
.jpg)








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

























































































































































![BPMN-procesmodellering [closed]](https://i.sstatic.net/l7l8q49F.png)



























































































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-All-will-be-revealed-00-17-36.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-Jack-Black---Steve's-Lava-Chicken-(Official-Music-Video)-A-Minecraft-Movie-Soundtrack-WaterTower-00-00-32_lMoQ1fI.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























_Weyo_alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)
_Brain_light_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


































































































![New M4 MacBook Air On Sale for $929 [Lowest Price Ever]](https://www.iclarified.com/images/news/97090/97090/97090-1280.jpg)
![Apple iPhone 17 Pro May Come in 'Sky Blue' Color [Rumor]](https://www.iclarified.com/images/news/97088/97088/97088-640.jpg)
![Mac Shipments Up 17% in Q1 2025 Fueled by New M4 MacBook Air [Chart]](https://www.iclarified.com/images/news/97086/97086/97086-640.jpg)
![Next Generation iPhone 17e Nears Trial Production [Rumor]](https://www.iclarified.com/images/news/97083/97083/97083-640.jpg)

















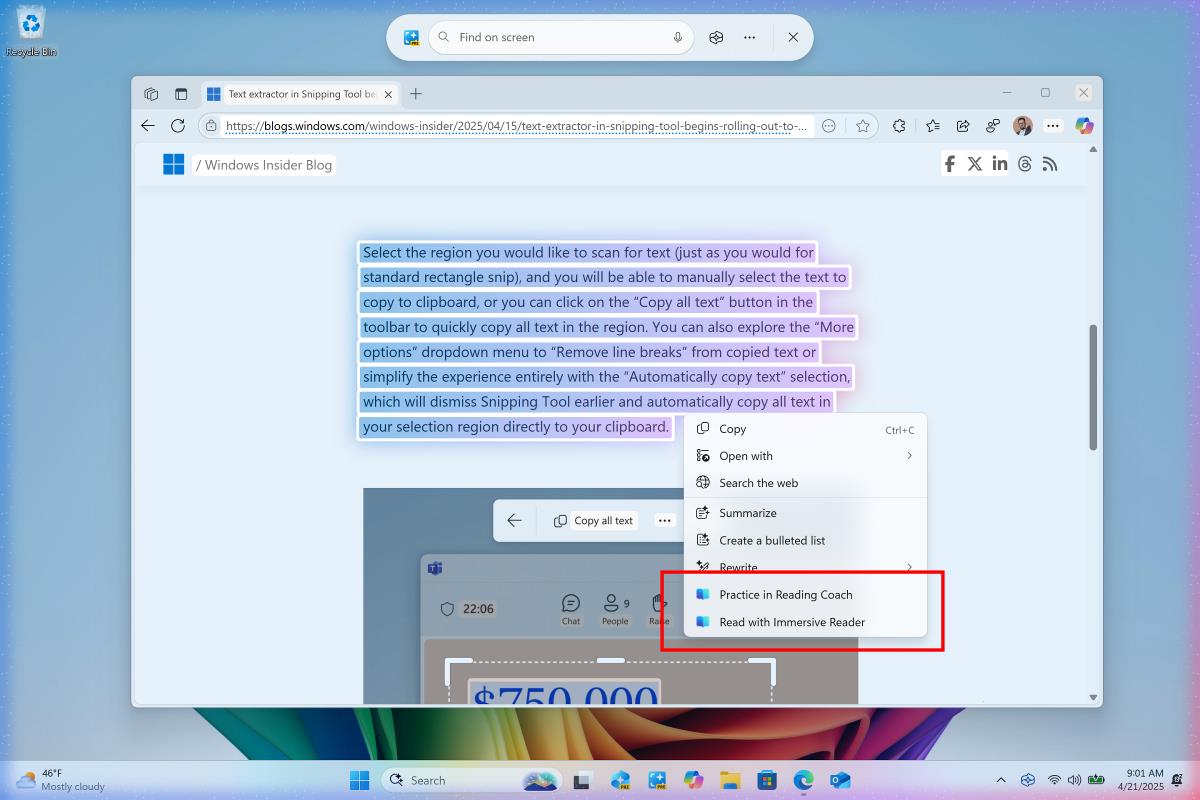







































































































Bias trong machine learning là gì
Trí tuệ nhân tạo đang dần len lỏi vào mọi ngóc ngách của cuộc sống, từ những đề xuất phim ảnh bạn xem hàng ngày đến các hệ thống hỗ trợ ra quyết định phức tạp. Nhưng liệu AI có luôn công bằng? Một trong những thách thức lớn nhất mà cộng đồng phát triển AI đối mặt chính là thiên lệch, hay bias. Tại Công Nghệ AI VN, chúng tôi tin rằng việc nhận diện và xử lý bias là yếu tố then chốt để tạo ra công nghệ thực sự hữu ích và đạo đức. Bài viết này sẽ cùng bạn đào sâu vào khái niệm bias trong machine learning. Bias trong Machine Learning Thực Chất Là Gì? Hãy hình dung bias trong machine learning như một lăng kính bị lệch màu khi mô hình AI nhìn vào dữ liệu. Nó không phải là một lỗi code đơn thuần, mà là một xu hướng có hệ thống khiến mô hình đưa ra các dự đoán thiếu chính xác hoặc ưu tiên một nhóm nào đó hơn những nhóm khác. Nguyên nhân gốc rễ thường nằm ở dữ liệu huấn luyện – nếu dữ liệu đó không phản ánh đầy đủ, đa dạng và công bằng về thế giới thực, mô hình học từ đó cũng sẽ kế thừa những khiếm khuyết này. Ví dụ, nếu một thuật toán dùng để sàng lọc hồ sơ ứng viên được huấn luyện chủ yếu dựa trên dữ liệu lịch sử của các nhân viên nam thành công trong quá khứ tại một công ty, nó có thể vô tình hạ thấp tiềm năng của các ứng viên nữ, ngay cả khi họ có kỹ năng và kinh nghiệm tương đương. Bias không chỉ làm giảm hiệu quả của mô hình mà còn có thể gây ra những hậu quả xã hội nghiêm trọng, củng cố định kiến và tạo ra sự bất bình đẳng. Các Dạng Bias Phổ Biến Trong Học Máy Thiên lệch có thể ẩn mình dưới nhiều hình thức khác nhau trong quá trình xây dựng mô hình AI. Hiểu rõ chúng là bước đầu tiên để đối phó: Bias Loại Trừ (Exclusion Bias): Dạng bias này