![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)











































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























































.png?#)






































.webp?#)
























































































![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![What’s new in Android’s April 2025 Google System Updates [U: 4/14]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)


















































































































การใช้ KMeans Clustering ในการแบ่งกลุ่มลูกค้า เพื่อการตลาดที่มีประสิทธิภาพ โดยใช้ Python
การทำความเข้าใจลูกค้าเป็นสิ่งสำคัญสำหรับทุกธุรกิจ ไม่ว่าจะเป็นการปรับปรุงผลิตภัณฑ์หรือการพัฒนาการตลาดที่เหมาะสมกับกลุ่มลูกค้าแต่ละประเภท วิธีที่สามารถใช้เพื่อแบ่งกลุ่มลูกค้าได้อย่างมีประสิทธิภาพ คือ KMeans Clustering ซึ่งเป็นหนึ่งในเทคนิคของ Machine Learning ที่ใช้ในการแบ่งกลุ่มข้อมูลที่มีลักษณะคล้ายกันออกเป็นกลุ่มๆ ในบทความนี้ เราจะมาดูวิธีการใช้ KMeans Clustering เพื่อแบ่งกลุ่มลูกค้าในธุรกิจโดยใช้ Python กัน เราจะใช้ Google Colab ในการรันโค้ด โดย dataset ที่เราจะใช้เป็นตัวอย่างคือ Mall_Customers.csv Download Dataset ลูกค้าในห้างสรรพสินค้า https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python/version/1 โดยพิจารณาจาก Spending_Score โดยมีคะแนน 1 ถึง 100 ให้ลูกค้าทุกคนในห้างสรรพสินค้า โดยดูจากประวัติการซื้อ และจำนวนสินค้า ตลอดจนมูลค่าที่ซื้อของแต่ละคน เราจะมาแบ่งกลุ่มลูกค้าจาก รายได้ และคะแนน Spending_Score ของพวกเขาว่ามีกี่กลุ่มที่แตกต่างกัน ขั้นตอนที่ 1: นำเข้าข้อมูล Data Mall_Customers ตัวอย่างของข้อมูลสามารถ copy code และโหลดได้ตามนี้เลย #https://www.kaggle.com/funxexcel/pl-sklearn-k-means-example