![How to Build an AI Assistant with Keith Moehring [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series%20%281%29.png)






































































































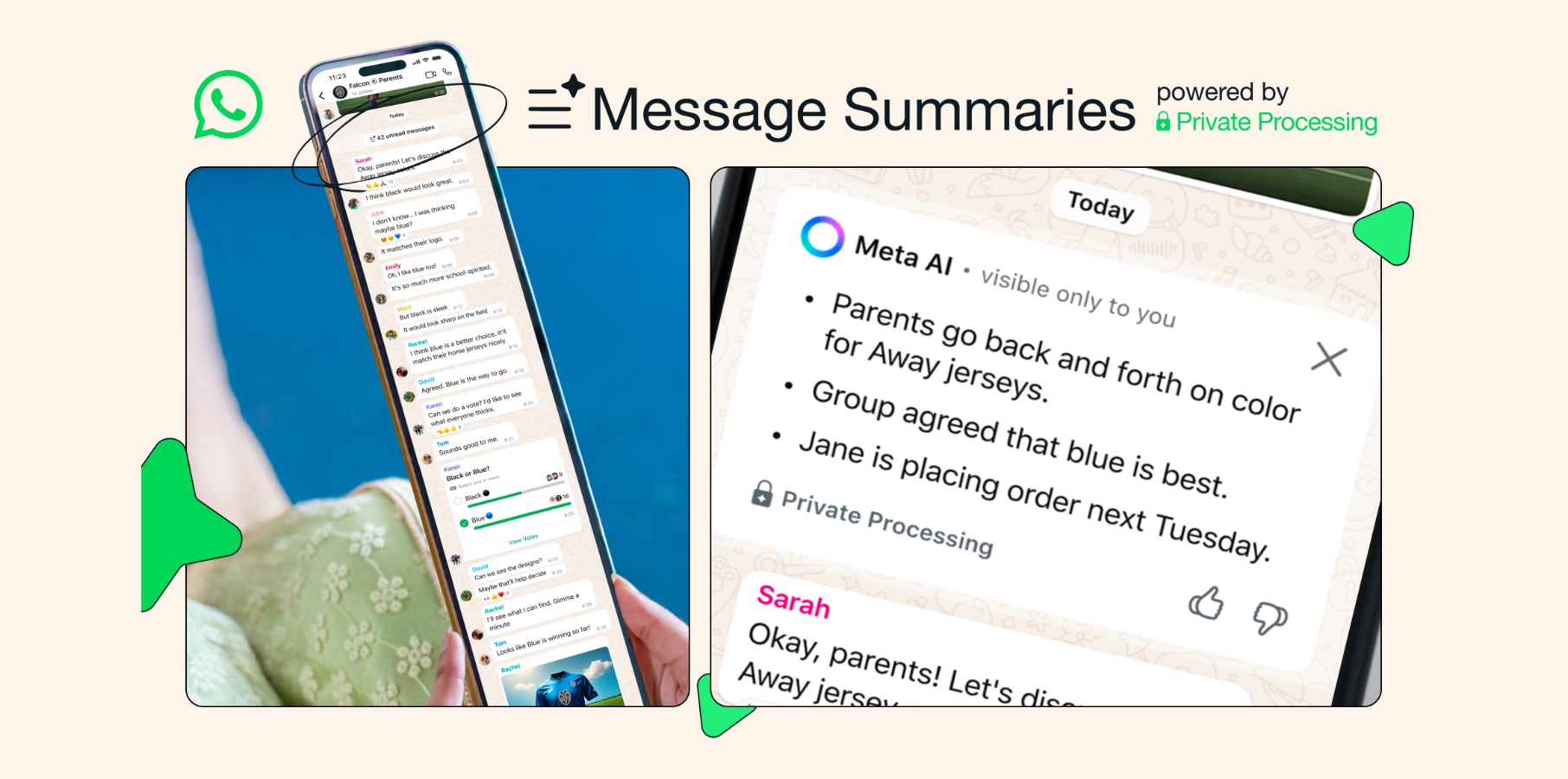
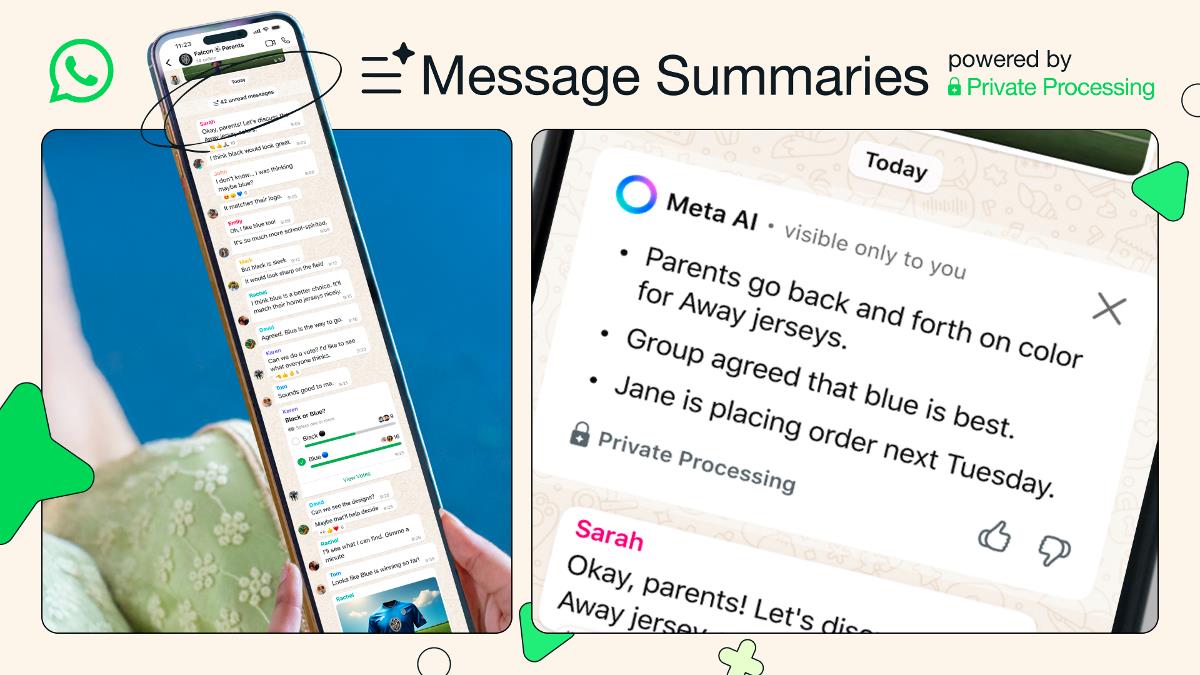
![[The AI Show Episode 156]: AI Answers - Data Privacy, AI Roadmaps, Regulated Industries, Selling AI to the C-Suite & Change Management](https://www.marketingaiinstitute.com/hubfs/ep%20156%20cover.png)
![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)



































































































































































































































































_incamerastock_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brain_light_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![Nothing Phone (3) has a 50MP ‘periscope’ telephoto lens – here are the first samples [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/nothing-phone-3-telephoto.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













































































Tree vs Trie: Understanding the Differences and Use Cases
Introduction In computer science, trees and tries are foundational data structures that help organise and retrieve data efficiently. While they may look similar at first glance (both are hierarchical), their purposes, performance characteristics, and use cases are quite different. Understanding the distinction is essential for: Building efficient search engines, autocomplete systems, and compilers. Performing optimized lookups and prefix matching. Making the right choice for data modeling and algorithm design. Let’s dive deeper into each of them. What is a Tree? A tree is a non-linear hierarchical data structure consisting of nodes, with one node designated as the root. Each node may have zero or more child nodes. Basic Properties: Each child node has only one parent. No cycles (i.e., it’s acyclic). Trees can be binary (each node has at most 2 children), or n-ary. Types of Trees Type Description Binary Tree Each node has up to 2 children (left and right). Binary Search Tree (BST) Left child < parent < right child. Used for ordered data. AVL Tree / Red-Black Tree Self-balancing BSTs for faster operations. Heap Used in priority queues, with specific parent-child value relationships. Use Cases Organising hierarchical data (like file systems). Efficient