nảy sinh khi chúng ta chủ quan loại bỏ một phần dữ liệu mà ta cho là không quan trọng hoặc không liên quan, nhưng thực tế lại chứa thông tin giá trị. Chẳng hạn, khi phân tích hành vi người dùng trên một trang web thương mại điện tử, nếu bỏ qua dữ liệu từ những người dùng truy cập bằng trình duyệt cũ hoặc thiết bị ít phổ biến, mô hình có thể không tối ưu được trải nghiệm cho nhóm người dùng này. Bias Nhớ Lại (Recall Bias): Xảy ra trong quá trình thu thập hoặc gán nhãn dữ liệu, đặc biệt khi dựa vào trí nhớ hoặc đánh giá chủ quan. Ví dụ, trong một khảo sát về mức độ hài lòng với dịch vụ y tế, những người có trải nghiệm tiêu cực có thể nhớ lại và mô tả chi tiết hơn những người có trải nghiệm tích cực, làm sai lệch bức tranh chung về chất lượng dịch vụ khi dữ liệu này được dùng để huấn luyện mô hình. Bias Mẫu (Sample Bias): Đây là một trong những dạng phổ biến nhất, xảy ra khi dữ liệu được thu thập không đại diện cho toàn bộ quần thể mà mô hình sẽ tương tác trong thực tế. Hãy tưởng tượng một hệ thống nhận dạng giọng nói được huấn luyện chủ yếu bằng giọng chuẩn phổ thông sẽ gặp khó khăn lớn khi phải xử lý giọng nói của người dùng ở các vùng miền khác nhau hoặc người nói tiếng Anh như ngôn ngữ thứ hai. Bias Liên Kết (Association Bias): Dạng bias này hình thành khi mô hình học được những liên kết sai lệch hoặc mang tính định kiến tồn tại sẵn trong dữ liệu. Ví dụ, nếu dữ liệu huấn luyện chứa nhiều hình ảnh bác sĩ là nam và y tá là nữ, mô hình AI có thể học được mối liên kết nghề nghiệp theo giới tính này, dẫn đến các dự đoán hoặc đề xuất mang tính rập khuôn, bỏ qua sự đa dạng thực tế của xã hội. Làm Thế Nào Để Giảm Thiểu Bias Trong Mô Hình AI? May mắn là chúng ta không hoàn toàn bất lực trước bias. Có nhiều chiến lược và kỹ thuật có thể áp dụng để xây dựng các mô hình AI công bằng hơn: Thu Thập và Tiền Xử Lý Dữ Liệu Cẩn Thận: Đây là tuyến phòng thủ đầu tiên. Cần nỗ lực đảm bảo bộ dữ liệu huấn luyện đa dạng, cân bằng và đại diện cho tất cả các nhóm người dùng tiềm năng. Các kỹ thuật như thu thập thêm dữ liệu cho các nhóm thiểu số, sử dụng phương pháp tạo dữ liệu tổng hợp (synthetic data generation), hoặc kỹ thuật tái lấy mẫu (resampling) có thể giúp cân bằng dữ liệu. Lựa Chọn và Điều Chỉnh Thuật Toán: Một số thuật toán học máy vốn nhạy cảm hơn với bias so với các thuật toán khác. Bên cạnh đó, có thể áp dụng các kỹ thuật điều chuẩn (regularization) đặc biệt hoặc các phương pháp huấn luyện nhận biết sự công bằng (fairness-aware training) để ngăn mô hình quá phụ thuộc vào các thuộc tính nhạy cảm (như giới tính, chủng tộc, độ tuổi). Sử Dụng Các Công Cụ Phát Hiện và Đo Lường Bias: Nhiều bộ công cụ và thư viện mã nguồn mở (như Fairlearn, AI Fairness 360) đã được phát triển để giúp các nhà phát triển đánh giá mức độ bias trong mô hình của họ theo các chỉ số công bằng khác nhau. Việc đo lường là cần thiết để có thể cải thiện. Tăng Cường Tính Minh Bạch và Giải Thích Được (Explainability): Hiểu được tại sao mô hình đưa ra một dự đoán cụ thể giúp phát hiện ra các lý do dựa trên bias. Các kỹ thuật diễn giải mô hình (model interpretability) ngày càng trở nên quan trọng. Kiểm Tra và Giám Sát Liên Tục: Bias có thể xuất hiện trở lại ngay cả sau khi mô hình đã được triển khai do sự thay đổi trong dữ liệu thực tế (data drift). Việc kiểm tra định kỳ và giám sát hiệu suất mô hình trên các

