



























![[Free Webinar] Guide to Securing Your Entire Identity Lifecycle Against AI-Powered Threats](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjqbZf4bsDp6ei3fmQ8swm7GB5XoRrhZSFE7ZNhRLFO49KlmdgpIDCZWMSv7rydpEShIrNb9crnH5p6mFZbURzO5HC9I4RlzJazBBw5aHOTmI38sqiZIWPldRqut4bTgegipjOk5VgktVOwCKF_ncLeBX-pMTO_GMVMfbzZbf8eAj21V04y_NiOaSApGkM/s1600/webinar-play.jpg?#)











































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)



















































































































































































































































_XFkvNLu.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























_Tanapong_Sungkaew_via_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






































































































![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)


























































































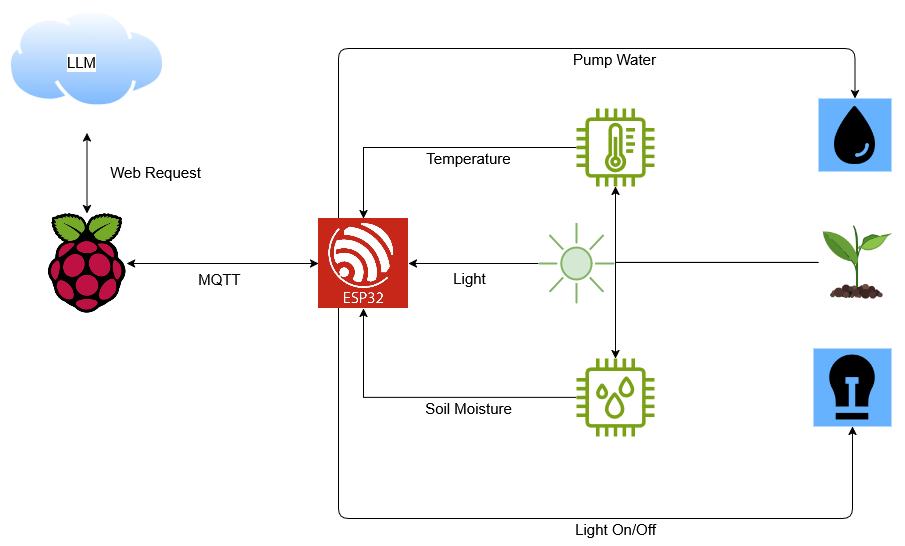
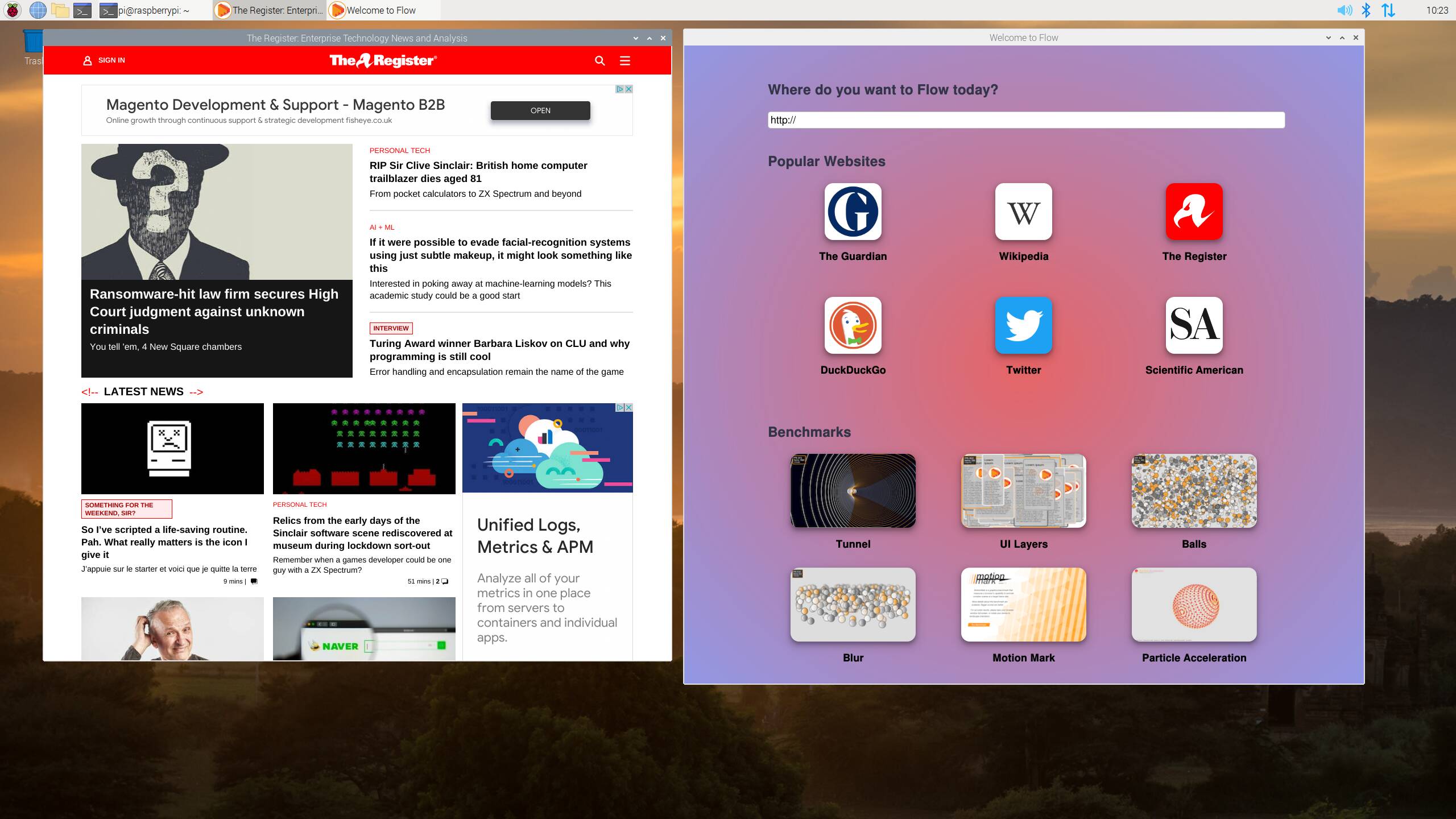
Batch PDF-to-Image Conversion with Snowflake ML Jobs and Text Transcription Using Cortex Multimodal
1. Introduction As background, when you need to extract text from unstructured data such as PDFs or Docs, Snowflake’s built-in Document AI does not support JAPANESE. Likewise, the PARSE_DOCUMENT function is not optimized for Japanese in OCR mode and isn’t fully supported in Layout mode, making Japanese text extraction extremely difficult. Traditionally, simple unstructured processing in Snowflake could be handled by Python user-defined functions (UDF/UDTF), but from the perspective of data scientists accustomed to writing in Jupyter Notebooks, UDF/UDTFs felt inflexible and unfamiliar to those not well-versed in databases, and therefore never saw broad adoption. Many teams also relied on external services like AWS Lambda and AWS Bedrock, but managing AWS-specific permissions and an ever-growing suite of services increased the learning curve and operational overhead. To address these challenges, Snowflake introduced ML Jobs, a new service that lets you schedule and parallelize Python functions as remote executions. In this article, we outline a workflow that uses Snowflake ML Jobs to run PDF→PNG conversion in parallel, then analyzes the resulting images with Snowflake Cortex AI’s