searching and sorting (e.g., in BSTs). Expression trees in compilers. Example A Binary Search Tree (BST) example: 10 / \ 5 15 / \ \ 3 7 20 Search for 7: Start at root → left (5) → right (7). Operations like search, insert, delete: O(log n) (average), O(n) (worst-case in unbalanced tree). What is a Trie? A Trie (pronounced "try") is a specialised tree used for storing strings where each node represents a character of a word. Unlike a typical tree, paths from the root represent prefixes. Key Features The root is usually empty. Each edge represents a character. Nodes can have flags to mark the end of a word. Nodes are shared among words with common prefixes. Example Consider inserting "cat", "cap", and "car": root └── c └── a ├── t (word ends) ├── p (word ends) └── r (word ends) Each level represents one character. Common prefixes like ca are stored only once, making searches faster. Operations and Time Complexities Operation Time Insert O(m) where m = length of word Search O(m) Prefix Match O(m) Note: Time is independent of the number of words, unlike searching in an array. Use Cases Autocomplete systems (Google Search suggestions). Spell checkers. IP routing (prefix matching). Dictionary implementations. Key Differences Between Tree and Trie Let’s compare Trees and Tries across various dimensions to understand their core differences: | Feature | Tree | Trie | |---------|----------|----------| | Purpose | General-purpose data storage | Efficient retrieval and prefix matching of strings | | Node Content| Can store any data type | Typically stores a single character per node | | Depth | Depends on the structure of data | Depends on the length of the strings | | Search Time | O(log n) (in balanced BST) | O(m), where m = length of the string | | Memory Usage| Efficient for general data | Higher, as each character takes a node (can be sparse) | | Redundancy | Lower redundancy | Shared prefixes reduce redundancy, but can be node-heavy | | Flexibility | Versatile (numbers, objects, etc.) | Primarily for strings or sequences | Example Breakdown Tree: Great for sorted data like numbers, where binary search helps quickly find values. Trie: Built specifically to handle multiple words with shared prefixes (e.g., interview, internet, internal), making lookups extremely fast. Use Cases Use a Tree when You must store and query ordered numeric or object-based data. You’re implementing binary search, sorting, or traversals. Your data represents hierarchies (like a file system, HTML DOM tree, or organisational chart). Examples: Binary Search Trees for searching