





















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)









































































































































































































































.jpg?#)













































































































































![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)

![Apple Shares New Ad for iPhone 16: 'Trust Issues' [Video]](https://www.iclarified.com/images/news/97125/97125/97125-640.jpg)



























































































































Testing MongoDB Atlas Search Java Apps Using TestContainers
This article is written by Luke Thompson This will be an exploration of testing MongoDB Atlas Search solutions written in Java using TestContainers and JUnit5. We’ll start simple and build up to more advanced uses which load seed data and provide an environment for consistent and easy to maintain tests. TLDR; if (like me!) you want to get straight to the code rather than reading lots of tedious words: git clone https://github.com/luketn/mongodb-atlas-local-testcontainers.git cd mongodb-atlas-local-testcontainers mvn test What is MongoDB Atlas Search, anyway? MongoDB Atlas Search is an extension to the built-in indexing capabilities that are part of MongoDB itself, using the awesome open source indexing and query library Lucene. MongoDB has built a wrapper around Lucene called mongot. Mongot has two responsibilities: First, it follows the change stream of any collection you choose to index and builds Lucene indexes asynchronously. Second, when you run the $search aggregation stage in a MongoDB query, mongot will be invoked to perform a Lucene query on the index and return a stream of document ids for further processing and data retrieval. Lucene and MongoDB Atlas Search support many index types which are very different to the excellent, efficient, and super-fast b-tree based MongoDB indexes. Some examples of the use-cases the new MongoDB Atlas Search indexes support are: 1. Incredible full-text search engines (à la Google) Ranked searching: best results returned first Many powerful query types like phrase, wildcard, and text Fielded searching (e.g., title, author, contents) Fast, memory-efficient, and typo-tolerant suggesters Highlighting of terms matched in text 2. High performance, multi-index search Because of the inverted index style, and the efficient storage used in Lucene, multiple indexes can be searched at once with extremely high performance and parallelism. This overcomes a major limitation in traditional MongoDB indexes that the query planner will almost never use more than one index. This is one of the highest value features in MongoDB Atlas Search, and one of the main motivations for me when I started using it. 3. Amazon.com-style user interfaces with counted and grouped categories (facets) Facets are an amazing feature of MongoDB Atlas Search. Because of the speed of the search engine and the way it performs queries, it can group and count tokenised or numeric indexed fields alongside all the other search types it is performing. This allows you, for example, to build an Amazon.com-style tree of categories to the left of your search results page, which shows the number of results that would be present if that category were applied as a filter. 4. Artificial intelligence (AI) retrieval-augmented generation (RAG) using vectors Nearest-neighbor search for high-dimensionality vectors MongoDB Atlas Search surfaces these Lucene capabilities in a familiar MongoDB aggregate stage syntax, and allows you to create amazing and powerful applications built on this super fast and flexible search engine. MongoDB Atlas Search is an Atlas-cloud hosted service which MongoDB automatically maintains for you and runs alongside your database or on dedicated search nodes in your cluster. Local development and testing with MongoDB Atlas Search If you are building an application or service based on MongoDB Atlas Search, a crucial part of the developer experience is how to debug and test locally. Seeing this community need, MongoDB has packaged mongot and mongod up in an awesome Docker container: MongoDB Atlas Local. You can find the container (mongodb/mongodb-atlas-local) on DockerHub. You can run this container on your machine, and then build and experiment with all the features locally. In addition, if you are using Java, you can write unit tests using the awesome unit test support provided for MongoDB and MongoDB Atlas Local containers in the TestContainers project. What’s TestContainers? TestContainers is a handy unit testing library that helps you