release: The only thing left to do then was to build something that could showcase the power of code ingestion within a vector database, and it immediately clicked in my mind: "Why don't I ingest my entire codebase of solved Go exercises from Exercism?" That's how I created Code-RAGent, your friendly coding assistant based on your personal codebases and grounded in web search. It is built on top of GPT-4.1, powered by OpenAI, LinkUp, LlamaIndex, Qdrant, FastAPI and Streamlit. The building of this project was aimed at providing a reproducible and adaptable agent, that people can therefore customize based on their needs, and it was composed of three phases: Environment setup Data preparation and ingestion Agent workflow design Environment Setup I personally like setting up my environment using conda, also because it's easily dockerizable, so we'll follow this path: conda create -y -n code-ragent python=3.11 # you don't necessarily need to specify 3.11, it's for reproducibility purposes conda activate code-ragent Now let's install all the needed packages within our environment: python3 -m pip install ingest-anything streamlit ingest-anything already wraps all the packages that we need to get our Code-RAGent up and running, we just need to add streamlit, which we'll use to create the frontend. Let's also get a Qdrant instance, as a vector database, locally using Docker: docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant:latest Data ingestion The starting data, as I said earlier, will be my learning-go repository, that contains solved Go exercises coming from Exercism. We can get the repository by cloning it: git clone https://github.com/AstraBert/learning-go And now we can get all the Go files contained in it, in our python scripts, as follows: import os files = [] for root, _, fls in os.walk("./learning-go"): for f in fls: if f.endswith(".go"): files.append(os.path.join(root, f)) Now let's ingest all the files with ingest-anything: from ingest_anything.ingestion import IngestCode from qdrant_client import QdrantClient, AsyncQdrantClient client = QdrantClient("http://localhost:6333") aclient = AsyncQdrantClient("http://localhost:6333") ingestor = IngestCode(qdrant_client=client, async_qdrant_client=aclient, collection_name="go-code",hybrid_search=True) vector_index = ingestor.ingest(files=files, embedding_model="Shuu12121/CodeSearch-ModernBERT-Owl", language="go") And this is it: the collection go-code is now set up and available for search within Qdrant, so we can get our hands actually on agent workflow design. Agent workflow design This is a visualization of Code-RAGent workflow: We won't see the details of the code here, just high-level concepts, but you can find everything in the GitHub repo. 1. Tools We need three main tools: vector_search_tool that searches the vector database, using a LlamaIndex Query Engine, that first produces a hypothetical document embedding (HyDE) and then matches it with the database using hybrid retrieval, producing a final summary response. web_search_tool that can ground solutions in web search: we exploit Linkup, and we format the search results in such a way that the tool always produces a code explanation and, when necessary, a code snippet. evaluate_response that can give a correctness, faithfulness and relevancy score to the agent's final response based on the original user query and on the retrieved context (either from the web or from vector search). For this purpose, we use LlamaIndex evaluators 2. Designing and serving the agent We use a simple and straightforward Function Calling Agent within the Agent Workflow module in LlamaIndex, and we give the agent access to all the tools designed at point (1). Now, it's just a matter of deploying the agent on an API endpoint, making it available to the frontend portion of our application: we do it via FastAPI, serving the agent under the /chat POST endpoint. 3. User Interface The UI, written with Streamlit, can be set up like this: import streamlit as st import requests as rq from pydantic import BaseModel class ApiInput(BaseModel): prompt: str def get_chat(prompt: str): response = rq.post("http://backend:8000/chat/", json=ApiInput(prompt=prompt).model_dump()) actual_res = response.json()["response"] actual_proc = response.json()["proces"] return actual_res, actual_proc st.title("Code RAGent
Introduction
Recently, I've been hooked up with automating data ingestion into vector databases, and I came up with ingest-anything, which I talked about in my last post.
After Chonkie released CodeChunker, I decided to include code ingestion within ingest-anything, and you can read about it in this LinkedIn post, where I announced the new release:
The only thing left to do then was to build something that could showcase the power of code ingestion within a vector database, and it immediately clicked in my mind: "Why don't I ingest my entire codebase of solved Go exercises from Exercism?"
That's how I created Code-RAGent, your friendly coding assistant based on your personal codebases and grounded in web search. It is built on top of GPT-4.1, powered by OpenAI, LinkUp, LlamaIndex, Qdrant, FastAPI and Streamlit.