COMPLETE Multimodal function to extract data. We rename the stage to test_stage and complete the entire pipeline using only Snowflake’s native multimodal capabilities—no external APIs (Bedrock) required. All code and SQL snippets shown here were validated in Snowflake Notebook on SPCS. Below is an overview of the end-to-end process. TL;DR ML jobs Pure-Python remote registration You can register a Python function using only the @remote decorator. It will auto-scale on GPU- or high-memory Compute Pools, and you don’t need to build any container images for Snowpark Container Services (SPCS). Seamless Snowflake ML integration Works end-to-end within Snowflake ML and connects transparently from your IDE (VS Code, Cursor, etc.). File-based processing made easy Tasks that were impractical in a traditional warehouse—like bulk file operations—become trivial. Declarative, reproducible pipelines Define stages (directory tables), grants, and external-access integrations in SQL to build fully reproducible ML pipelines. Cost-effective execution on SPCS Runs on Snowpark Container Services at very low cost (SPCS CPU XS is only 0.06 credits/hour—up to 1/16 the cost of a comparable warehouse). Complete – MultiModal Single-SQL function handles images + text together; pass .jpg/.png files on stages directly for inference. Supports image captioning, classification, comparison, entity extraction, graph/table QA, and batch-inferencing of hundreds of images via simple table joins—no extra infra required. As of April 2025, choose from Pixtral Large (GA) or Claude 3.5 Sonnet vision models, with governance and billing fully integrated into Snowflake. 2. Prerequisites and Environment Setup 2-1. Create Dedicated Stages First, create two internal stages—one for your source PDFs and one for ML Jobs payloads—using Snowflake-managed encryption: -- Stage to store PDFs CREATE OR REPLACE STAGE test_stage ENCRYPTION = (TYPE = 'snowflake_sse'); -- Stage for ML Jobs payloads CREATE OR REPLACE STAGE payload_stage ENCRYPTION = (TYPE = 'snowflake_sse'); 2-2. Create a Compute Pool Snowflake ML Jobs run on a dedicated Compute Pool (e.g. MY_COMPUTE_POOL). See the official docs on CREATE COMPUTE POOL for detailed syntax and options. 2-3. Dependencies Only PyMuPDF needs to be fetched from PyPI—grant your PYPI_ACCESS_INTEGRATION accordingly. If you haven’t yet set up external network access for your account, see Snowflake Notebooks: Set up external access. 