write integration tests by managing containerised versions of services you might use in your code. A few things it does for you are it: Automatically manages containers for unit test contexts. Runs consistently in any environment—e.g., locally, on CI/CD like GitHub Actions with minimal or no config. Manages port conflicts dynamically and provides system-unique connection strings. Cleans up after each scope for a consistent environment every test run. Even though we’re going to be using the Java TestContainers project here, TestContainers is available for lots of languages and platforms. You can check it out on their website. Let’s write some code! We’ll build a simple Java data access layer with unit tests, then gradually add features and more comprehensive tests as we go. Simple CRUD data access and unit tests Here’s a simple DataAccess class in Java, using the awesome
This article is written by Luke Thompson
This will be an exploration of testing MongoDB Atlas Search solutions written in Java using TestContainers and JUnit5. We’ll start simple and build up to more advanced uses which load seed data and provide an environment for consistent and easy to maintain tests.
TLDR; if (like me!) you want to get straight to the code rather than reading lots of tedious words:
git clone https://github.com/luketn/mongodb-atlas-local-testcontainers.git
cd mongodb-atlas-local-testcontainers
mvn test
What is MongoDB Atlas Search, anyway?
MongoDB Atlas Search is an extension to the built-in indexing capabilities that are part of MongoDB itself, using the awesome open source indexing and query library Lucene. MongoDB has built a wrapper around Lucene called mongot. Mongot has two responsibilities: First, it follows the change stream of any collection you choose to index and builds Lucene indexes asynchronously. Second, when you run the $search aggregation stage in a MongoDB query, mongot will be invoked to perform a Lucene query on the index and return a stream of document ids for further processing and data retrieval.
](https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fl9b9nklkkhlsfoeemjkq.png)
Lucene and MongoDB Atlas Search support many index types which are very different to the excellent, efficient, and super-fast b-tree based MongoDB indexes.
Some examples of the use-cases the new MongoDB Atlas Search indexes support are:
1. Incredible full-text search engines (à la Google)
Ranked searching: best results returned first
Fielded searching (e.g., title, author, contents)
Fast, memory-efficient, and typo-tolerant suggesters
Highlighting of terms matched in text
2. High performance, multi-index search
Because of the inverted index style, and the efficient storage used in Lucene, multiple indexes can be searched at once with extremely high performance and parallelism.
This overcomes a major limitation in traditional MongoDB indexes that the query planner will almost never use more than one index.
This is one of the highest value features in MongoDB Atlas Search, and one of the main motivations for me when I started using it.
3. Amazon.com-style user interfaces with counted and grouped categories (facets)
Facets are an amazing feature of MongoDB Atlas Search. Because of the speed of the search engine and the way it performs queries, it can group and count tokenised or numeric indexed fields alongside all the other search types it is performing.
This allows you, for example, to build an Amazon.com-style tree of categories to the left of your search results page, which shows the number of results that would be present if that category were applied as a filter.
4. Artificial intelligence (AI) retrieval-augmented generation (RAG) using vectors
- Nearest-neighbor search for high-dimensionality vectors
MongoDB Atlas Search surfaces these Lucene capabilities in a familiar MongoDB aggregate stage syntax, and allows you to create amazing and powerful applications built on this super fast and flexible search engine.
MongoDB Atlas Search is an Atlas-cloud hosted service which MongoDB automatically maintains for you and runs alongside your database or on dedicated search nodes in your cluster.
Local development and testing with MongoDB Atlas Search
If you are building an application or service based on MongoDB Atlas Search, a crucial part of the developer experience is how to debug and test locally.
Seeing this community need, MongoDB has packaged mongot and mongod up in an awesome Docker container: MongoDB Atlas Local. You can find the container (mongodb/mongodb-atlas-local) on DockerHub.
You can run this container on your machine, and then build and experiment with all the features locally.
In addition, if you are using Java, you can write unit tests using the awesome unit test support provided for MongoDB and MongoDB Atlas Local containers in the TestContainers project.