The building of this project was aimed at providing a reproducible and adaptable agent, that people can therefore customize based on their needs, and it was composed of three phases:
- Environment setup
- Data preparation and ingestion
- Agent workflow design
Environment Setup
I personally like setting up my environment using conda, also because it's easily dockerizable, so we'll follow this path:
conda create -y -n code-ragent python=3.11 # you don't necessarily need to specify 3.11, it's for reproducibility purposes
conda activate code-ragent
Now let's install all the needed packages within our environment:
python3 -m pip install ingest-anything streamlit
ingest-anything already wraps all the packages that we need to get our Code-RAGent up and running, we just need to add streamlit, which we'll use to create the frontend.
Let's also get a Qdrant instance, as a vector database, locally using Docker:
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant:latest
Data ingestion
The starting data, as I said earlier, will be my learning-go repository, that contains solved Go exercises coming from Exercism. We can get the repository by cloning it:
git clone https://github.com/AstraBert/learning-go
And now we can get all the Go files contained in it, in our python scripts, as follows:
import os
files = []
for root, _, fls in os.walk("./learning-go"):
for f in fls:
if f.endswith(".go"):
files.append(os.path.join(root, f))
Now let's ingest all the files with ingest-anything:
from ingest_anything.ingestion import IngestCode
from qdrant_client import QdrantClient, AsyncQdrantClient
client = QdrantClient("http://localhost:6333")
aclient = AsyncQdrantClient("http://localhost:6333")
ingestor = IngestCode(qdrant_client=client, async_qdrant_client=aclient, collection_name="go-code",hybrid_search=True)
vector_index = ingestor.ingest(files=files, embedding_model="Shuu12121/CodeSearch-ModernBERT-Owl", language="go")
And this is it: the collection go-code is now set up and available for search within Qdrant, so we can get our hands actually on agent workflow design.
Agent workflow design
This is a visualization of Code-RAGent workflow:
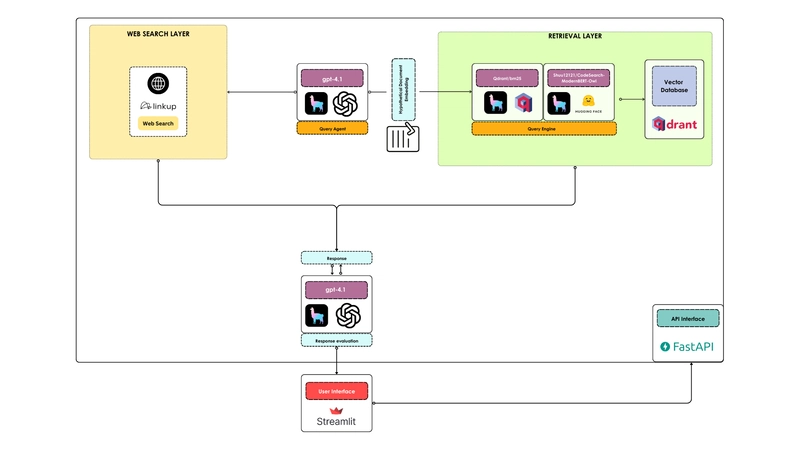
We won't see the details of the code here, just high-level concepts, but you can find everything in the GitHub repo.
1. Tools
We need three main tools:
-
vector_search_toolthat searches the vector database, using a LlamaIndex Query Engine, that first produces a hypothetical document embedding (HyDE) and then matches it with the database using hybrid retrieval, producing a final summary response. -
web_search_toolthat can ground solutions in web search: we exploit Linkup, and we format the search results in such a way that the tool always produces a code explanation and, when necessary, a code snippet. -
evaluate_responsethat can give a correctness, faithfulness and relevancy score to the agent's final response based on the original user query and on the retrieved context (either from the web or from vector search). For this purpose, we use LlamaIndex evaluators
2. Designing and serving the agent
We use a simple and straightforward Function Calling Agent within the Agent Workflow module in LlamaIndex, and we give the agent access to all the tools designed at point (1).
Now, it's just a matter of deploying the agent on an API endpoint, making it available to the frontend portion of our application: we do it via FastAPI, serving the agent under the /chat POST endpoint.
3. User Interface
The UI, written with Streamlit, can be set up like this:
import streamlit as st
import requests as rq
from pydantic import BaseModel
class ApiInput(BaseModel):
prompt: str
def get_chat(prompt: str):
response = rq.post("http://backend:8000/chat/", json=ApiInput(prompt=prompt).model_dump())
actual_res = response.json()["response"]
actual_proc = response.json()["proces"]
return actual_res, actual_proc
st.title("Code RAGent