numbers. Expression Trees in Compilers. Parse Trees in Language Processing. Use a Trie when Your data is mostly textual and you need fast prefix-based search. You want to implement features like auto-complete, spell checkers, or search suggestions. You’re dealing with routing prefixes or dictionary compression. Examples: Google Search’s auto-suggestion. IP routing using Longest Prefix Match. Efficient word filtering or blacklisting. Visual Comparison: Tree vs Trie Trees are general-purpose, storing a wide range of data. Tries are optimized for string operations, especially when working with a large volume of similar words. Code Examples Basic Tree Implementation (Binary Search Tree Insertion) class TreeNode:

Introduction
In computer science, trees and tries are foundational data structures that help organise and retrieve data efficiently. While they may look similar at first glance (both are hierarchical), their purposes, performance characteristics, and use cases are quite different.
Understanding the distinction is essential for:
- Building efficient search engines, autocomplete systems, and compilers.
- Performing optimized lookups and prefix matching.
- Making the right choice for data modeling and algorithm design.
Let’s dive deeper into each of them.
What is a Tree?
A tree is a non-linear hierarchical data structure consisting of nodes, with one node designated as the root. Each node may have zero or more child nodes.
Basic Properties:
- Each child node has only one parent.
- No cycles (i.e., it’s acyclic).
- Trees can be binary (each node has at most 2 children), or n-ary.
Types of Trees
| Type | Description |
|---|---|
| Binary Tree | Each node has up to 2 children (left and right). |
| Binary Search Tree (BST) | Left child < parent < right child. Used for ordered data. |
| AVL Tree / Red-Black Tree | Self-balancing BSTs for faster operations. |
| Heap | Used in priority queues, with specific parent-child value relationships. |
Use Cases
- Organising hierarchical data (like file systems).
- Efficient searching and sorting (e.g., in BSTs).
- Expression trees in compilers.
Example
A Binary Search Tree (BST) example:
10
/ \
5 15
/ \ \
3 7 20
- Search for 7: Start at root → left (5) → right (7).
- Operations like search, insert, delete: O(log n) (average), O(n) (worst-case in unbalanced tree).
What is a Trie?
A Trie (pronounced "try") is a specialised tree used for storing strings where each node represents a character of a word. Unlike a typical tree, paths from the root represent prefixes.
Key Features
- The root is usually empty.