What’s TestContainers?
TestContainers is a handy unit testing library that helps you write integration tests by managing containerised versions of services you might use in your code. A few things it does for you are it:
Automatically manages containers for unit test contexts.
Runs consistently in any environment—e.g., locally, on CI/CD like GitHub Actions with minimal or no config.
Manages port conflicts dynamically and provides system-unique connection strings.
Cleans up after each scope for a consistent environment every test run.
Even though we’re going to be using the Java TestContainers project here, TestContainers is available for lots of languages and platforms. You can check it out on their website.
Let’s write some code!
We’ll build a simple Java data access layer with unit tests, then gradually add features and more comprehensive tests as we go.
Simple CRUD data access and unit tests
Here’s a simple DataAccess class in Java, using the awesome Java record immutable data type Person. It has simple CRUD methods:
package com.mycodefu;
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoClients;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.result.InsertOneResult;
import org.bson.BsonType;
import org.bson.codecs.pojo.annotations.BsonId;
import org.bson.codecs.pojo.annotations.BsonRepresentation;
import org.bson.types.ObjectId;
import java.util.Objects;
import static com.mongodb.client.model.Filters.eq;
public class PersonDataAccess implements AutoCloseable {
private final MongoClient mongoClient;
private final MongoCollection<Person> collection;
public record Person(
@BsonId
@BsonRepresentation(BsonType.OBJECT_ID)
String id,
String name,
int age,
String job,
String bio
) {
public static Person of(String name, int age, String job, String bio) {
return new Person(null, name, age, job, bio);
}
}
public PersonDataAccess(String connectionString) {
this.mongoClient = MongoClients.create(connectionString);
this.collection = this.mongoClient.getDatabase("examples").getCollection("person", Person.class);
}
public String insertPerson(Person person) {
InsertOneResult insertOneResult = this.collection.insertOne(person);
return Objects.requireNonNull(insertOneResult.getInsertedId()).asObjectId().getValue().toHexString();
}
public Person getPerson(String id) {
return this.collection.find(eq("_id", new ObjectId(id))).first();
}
public void updatePerson(Person person) {
this.collection.replaceOne(eq("_id", new ObjectId(person.id())), person);
}
public void deletePerson(String id) {
this.collection.deleteOne(eq("_id", new ObjectId(id)));
}
@Override
public void close() {
this.mongoClient.close();
}
}
So let’s see how we’d use TestContainers and JUnit5 to unit test this class:
package com.mycodefu;
import com.mycodefu.PersonDataAccess.Person;
import org.junit.jupiter.api.*;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import org.testcontainers.mongodb.MongoDBAtlasLocalContainer;
import static org.junit.jupiter.api.Assertions.*;
@Testcontainers
class PersonDataAccessTest {
@Container
private static final MongoDBAtlasLocalContainer mongoDBContainer = new MongoDBAtlasLocalContainer("mongodb/mongodb-atlas-local:8.0.5");
@AutoClose
private static PersonDataAccess personDataAccess;
@BeforeAll
static void beforeAll() {
personDataAccess = new PersonDataAccess(mongoDBContainer.getConnectionString());
}
@Test
void shouldInsertAndRetrievePerson() {
// Given
Person person = Person.of(
"John Doe",
30,
"Software Developer",
"John is a software developer who loves to code."
);
// When
String id = personDataAccess.insertPerson(person);
Person retrievedPerson = personDataAccess.getPerson(id);
// Then
assertNotNull(id);
assertNotNull(retrievedPerson);
assertEquals(id, retrievedPerson.id());
assertEquals("John Doe", retrievedPerson.name());
assertEquals(30, retrievedPerson.age());
assertEquals("Software Developer", retrievedPerson.job());
assertEquals("John is a software developer who loves to code.", retrievedPerson.bio());
}
@Test
void shouldUpdatePerson() {
// Given
Person person = Person.of(
"Jane Smith",
25,
"Data Scientist",
"Jane is a data scientist who loves to analyze data."
);
String id = personDataAccess.insertPerson(person);
// When
Person updatedPerson = new Person(
id,
"Jane Smith",
26,
"Senior Data Scientist",
"Jane is a senior data scientist who loves to analyze data."