3. Implementing ML Jobs 3-1. Creating the Function to Convert PDFs to Images Define a @remote function that Snowflake will register and execute in parallel on your Compute Pool. We recommend calling get_active_session() at the top of your function when using Snowpark APIs. from snowflake.ml.jobs import remote import fitz, os, traceback compute_pool = "MY_COMPUTE_POOL" @remote( compute_pool, stage_name="payload_stage", # Temporary storage for generated images pip_requirements=['PyMuPDF'], # Dependency libraries external_access_integrations=['PYPI_ACCESS_INTEGRATION'] ) def convert_pdfs_to_images(stage_name, file_name, temp_input="tmp/input/", temp_output="tmp/output/"): """ Converts the specified PDF file to images and saves them to the output directory. Parameters: - stage_name (str): Name of the stage (e.g. '@pdf/') - file_list (list): List of PDF filenames to convert - temp_input (str): Local directory for input files - temp_output(str): Local directory for output images Returns: - dict: { 'success': True|False, 'output_files': [...], 'errors':
1. Introduction
As background, when you need to extract text from unstructured data such as PDFs or Docs, Snowflake’s built-in Document AI does not support JAPANESE. Likewise, the PARSE_DOCUMENT function is not optimized for Japanese in OCR mode and isn’t fully supported in Layout mode, making Japanese text extraction extremely difficult.
Traditionally, simple unstructured processing in Snowflake could be handled by Python user-defined functions (UDF/UDTF), but from the perspective of data scientists accustomed to writing in Jupyter Notebooks, UDF/UDTFs felt inflexible and unfamiliar to those not well-versed in databases, and therefore never saw broad adoption.
Many teams also relied on external services like AWS Lambda and AWS Bedrock, but managing AWS-specific permissions and an ever-growing suite of services increased the learning curve and operational overhead.
To address these challenges, Snowflake introduced ML Jobs, a new service that lets you schedule and parallelize Python functions as remote executions. In this article, we outline a workflow that uses Snowflake ML Jobs to run PDF→PNG conversion in parallel, then analyzes the resulting images with Snowflake Cortex AI’s COMPLETE Multimodal function to extract data. We rename the stage to test_stage and complete the entire pipeline using only Snowflake’s native multimodal capabilities—no external APIs (Bedrock) required. All code and SQL snippets shown here were validated in Snowflake Notebook on SPCS. Below is an overview of the end-to-end process.