from google.colab import files uploaded = files.upload() กด Choose file และ เลือกไฟล์ Mall_Customers.csv ผลที่ได้ ขั้นตอนที่ 2: อ่านไฟล์ Mall_Customers.csv ด้วย pandas import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt df = pd.read_csv('Mall_Customers.csv') df.shape ทำการเตรียมข้อมูล โดยเปลี่ยนชื่อ column ให้เข้าใจง่ายขึ้น df.rename(columns={'Annual Income (k$)': 'Income','Spending Score (1-100)': 'Spending_Score'}, inplace = True) df.head() ผลที่ได้ ขั้นตอนที่ 3: หาค่า Inertia โดยใช้ Kmeans algorithm ทำการรัน KMeans ระหว่างจำนวน 2 ถึง 9 กลุ่ม from sklearn.cluster import KMeans col = ['Age', 'Income'] X = df[col] Y = df['Spending_Score'] ssd = [] for k in range(2, 10): m = KMeans(n_clusters=k, random_state=42) m.fit(X) ssd.append([k, m.inertia_]) ssd ขั้นตอนที่ 4: แปลงผลลัพธ์ให้เป็น DataFrame เพื่อดูง่ายขึ้น dd=pd.DataFrame (ssd, columns=['k', 'ssd']) dd จำนวนคลัสเตอร์ k ตั้งแต่ 2 ถึง 9 ได้ค่า SSD หรือ Inertia ดังภาพ ขั้นตอนที่ 5: ทำการหา percent of change โดยเก็บไว้ใน คอลัมน์ ชื่อ pct_chg dd['pct_chg']=dd['ssd'].pct_change() * 100 dd ผลที่ได้ ขั้นตอนที่ 6: ทำการสร้างกราฟของแต่ละ k เพื่อหา optimal point โดยแสดง percent of change ของ k ก่อนหน้าทุกจุด plt.figure(figsize=(8, 5)) plt.plot(dd['k'], dd['ssd'], linestyle='--', marker='o') for index, row in dd.iterrows(): plt.text(row['k'] + 0.02, row['ssd'] + 0.02, f'{row["pct_chg"]:.2f}', fontsize=15) รูปกราฟที่ได้ จากขั้นตอนที่ 6 นี้จะเห็นได้ชัดว่า Elbow Plot นี้ สามารถสรุปได้ว่า k = 5 เป็นจุด Optimal Point เพราะเป็นจุดแรกที่ค่า pct_chg ลดลงจนใกล้คงที่ หรือลดลงน้อยลงอย่างมีนัยสำคัญเป็นครั้งแรก เรียกว่า ข้อศอก (Elbow Point) การเลือก k = 5 จะได้การแบ่งกลุ่มที่ดีและเหมาะสมที่สุดสำหรับข้อมูลนี้ ขั้นตอนที่ 7: สร้างโมเดล KMeans และฝึกโมเดล เราจะใช้ KMeans เพื่อแบ่งข้อมูลออกเป็น 