);
personDataAccess.updatePerson(updatedPerson);
Person retrievedPerson = personDataAccess.getPerson(id);
// Then
assertEquals(26, retrievedPerson.age());
assertEquals("Senior Data Scientist", retrievedPerson.job());
}
@Test
void shouldDeletePerson() {
// Given
Person person = Person.of(
"Bill Lumbergh",
40,
"Manager",
"Bill is a manager of tech teams. Often asks 'What's happening?'."
);
String id = personDataAccess.insertPerson(person);
// When
personDataAccess.deletePerson(id);
Person retrievedPerson = personDataAccess.getPerson(id);
// Then
assertNull(retrievedPerson);
}
}
There are a few really nice things to notice about the code:
@TestContainers + @Container Annotations
Classes annotated with @TestContainers will look for @Container annotated fields in order to start up our container before the class, and tear it down again afterwards. This gives you a nice instance of MongoDB Atlas Local which only exists while the tests in this class are running.
@AutoClose Annotation
Because our PersonDataAccess class implements AutoCloseable, adding this annotation guarantees the class will have its Close() method called after the unit tests are run to close the MongoDB client connection cleanly.
After that, the tests are standard JUnit tests, which set up preconditions, perform an operation, and assert postconditions in the Given/When/Then style.
MongoDB Atlas Search with seed data and index wait
Alright, let’s get into MongoDB Atlas Search!
We’re going to extend our PersonDataAccess CRUD class with a new search() method, and then see how we can seed some data into the database and initialise a search index for us to test it on.
Let’s write the tests first!
We’ll create a new test class, PersonDataAccessSearchTest, for testing the MongoDB Atlas Search features of the data access. This is important because the CRUD tests affect the data in the collection and set up a race condition between their inserts and the MongoDB Atlas Search index. We want a consistent index to search against, otherwise our tests could be flaky.
Let’s write some code to add some test data before the tests run, and create a MongoDB Atlas Search index over the test data. This time, we’ll put a bit more text in the bio of the example people, and insert them upfront so we can play with the text search capabilities (thanks, Phi 4, for the bios!).
Create a stub method in the data access class:
public List<Person> findPersonByBio(String query) {return List.of();}
Then, we’ll add the test class to invoke the stub method and test our assertions about what it should do:
package com.mycodefu;
import com.mongodb.client.ListSearchIndexesIterable;
import com.mycodefu.PersonDataAccess.Person;
import org.bson.BsonDocument;
import org.bson.Document;
import org.junit.jupiter.api.AutoClose;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import org.testcontainers.mongodb.MongoDBAtlasLocalContainer;
import org.testcontainers.shaded.org.awaitility.Awaitility;
import java.time.Duration;
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import static org.junit.jupiter.api.Assertions.*;
@Testcontainers
class PersonDataAccessSearchTest {
@Container
private static final MongoDBAtlasLocalContainer mongoDBContainer = new MongoDBAtlasLocalContainer("mongodb/mongodb-atlas-local:8.0.5");
@AutoClose
private static PersonDataAccess personDataAccess;
@BeforeAll
static void beforeAll() {
System.out.println("Initializing data access with MongoDB connection string: " + mongoDBContainer.getConnectionString());
personDataAccess = new PersonDataAccess(mongoDBContainer.getConnectionString());
//insert a few records for testing
personDataAccess.insertPerson(Person.of("Miss Scotty Leffler", 32, "farmer", "At 32, Miss Scotty Leffler is a dedicated farmer known for her innovative approaches to sustainable agriculture on her family-owned farm. Passionate about environmental stewardship, she combines traditional farming methods with modern technology to enhance crop yield and soil health."));
personDataAccess.insertPerson(Person.of("Raymon Wehner", 27, "dental hygienist", "At just 27 years old, Raymon Wehner is an accomplished dental hygienist dedicated to promoting oral health through comprehensive patient education and preventative care practices. With a passion for community outreach, Raymon frequently volunteers at local schools to teach children about the importance of maintaining good dental hygiene habits from an early age."));
personDataAccess.insertPerson(Person.of("Miss Steve Rempel", 22, "businessman", "At just 22 years old, Miss Steve Rempel has already made a significant mark as an innovative entrepreneur with a keen eye for emerging market trends and opportunities. Her dynamic approach to business is characterized by her ability to adapt quickly and lead diverse teams towards achieving ambitious goals, establishing herself as a rising star in the entrepreneurial landscape."));