TL;DR
ML jobs
- Pure-Python remote registration You can register a Python function using only the @remote decorator. It will auto-scale on GPU- or high-memory Compute Pools, and you don’t need to build any container images for Snowpark Container Services (SPCS).
- Seamless Snowflake ML integration Works end-to-end within Snowflake ML and connects transparently from your IDE (VS Code, Cursor, etc.).
- File-based processing made easy Tasks that were impractical in a traditional warehouse—like bulk file operations—become trivial.
- Declarative, reproducible pipelines Define stages (directory tables), grants, and external-access integrations in SQL to build fully reproducible ML pipelines.
- Cost-effective execution on SPCS Runs on Snowpark Container Services at very low cost (SPCS CPU XS is only 0.06 credits/hour—up to 1/16 the cost of a comparable warehouse).
Complete – MultiModal
- Single-SQL function handles images + text together; pass .jpg/.png files on stages directly for inference.
- Supports image captioning, classification, comparison, entity extraction, graph/table QA, and batch-inferencing of hundreds of images via simple table joins—no extra infra required.
- As of April 2025, choose from Pixtral Large (GA) or Claude 3.5 Sonnet vision models, with governance and billing fully integrated into Snowflake.
2. Prerequisites and Environment Setup
2-1. Create Dedicated Stages
First, create two internal stages—one for your source PDFs and one for ML Jobs payloads—using Snowflake-managed encryption:
-- Stage to store PDFs
CREATE OR REPLACE STAGE test_stage
ENCRYPTION = (TYPE = 'snowflake_sse');
-- Stage for ML Jobs payloads
CREATE OR REPLACE STAGE payload_stage
ENCRYPTION = (TYPE = 'snowflake_sse');
2-2. Create a Compute Pool
Snowflake ML Jobs run on a dedicated Compute Pool (e.g. MY_COMPUTE_POOL).
See the official docs on CREATE COMPUTE POOL for detailed syntax and options.
2-3. Dependencies
Only PyMuPDF needs to be fetched from PyPI—grant your PYPI_ACCESS_INTEGRATION accordingly. If you haven’t yet set up external network access for your account, see Snowflake Notebooks: Set up external access.
3. Implementing ML Jobs
3-1. Creating the Function to Convert PDFs to Images
Define a @remote function that Snowflake will register and execute in parallel on your Compute Pool. We recommend calling get_active_session() at the top of your function when using Snowpark APIs.
from snowflake.ml.jobs import remote
import fitz, os, traceback
compute_pool = "MY_COMPUTE_POOL"
@remote(
compute_pool,
stage_name="payload_stage", # Temporary storage for generated images
pip_requirements=['PyMuPDF'], # Dependency libraries
external_access_integrations=['PYPI_ACCESS_INTEGRATION']
)
def convert_pdfs_to_images(stage_name, file_name,
temp_input="tmp/input/",
temp_output="tmp/output/"):
"""
Converts the specified PDF file to images and saves them to the output directory.
Parameters:
- stage_name (str): Name of the stage (e.g. '@pdf/')
- file_list (list): List of PDF filenames to convert
- temp_input (str): Local directory for input files
- temp_output(str): Local directory for output images
Returns:
- dict: {
'success': True|False,
'output_files': [...],
'errors': [...]
}
"""
session = get_active_session()
os.makedirs(temp_input, exist_ok=True)
os.makedirs(temp_output, exist_ok=True)
file_list = [file_name]
output_files = []
errors = []
for file_name in file_list:
try:
# Download PDF from stage
session.file.get(os.path.join(stage_name, file_name), temp_input)
base_name = os.path.splitext(file_name)[0]
doc = fitz.open(os.path.join(temp_input, file_name))
for i, page in enumerate(doc):
pix = page.get_pixmap()
output_filename = f"{base_name}-page_{i+1}.png"
output_path = os.path.join(temp_output, output_filename)
pix.save(output_path)
# Upload each image back to stage (no compression)
session.file.put(
output_path,
os.path.join(stage_name, 'output_image'),
auto_compress=False
)
output_files.append(output_filename)
except Exception as e:
error_message = f"Error processing {file_name}\n{traceback.format_exc()}"
print(error_message)
errors.append({'file': file_name, 'error': str(e)})
return {
'success': len(errors) == 0,
'output_files': output_files,
'errors': errors
}
3-2. Bulk Execution & Monitoring
I used CreditConsumptionTable and download it to my local. Then,
the PDF files was already in @test_stage, use a directory table to list them and invoke the function asynchronously:
# List all PDFs in test_stage
stage = '@test_stage'
df = session.sql(
"SELECT * FROM directory(@test_stage) WHERE relative_path LIKE ('%.pdf')"
).to_pandas()
# Submit one ML Job per PDF
for f in df['RELATIVE_PATH']:
job = convert_pdfs_to_images(stage, f)
3-3. Status Management
Manage and monitor jobs via the returned MLJob object:
job.id # Job ID
job.status # RUNNING, PENDING, etc.