5 กลุ่ม และทำการฝึกโมเดลด้วยข้อมูล Spending_Score และ Income โมเดลจะแสดงค่า centroid ของแต่ละกลุ่ม import sklearn.cluster as cluster # We will use 2 Variables for this example kmeans = cluster.KMeans(n_clusters=5,init="k-means++") kmeans = kmeans.fit(df[['Spending_Score', 'Income']]) kmeans.cluster_centers_ df ['Clusters'] = kmeans.labels_ df.head() ขั้นตอนที่ 8: สร้าง กราฟ scatter point ทำการสร้างจุดศูนย์กลางของกลุ่ม ด้วย kmeans.cluster_centers_[:, 0] ซึ่งคือ x และ kmeans.cluster_centers_[:, 1] ซึ่งคือ y เพื่อดูจำนวนกลุ่ม plt.figure(figsize=(10, 6)) # วาด scatterplot แบบมีสีตามคลัสเตอร์ sns.scatterplot(x="Spending_Score", y="Income", hue='Clusters', data=df) # วาด centroid ของ k-means plt.scatter( kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='x', s=200, c='black', label='Centroids' ) plt.title('KMeans Clustering') จากรูป เห็นชัดเจนว่ามี 5 กลุ่ม แสดงว่า วิธี elbow method ใช้ได้ผล โดยหาจุด optimal point ก่อน แล้วจึงทำการจัดกลุ่ม ตัวอย่างเพิ่มเติม เราจะลองใช้ตัวอย่างข้อมูลอื่นบ้าง เช่น ข้อมูลการสั่งอาหารของลูกค้า (order dataset) ที่เป็นธุรกิจออนไลน์หรือแพลตฟอร์มที่ให้บริการผ่านแอปพลิเคชัน โดยจะใช้ KMeans Clustering ที่สามารถช่วยให้ตัดสินใจธุรกิจได้อย่างมีประสิทธิภาพ ไม่ว่าจะเป็นการทำโปรโมชั่น การแบ่งกลุ่มเป้าหมาย หรือการปรับปรุงสินค้าและบริการ ขั้นตอนที่ 1: นำเข้าข้อมูล order ตัวอย่างของข้อมูลสามารถ copy code และโหลดได้ตามนี้เลย import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt url = "https://raw.githubusercontent.com/Yaowamanymc/food-order-data/refs/heads/main/food_order_data.csv" order = pd.read_csv(url, index_col=0) order.shape ขั้นตอนที่ 2: จัดการข้อมูลให้เหมาะสม หรือเตรียมข้อมูลให้พร้อมใช้งาน เนื่องจากผู้ใช้งานแต่ละคนอาจมีหลายรายการสั่งซื้อ เราจึงรวมข้อมูลทั้งหมดของแต่ละคนให้อยู่ในบรรทัดเดียว โค้ดที่ใช้จัดการข้อมูลมีดังนี้: user_order = order.groupby('user_id').agg({'order_count': 'sum','order_price': 'sum','age': 'mean'}).reset_ind