Trí tuệ nhân tạo đang dần len lỏi vào mọi ngóc ngách của cuộc sống, từ những đề xuất phim ảnh bạn xem hàng ngày đến các hệ thống hỗ trợ ra quyết định phức tạp. Nhưng liệu AI có luôn công bằng? Một trong những thách thức lớn nhất mà cộng đồng phát triển AI đối mặt chính là thiên lệch, hay bias. Tại Công Nghệ AI VN, chúng tôi tin rằng việc nhận diện và xử lý bias là yếu tố then chốt để tạo ra công nghệ thực sự hữu ích và đạo đức. Bài viết này sẽ cùng bạn đào sâu vào khái niệm bias trong machine learning.
Bias trong Machine Learning Thực Chất Là Gì?
Hãy hình dung bias trong machine learning như một lăng kính bị lệch màu khi mô hình AI nhìn vào dữ liệu. Nó không phải là một lỗi code đơn thuần, mà là một xu hướng có hệ thống khiến mô hình đưa ra các dự đoán thiếu chính xác hoặc ưu tiên một nhóm nào đó hơn những nhóm khác. Nguyên nhân gốc rễ thường nằm ở dữ liệu huấn luyện – nếu dữ liệu đó không phản ánh đầy đủ, đa dạng và công bằng về thế giới thực, mô hình học từ đó cũng sẽ kế thừa những khiếm khuyết này.
Ví dụ, nếu một thuật toán dùng để sàng lọc hồ sơ ứng viên được huấn luyện chủ yếu dựa trên dữ liệu lịch sử của các nhân viên nam thành công trong quá khứ tại một công ty, nó có thể vô tình hạ thấp tiềm năng của các ứng viên nữ, ngay cả khi họ có kỹ năng và kinh nghiệm tương đương. Bias không chỉ làm giảm hiệu quả của mô hình mà còn có thể gây ra những hậu quả xã hội nghiêm trọng, củng cố định kiến và tạo ra sự bất bình đẳng.
Các Dạng Bias Phổ Biến Trong Học Máy
Thiên lệch có thể ẩn mình dưới nhiều hình thức khác nhau trong quá trình xây dựng mô hình AI. Hiểu rõ chúng là bước đầu tiên để đối phó:
Bias Loại Trừ (Exclusion Bias): Dạng bias này nảy sinh khi chúng ta chủ quan loại bỏ một phần dữ liệu mà ta cho là không quan trọng hoặc không liên quan, nhưng thực tế lại chứa thông tin giá trị. Chẳng hạn, khi phân tích hành vi người dùng trên một trang web thương mại điện tử, nếu bỏ qua dữ liệu từ những người dùng truy cập bằng trình duyệt cũ hoặc thiết bị ít phổ biến, mô hình có thể không tối ưu được trải nghiệm cho nhóm người dùng này.
Bias Nhớ Lại (Recall Bias): Xảy ra trong quá trình thu thập hoặc gán nhãn dữ liệu, đặc biệt khi dựa vào trí nhớ hoặc đánh giá chủ quan. Ví dụ, trong một khảo sát về mức độ hài lòng với dịch vụ y tế, những người có trải nghiệm tiêu cực có thể nhớ lại và mô tả chi tiết hơn những người có trải nghiệm tích cực, làm sai lệch bức tranh chung về chất lượng dịch vụ khi dữ liệu này được dùng để huấn luyện mô hình.
Bias Mẫu (Sample Bias): Đây là một trong những dạng phổ biến nhất, xảy ra khi dữ liệu được thu thập không đại diện cho toàn bộ quần thể mà mô hình sẽ tương tác trong thực tế. Hãy tưởng tượng một hệ thống nhận dạng giọng nói được huấn luyện chủ yếu bằng giọng chuẩn phổ thông sẽ gặp khó khăn lớn khi phải xử lý giọng nói của người dùng ở các vùng miền khác nhau hoặc người nói tiếng Anh như ngôn ngữ thứ hai.
Bias Liên Kết (Association Bias): Dạng bias này hình thành khi mô hình học được những liên kết sai lệch hoặc mang tính định kiến tồn tại sẵn trong dữ liệu. Ví dụ, nếu dữ liệu huấn luyện chứa nhiều hình ảnh bác sĩ là nam và y tá là nữ, mô hình AI có thể học được mối liên kết nghề nghiệp theo giới tính này, dẫn đến các dự đoán hoặc đề xuất mang tính rập khuôn, bỏ qua sự đa dạng thực tế của xã hội.