job.get_logs()# Fetch Kubernetes logs
# List all jobs
from snowflake.ml.jobs import list_jobs
print(list_jobs())
# For synchronous execution (e.g. in Airflow), wait for completion:
job.result()
4. Image Analysis with Snowflake Cortex COMPLETE Multimodal
4-1. What is COMPLETE Multimodal?
Snowflake Cortex’s SNOWFLAKE.CORTEX.COMPLETE function now supports image inputs in addition to text. In a single SQL statement you can generate captions, classify images, compare them, extract entities, read graphs/tables, and more—no extra infra.
As of April 2025, supported models include claude-3-5-sonnet and pixtral-large.
4-2. Example Extraction for a Single Image
The 2nd page on CreditConsumptionTable.pdf is used as an example.
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'pixtral-large',
'Extract all text information from the input image in JSON format',
TO_FILE('@test_stage', 'consumptiontable-page_2.png')
) AS result;
output example:
Table 1(b) Snowflake Credit Table for Virtual Warehouse Services, Snowpark Optimized Warehouses
| Resource Constraints | XS | S | M | L | Credits Per Hour | XL | 2XL | 3XL | 4XL | 5XL | 6XL |
|----------------------|----|---|---|---|------------------|----|-----|-----|-----|-----|-----|
| MEMORY: 1x, vCPU: 1 | 1.00 | 2.00 | 4.00 | 8.00 | 16.00 | 32.00 | 64.00 | 128.00 | 256.00 | - | - |
| MEMORY: 16X, vCPU: 1 | 1.00 | 2.00 | 4.00 | 8.00 | 17.60 | 35.20 | 70.40 | 140.80 | 281.60 | 384.00 | 768.00 |
| MEMORY: 16X, vCPU: 2 | - | - | 6.00 | 12.00 | 24.00 | 48.00 | 96.00 | 192.00 | 384.00 | - | - |
| MEMORY: 64X, vCPU: 8 | - | - | 6.25 | 12.50 | 25.00 | 50.00 | 100.00 | 200.00 | - | - | - |
| MEMORY: 64X, vCPU: 16 | - | - | - | 16.00 | 32.00 | 64.00 | 128.00 | 256.00 | - | - | - |
4-3. Processing Multiple Pages in Bulk
Parallel-infer hundreds of images with one query:
WITH pages AS (
SELECT relative_path
FROM directory(@test_stage)
WHERE relative_path ILIKE '%-page_%.png'
)
SELECT
relative_path,
SNOWFLAKE.CORTEX.COMPLETE(
'pixtral-large',
'Extract all text information from the input image in JSON format',
TO_FILE('@test_stage', relative_path)
) AS result
FROM pages;
5. Persisting the Results
Store all extracted text JSON into a Snowflake table for downstream RAG, analytics, or audit logs:
CREATE OR REPLACE TABLE extract_text_raw (
relative_path STRING,
extracted_json VARIANT,
processed_at TIMESTAMP_TZ DEFAULT CURRENT_TIMESTAMP()
);
INSERT INTO extract_text_raw
WITH pages AS (
SELECT relative_path
FROM directory(@test_stage)
WHERE relative_path ILIKE '%-page_%.png'
)
SELECT
relative_path,
SNOWFLAKE.CORTEX.COMPLETE(
'pixtral-large',
'Extract all text information from the input image in JSON format',
TO_FILE('@test_stage', relative_path)
) AS extracted_json
FROM pages;
6. Summary
- Unified stage: Use test_stage for both input PDFs and intermediate images via ML Jobs.
- Zero-infra image-to-text: COMPLETE Multimodal lets you extract text from images without any external APIs or infrastructure.
- End-to-end in Snowflake: Persist results in a table and integrate with RAG, visualization, or audit logging—all within the Snowflake Data Cloud.
Because the entire workflow—data ingestion → multimodal AI inference → data utilization—runs on Snowflake, you don’t need AWS Lambda runtimes or external GPUs to operate sophisticated visual-AI pipelines easily and cost-effectively.