การทำความเข้าใจลูกค้าเป็นสิ่งสำคัญสำหรับทุกธุรกิจ ไม่ว่าจะเป็นการปรับปรุงผลิตภัณฑ์หรือการพัฒนาการตลาดที่เหมาะสมกับกลุ่มลูกค้าแต่ละประเภท วิธีที่สามารถใช้เพื่อแบ่งกลุ่มลูกค้าได้อย่างมีประสิทธิภาพ คือ KMeans Clustering ซึ่งเป็นหนึ่งในเทคนิคของ Machine Learning ที่ใช้ในการแบ่งกลุ่มข้อมูลที่มีลักษณะคล้ายกันออกเป็นกลุ่มๆ
ในบทความนี้ เราจะมาดูวิธีการใช้ KMeans Clustering เพื่อแบ่งกลุ่มลูกค้าในธุรกิจโดยใช้ Python กัน เราจะใช้ Google Colab ในการรันโค้ด โดย dataset ที่เราจะใช้เป็นตัวอย่างคือ Mall_Customers.csv
Download Dataset ลูกค้าในห้างสรรพสินค้า https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python/version/1
โดยพิจารณาจาก Spending_Score โดยมีคะแนน 1 ถึง 100 ให้ลูกค้าทุกคนในห้างสรรพสินค้า โดยดูจากประวัติการซื้อ และจำนวนสินค้า ตลอดจนมูลค่าที่ซื้อของแต่ละคน
เราจะมาแบ่งกลุ่มลูกค้าจาก รายได้ และคะแนน Spending_Score ของพวกเขาว่ามีกี่กลุ่มที่แตกต่างกัน
ขั้นตอนที่ 1: นำเข้าข้อมูล Data Mall_Customers
ตัวอย่างของข้อมูลสามารถ copy code และโหลดได้ตามนี้เลย
#https://www.kaggle.com/funxexcel/pl-sklearn-k-means-example
from google.colab import files
uploaded = files.upload()
กด Choose file และ เลือกไฟล์ Mall_Customers.csv
ผลที่ได้
ขั้นตอนที่ 2: อ่านไฟล์ Mall_Customers.csv ด้วย pandas
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('Mall_Customers.csv')
df.shape
ทำการเตรียมข้อมูล โดยเปลี่ยนชื่อ column ให้เข้าใจง่ายขึ้น
df.rename(columns={'Annual Income (k$)': 'Income','Spending Score (1-100)': 'Spending_Score'}, inplace = True)
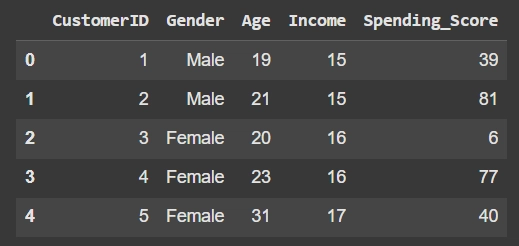
df.head()
ผลที่ได้
ขั้นตอนที่ 3: หาค่า Inertia โดยใช้ Kmeans algorithm
ทำการรัน KMeans ระหว่างจำนวน 2 ถึง 9 กลุ่ม