Làm Thế Nào Để Giảm Thiểu Bias Trong Mô Hình AI?
May mắn là chúng ta không hoàn toàn bất lực trước bias. Có nhiều chiến lược và kỹ thuật có thể áp dụng để xây dựng các mô hình AI công bằng hơn:
Thu Thập và Tiền Xử Lý Dữ Liệu Cẩn Thận: Đây là tuyến phòng thủ đầu tiên. Cần nỗ lực đảm bảo bộ dữ liệu huấn luyện đa dạng, cân bằng và đại diện cho tất cả các nhóm người dùng tiềm năng. Các kỹ thuật như thu thập thêm dữ liệu cho các nhóm thiểu số, sử dụng phương pháp tạo dữ liệu tổng hợp (synthetic data generation), hoặc kỹ thuật tái lấy mẫu (resampling) có thể giúp cân bằng dữ liệu.
Lựa Chọn và Điều Chỉnh Thuật Toán: Một số thuật toán học máy vốn nhạy cảm hơn với bias so với các thuật toán khác. Bên cạnh đó, có thể áp dụng các kỹ thuật điều chuẩn (regularization) đặc biệt hoặc các phương pháp huấn luyện nhận biết sự công bằng (fairness-aware training) để ngăn mô hình quá phụ thuộc vào các thuộc tính nhạy cảm (như giới tính, chủng tộc, độ tuổi).
Sử Dụng Các Công Cụ Phát Hiện và Đo Lường Bias: Nhiều bộ công cụ và thư viện mã nguồn mở (như Fairlearn, AI Fairness 360) đã được phát triển để giúp các nhà phát triển đánh giá mức độ bias trong mô hình của họ theo các chỉ số công bằng khác nhau. Việc đo lường là cần thiết để có thể cải thiện.
Tăng Cường Tính Minh Bạch và Giải Thích Được (Explainability): Hiểu được tại sao mô hình đưa ra một dự đoán cụ thể giúp phát hiện ra các lý do dựa trên bias. Các kỹ thuật diễn giải mô hình (model interpretability) ngày càng trở nên quan trọng.
Kiểm Tra và Giám Sát Liên Tục: Bias có thể xuất hiện trở lại ngay cả sau khi mô hình đã được triển khai do sự thay đổi trong dữ liệu thực tế (data drift). Việc kiểm tra định kỳ và giám sát hiệu suất mô hình trên các nhóm người dùng khác nhau là rất quan trọng.

Bias trong machine learning là một thách thức phức tạp, đòi hỏi sự chú ý và nỗ lực không ngừng từ cộng đồng AI. Việc xây dựng các hệ thống AI công bằng không chỉ là vấn đề kỹ thuật mà còn là trách nhiệm đạo đức. Bằng cách hiểu rõ các loại bias, áp dụng các phương pháp giảm thiểu tiên tiến và duy trì cam kết về tính minh bạch, chúng ta có thể hướng tới một tương lai nơi AI thực sự phục vụ lợi ích của tất cả mọi người.
Hãy cùng Công Nghệ AI VN tiếp tục hành trình khám phá và xây dựng một thế giới AI tốt đẹp hơn!