- Each edge represents a character.
- Nodes can have flags to mark the end of a word.
- Nodes are shared among words with common prefixes.
Example
Consider inserting "cat", "cap", and "car":
root
└── c
└── a
├── t (word ends)
├── p (word ends)
└── r (word ends)
Each level represents one character. Common prefixes like ca are stored only once, making searches faster.
Operations and Time Complexities
| Operation | Time |
|---|---|
| Insert | O(m) where m = length of word |
| Search | O(m) |
| Prefix Match | O(m) |
Note: Time is independent of the number of words, unlike searching in an array.
Use Cases
- Autocomplete systems (Google Search suggestions).
- Spell checkers.
- IP routing (prefix matching).
- Dictionary implementations.
Key Differences Between Tree and Trie
Let’s compare Trees and Tries across various dimensions to understand their core differences:
| Feature | Tree | Trie |
|---------|----------|----------|
| Purpose | General-purpose data storage | Efficient retrieval and prefix matching of strings |
| Node Content| Can store any data type | Typically stores a single character per node |
| Depth | Depends on the structure of data | Depends on the length of the strings |
| Search Time | O(log n) (in balanced BST) | O(m), where m = length of the string |
| Memory Usage| Efficient for general data | Higher, as each character takes a node (can be sparse) |
| Redundancy | Lower redundancy | Shared prefixes reduce redundancy, but can be node-heavy |
| Flexibility | Versatile (numbers, objects, etc.) | Primarily for strings or sequences |
Example Breakdown
- Tree: Great for sorted data like numbers, where binary search helps quickly find values.
-
Trie: Built specifically to handle multiple words with shared prefixes (e.g.,
interview,internet,internal), making lookups extremely fast.
Use Cases
Use a Tree when
- You must store and query ordered numeric or object-based data.
- You’re implementing binary search, sorting, or traversals.
- Your data represents hierarchies (like a file system, HTML DOM tree, or organisational chart).
- Examples:
- Binary Search Trees for searching numbers.
- Expression Trees in Compilers.
- Parse Trees in Language Processing.
Use a Trie when
- Your data is mostly textual and you need fast prefix-based search.
- You want to implement features like auto-complete, spell checkers, or search suggestions.
- You’re dealing with routing prefixes or dictionary compression.
- Examples:
- Google Search’s auto-suggestion.
- IP routing using Longest Prefix Match.
- Efficient word filtering or blacklisting.
Visual Comparison: Tree vs Trie
- Trees are general-purpose, storing a wide range of data.
- Tries are optimized for string operations, especially when working with a large volume of similar words.
Code Examples
Basic Tree Implementation (Binary Search Tree Insertion)
class TreeNode:
def __init__(self, key):
self.key = key
self.left = None
self.right = None
class BST:
def __init__(self):
self.root = None
def insert(self, key):
def _insert(node, key):
if node is None:
return TreeNode(key)
if key < node.key:
node.left = _insert(node.left, key)
else:
node.right = _insert(node.right, key)
return node
self.root = _insert(self.root, key)
def inorder(self, node):
if node:
self.inorder(node.left)
print(node.key, end=" ")
self.inorder(node.right)
# Example usage
tree = BST()
for val in [10, 5, 15, 2, 7]:
tree.insert(val)
tree.inorder(tree.root) # Output: 2 5 7 10 15
This simple BST supports insertion and in-order traversal, ideal for sorted numerical data.
Basic Trie Implementation (Insertion and Search)
class TrieNode:
def __init__(self):
self.children = {}
self.is_end_of_word = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
current = self.root
for char in word:
if char not in current.children:
current.children[char] = TrieNode()
current = current.children[char]
current.is_end_of_word = True
def search(self, word):
current = self.root
for char in word:
if char not in current.children:
return False
current = current.children[char]
return current.is_end_of_word
# Example usage
trie = Trie()
trie.insert("tree")
trie.insert("trie")
print(trie.search("trie")) # Output: True
print(trie.search("trip")) # Output: False
This Trie handles string insertion and exact word searching efficiently, perfect for dictionary-style data.
Conclusion
Tree vs Trie: Which one should you use?
- Use Trees when dealing with:
- Sorted data
- Numeric comparisons
- Range queries or hierarchical data
- Use Tries when dealing with:
- Word-based lookups
- Prefix searches
- Autocomplete or spell-check features
Tries shine in text-heavy applications, especially when speed and prefix matching are critical. Trees are more flexible and general-purpose, making them ideal for a wider variety of tasks.
What's next?
In our next article, we’ll explore
- Advanced Trie Operations: Deletion, Prefix Search, and Applications - Understanding Suffix Trees and Suffix Tries