from sklearn.cluster import KMeans
col = ['Age', 'Income']
X = df[col]
Y = df['Spending_Score']
ssd = []
for k in range(2, 10):
m = KMeans(n_clusters=k, random_state=42)
m.fit(X)
ssd.append([k, m.inertia_])
ssd
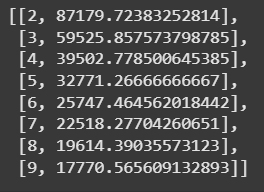
ขั้นตอนที่ 4: แปลงผลลัพธ์ให้เป็น DataFrame เพื่อดูง่ายขึ้น
dd=pd.DataFrame (ssd, columns=['k', 'ssd'])
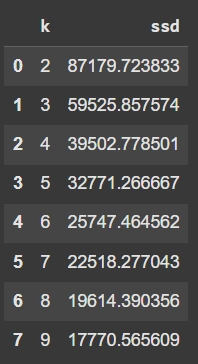
dd
จำนวนคลัสเตอร์ k ตั้งแต่ 2 ถึง 9 ได้ค่า SSD หรือ Inertia ดังภาพ
ขั้นตอนที่ 5: ทำการหา percent of change
โดยเก็บไว้ใน คอลัมน์ ชื่อ pct_chg
dd['pct_chg']=dd['ssd'].pct_change() * 100
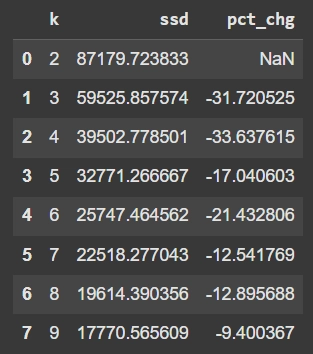
dd
ผลที่ได้
ขั้นตอนที่ 6: ทำการสร้างกราฟของแต่ละ k เพื่อหา optimal point โดยแสดง percent of change ของ k ก่อนหน้าทุกจุด
plt.figure(figsize=(8, 5))
plt.plot(dd['k'], dd['ssd'], linestyle='--', marker='o')
for index, row in dd.iterrows():
plt.text(row['k'] + 0.02,
row['ssd'] + 0.02,
f'{row["pct_chg"]:.2f}',
fontsize=15)
รูปกราฟที่ได้
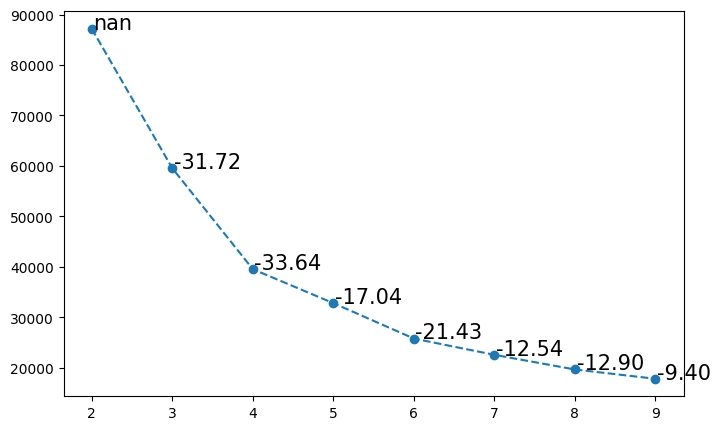
จากขั้นตอนที่ 6 นี้จะเห็นได้ชัดว่า Elbow Plot นี้ สามารถสรุปได้ว่า
- k = 5 เป็นจุด Optimal Point เพราะเป็นจุดแรกที่ค่า pct_chg ลดลงจนใกล้คงที่ หรือลดลงน้อยลงอย่างมีนัยสำคัญเป็นครั้งแรก เรียกว่า ข้อศอก (Elbow Point)
- การเลือก k = 5 จะได้การแบ่งกลุ่มที่ดีและเหมาะสมที่สุดสำหรับข้อมูลนี้
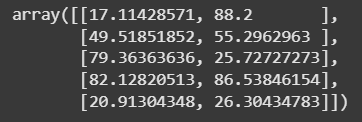
ขั้นตอนที่ 7: สร้างโมเดล KMeans และฝึกโมเดล
เราจะใช้ KMeans เพื่อแบ่งข้อมูลออกเป็น 5 กลุ่ม และทำการฝึกโมเดลด้วยข้อมูล Spending_Score และ Income โมเดลจะแสดงค่า centroid ของแต่ละกลุ่ม
import sklearn.cluster as cluster
# We will use 2 Variables for this example
kmeans = cluster.KMeans(n_clusters=5,init="k-means++")
kmeans = kmeans.fit(df[['Spending_Score', 'Income']])
kmeans.cluster_centers_
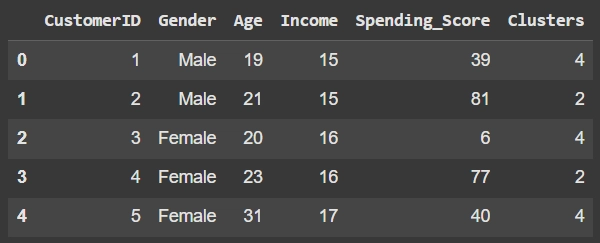
df ['Clusters'] = kmeans.labels_
df.head()
ขั้นตอนที่ 8: สร้าง กราฟ scatter point
ทำการสร้างจุดศูนย์กลางของกลุ่ม ด้วย kmeans.cluster_centers_[:, 0] ซึ่งคือ x
และ kmeans.cluster_centers_[:, 1] ซึ่งคือ y เพื่อดูจำนวนกลุ่ม
plt.figure(figsize=(10, 6))
# วาด scatterplot แบบมีสีตามคลัสเตอร์
sns.scatterplot(x="Spending_Score", y="Income", hue='Clusters', data=df)
# วาด centroid ของ k-means
plt.scatter(
kmeans.cluster_centers_[:, 0],
kmeans.cluster_centers_[:, 1],
marker='x',
s=200,
c='black',
label='Centroids'
)
plt.title('KMeans Clustering')
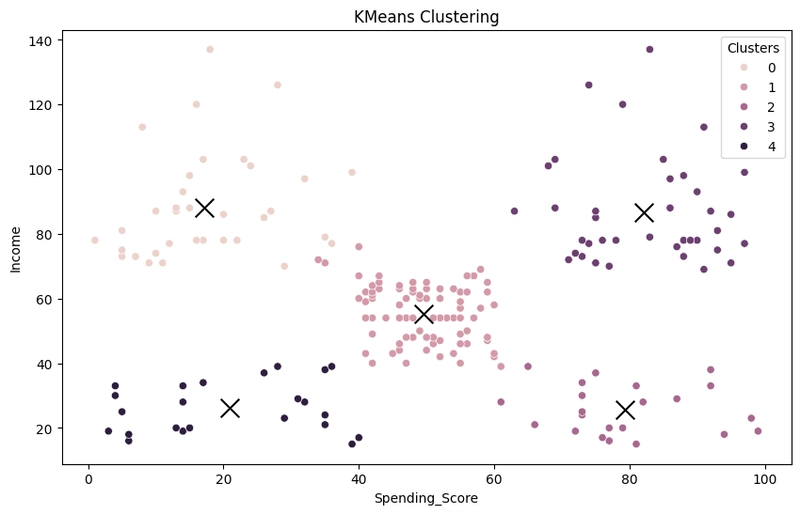
จากรูป เห็นชัดเจนว่ามี 5 กลุ่ม แสดงว่า วิธี elbow method ใช้ได้ผล โดยหาจุด optimal point ก่อน แล้วจึงทำการจัดกลุ่ม
ตัวอย่างเพิ่มเติม
เราจะลองใช้ตัวอย่างข้อมูลอื่นบ้าง เช่น ข้อมูลการสั่งอาหารของลูกค้า (order dataset) ที่เป็นธุรกิจออนไลน์หรือแพลตฟอร์มที่ให้บริการผ่านแอปพลิเคชัน โดยจะใช้ KMeans Clustering ที่สามารถช่วยให้ตัดสินใจธุรกิจได้อย่างมีประสิทธิภาพ ไม่ว่าจะเป็นการทำโปรโมชั่น การแบ่งกลุ่มเป้าหมาย หรือการปรับปรุงสินค้าและบริการ
ขั้นตอนที่ 1: นำเข้าข้อมูล order
ตัวอย่างของข้อมูลสามารถ copy code และโหลดได้ตามนี้เลย
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
url = "https://raw.githubusercontent.com/Yaowamanymc/food-order-data/refs/heads/main/food_order_data.csv"
order = pd.read_csv(url, index_col=0)
order.shape
ขั้นตอนที่ 2: จัดการข้อมูลให้เหมาะสม หรือเตรียมข้อมูลให้พร้อมใช้งาน
เนื่องจากผู้ใช้งานแต่ละคนอาจมีหลายรายการสั่งซื้อ เราจึงรวมข้อมูลทั้งหมดของแต่ละคนให้อยู่ในบรรทัดเดียว
โค้ดที่ใช้จัดการข้อมูลมีดังนี้:
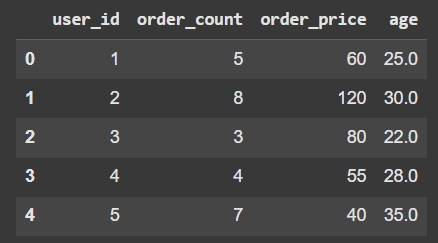
user_order = order.groupby('user_id').agg({'order_count': 'sum','order_price': 'sum','age': 'mean'}).reset_index()
user_order.head()
ผลที่ได้
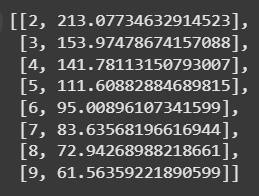
ขั้นตอนที่ 3:หาค่า K ที่เหมาะสม
ลองแบ่งกลุ่มตั้งแต่ 2 ถึง 9 กลุ่ม แล้วเก็บค่า SSD
from sklearn.cluster import KMeans
# สเกลข้อมูล
scaler = StandardScaler()
X_scaled = scaler.fit_transform(user_order[['order_count', 'order_price', 'age']])
# เก็บค่า inertia สำหรับแต่ละ k
ssd = [] # สร้างลิสต์เก็บค่า SSD
for k in range(2, 10):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X_scaled)
ssd.append([k, kmeans.inertia_]) # ค่า inertia
ssd
ผลที่ได้
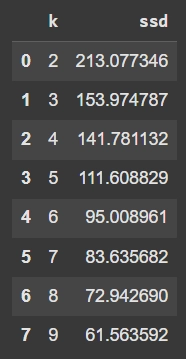
แปลงผลลัพธ์ให้เป็น DataFrame เพื่อดูง่ายขึ้น
dd=pd.DataFrame (ssd, columns=['k', 'ssd'])
dd
ผลที่ออกมา
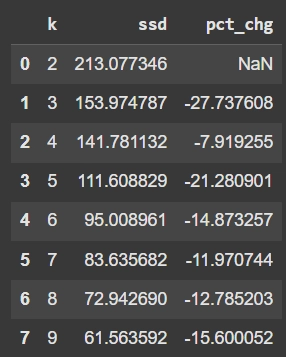
ขั้นตอนที่ 4: ทำการหา percent of change
คำนวณการเปลี่ยนแปลงของ SSD เป็นเปอร์เซ็นต์
dd['pct_chg'] = dd['ssd'].pct_change() * 100 # เปลี่ยนแปลงเป็นเปอร์เซ็นต์
dd
ผลที่ได้
ขั้นตอนที่ 5: สร้างกราฟเพื่อเลือกจำนวนกลุ่มที่เหมาะสม (Elbow Plot)
ในการแบ่งกลุ่มข้อมูลด้วย K-Means เราต้องกำหนดว่าอยากแบ่งออกเป็นกี่กลุ่ม(K) โดยการแสดงค่า SSD ของแต่ละ K
plt.figure(figsize=(8, 5))
plt.plot(dd['k'], dd['ssd'], linestyle='--', marker='o', color='b')
for index, row in dd.iterrows():
plt.text(row['k'] + 0.1,
row['ssd'] - 0.02,
f'{row["ssd"]:.2f}',
fontsize=12, color='red')
plt.title('Elbow Method SSD')
plt.xlabel('Number of clusters (K)')
plt.ylabel('SSD')
plt.grid(True)
plt.show()
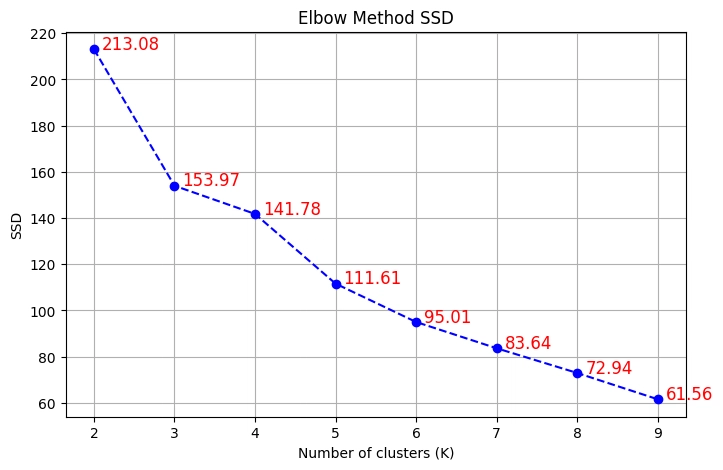
จากขั้นตอนที่ 5 นี้จะเห็นได้ชัดว่า Elbow Plot นี้ สามารถสรุปได้ว่า
optimal point = 5 เพราะเป็นจุดที่ SSD ลดลงช้าลงอย่างชัดเจนเป็นครั้งแรก
การเลือก k = 5 จะให้ผลลัพธ์ของการแบ่งกลุ่มที่เหมาะสมและมีประสิทธิภาพในการแยกลูกค้าออกเป็นกลุ่ม ๆ
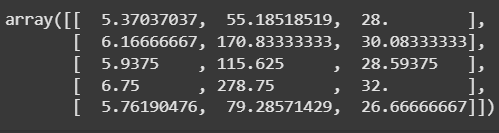
ขั้นตอนที่ 6: สร้างโมเดล KMeans และฝึกโมเดล
เราจะใช้ KMeans เพื่อแบ่งข้อมูลออกเป็น 5 กลุ่ม และทำการฝึกโมเดลด้วยข้อมูล Spending_Score และ Income โมเดลจะแสดงค่า centroid ของแต่ละกลุ่ม
import sklearn.cluster as cluster
kmeans = cluster.KMeans(n_clusters=5, init="k-means++")
kmeans = kmeans.fit(order[['order_count', 'order_price', 'age']])
kmeans.cluster_centers_
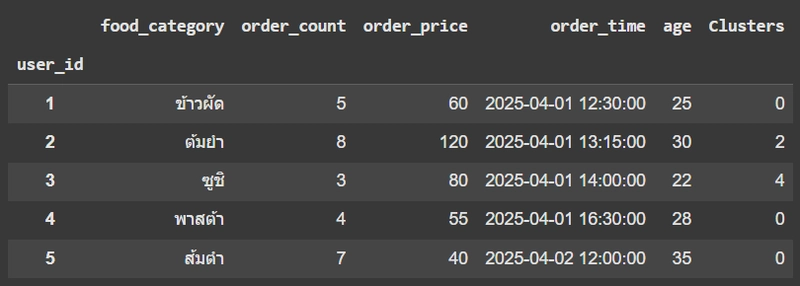
order ['Clusters'] = kmeans.labels_
order.head()
ขั้นตอนที่ 7: สร้าง กราฟ Scatter Plot
เราจะสร้างกราฟ Scatter Plot เพื่อแสดงจุดศูนย์กลางของแต่ละกลุ่ม (centroids) โดยใช้ค่า x และ y จาก kmeans.cluster_centers_
order['Cluster'] = kmeans.labels_
plt.figure(figsize=(10, 6))
sns.scatterplot(x="order_count", y="order_price", hue="Cluster", data=order, palette='Set2', s=100, edgecolor='black')
plt.scatter(
kmeans.cluster_centers_[:, 0],
kmeans.cluster_centers_[:, 1],
marker='X',
s=300,
c='red',
label='Centroids'
)
plt.title('KMeans Clustering with Centroids')
plt.xlabel('Order Count')
plt.ylabel('Order Price')
plt.legend()
plt.show()
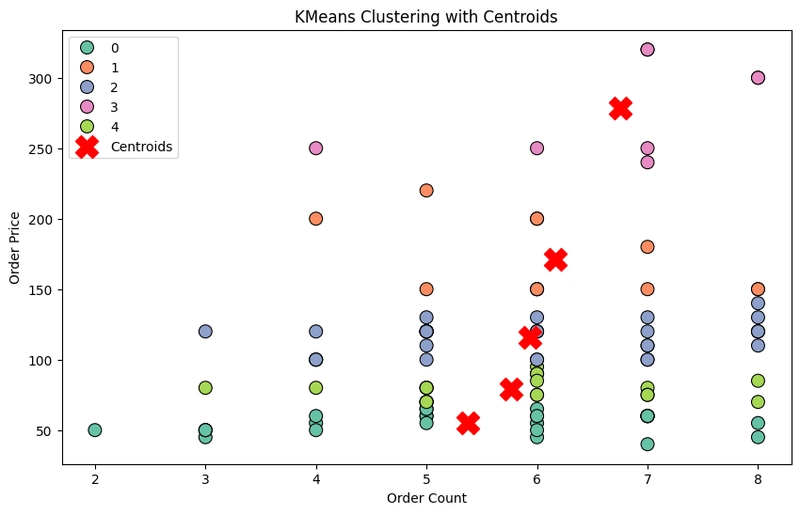
จากรูปที่เห็น ชัดเจนว่ามี 5 กลุ่ม แสดงว่า วิธี elbow method ใช้ได้ผล โดยหาจุด optimal point ก่อน แล้วจึงทำการจัดกลุ่ม
กลุ่มมีลักษณะแตกต่างกัน เช่น
- กลุ่มสีเขียวมินต์ มี Order Count ต่ำ และ Order Price ต่ำ → อาจเป็น กลุ่มลูกค้าทั่วไปที่ไม่ค่อยซื้อบ่อยและซื้อน้อย
- กลุ่มสีชมพู มี Order Count สูง และ Order Price สูง → อาจเป็น ลูกค้าพรีเมียม/ขาประจำ
- กลุ่มอื่น ๆ เช่น สีส้ม/ฟ้า/เขียวอ่อน อาจมีลักษณะพฤติกรรมเฉพาะ เช่น ซื้อบ่อยแต่ยอดน้อย หรือซื้อน้อยแต่มูลค่าสูง
โดยกลุ่มแต่ละกลุ่มมีลักษณะของพฤติกรรมที่แตกต่างกันทั้งในแง่ของ Order Count และ Order Price และมี จุดศูนย์กลาง (Centroid) สามารถจำแนกกลุ่มลูกค้าได้อย่างชัดเจน
สรุปผล
สำหรับบทความนี้ เราได้แสดงตัวอย่างการทำ KMeans Clustering จากข้อมูล 2 ชุด ได้แก่ข้อมูลของ Mall_Customers และ Order เราสามารถลองเปลี่ยนตัวแปรเพื่อสร้างสมการ KMeans Clustering แบบอื่นๆ อีกได้ด้วยตัวเอง ลองทำกันดูนะคะ