personDataAccess.insertPerson(Person.of("Dustin Schinner", 45, "engineer", "At 45, Dustin Schinner is an accomplished engineer with over two decades of experience in innovative design and sustainable technology development. Known for his forward-thinking approach, he has led numerous successful projects that integrate cutting-edge solutions to address modern engineering challenges."));
personDataAccess.insertPerson(Person.of("Eartha Mosciski", 39, "window cleaner", "At 39, Eartha Mosciski has mastered the art of window cleaning, transforming ordinary buildings into sparkling showcases with her meticulous touch and eye for detail. Beyond just clearing away grime, she sees each pane as a canvas where light is artistically framed, bringing clarity and brightness to every view."));
personDataAccess.insertPerson(Person.of("Jackqueline Osinski", 23, "astronomer", "At just 23 years old, Jacqueline Osinski is making waves as an innovative astronomer dedicated to exploring the mysteries of distant galaxies. Her cutting-edge research on dark matter distribution has already earned her recognition in the scientific community and promises to reshape our understanding of the cosmos."));
personDataAccess.insertPerson(Person.of("Richard Ortiz II", 55, "lecturer", "Richard Ortiz II, at 55, is an esteemed lecturer renowned for his engaging teaching style and profound knowledge in his field of expertise. With years of experience shaping the minds of students across various disciplines, he continues to inspire through innovative educational approaches and a passion for lifelong learning."));
personDataAccess.insertPerson(Person.of("Brenton Bergstrom", 50, "bookkeeper", "At 50, Brenton Bergstrom is a seasoned bookkeeper with over two decades of experience ensuring the financial accuracy and integrity of businesses. Known for his meticulous attention to detail and dedication to precision, he plays a vital role in helping companies maintain their fiscal health and compliance."));
personDataAccess.insertPerson(Person.of(
"Carroll Ankunding",
39,
"travel agent",
"At 39, Carroll Ankunding is an experienced travel agent who combines her passion for exploration with a knack for crafting unforgettable journeys for clients. With nearly two decades of industry experience, she excels in tailoring personalized travel experiences that cater to the unique desires and needs of each traveler."));
personDataAccess.collection.createSearchIndex("person_search", BsonDocument.parse("""
{
"mappings": {
"dynamic": false,
"fields": {
"name": {
"type": "string",
"analyzer": "lucene.standard"
},
"age": {
"type": "number",
"representation": "int64",
"indexDoubles": false
},
"job": [
{
"type": "token"
},
{
"type": "stringFacet"
}
],
"bio": {
"type": "string",
"analyzer": "lucene.standard"
}
}
}
}
"""));
Instant startTime = Instant.now();
Awaitility.await()
.atMost(10, TimeUnit.SECONDS)
.until(() -> {
ListSearchIndexesIterable<Document> searchIndexes = personDataAccess.collection.listSearchIndexes();
Document personIndex = searchIndexes.into(new ArrayList<>()).stream().filter(index -> index.getString("name").equals("person_search")).findFirst().orElseThrow();
return personIndex.getString("status").equals("READY");
});
System.out.printf("Index created and ready in %dms%n", Duration.between(startTime, Instant.now()).toMillis());
}
@Test
void shouldFindPersonByBioWord_dedicated() {
// Given
String word = "dedicated";
// When
List<Person> dedicatedPeople = personDataAccess.findPersonByBio(word);
// Then
assertEquals(3, dedicatedPeople.size());
assertTrue(dedicatedPeople.stream().allMatch(person -> person.bio().contains(word)));
}
@Test
void shouldFindPersonByBioWord_fuzzy_yesr() {
// Given year (with a typo)
String word = "yesr";
// When fuzzy searched
List<Person> yearPeople = personDataAccess.findPersonByBio(word);
// Then match bios with 'year', or 'years'
assertEquals(4, yearPeople.size());
assertTrue(yearPeople.stream().allMatch(person -> person.bio().contains("year")));
//find the surrounding words and print them
yearPeople.forEach(person -> {
String bio = person.bio();
int index = bio.indexOf("year");
int start = Math.max(0, index - 20);
int end = Math.min(bio.length(), index + word.length() + 20);
String surroundingYear = bio.substring(start, end);
System.out.println(surroundingYear);
});
}
}
OK, so now we have 10 people in the database before the tests run, and we’ve created an Atlas search index with some different field types over each of the Person document fields.
Let’s explain what each index field type means, and what we can do with it:
-
Name + bio fields
{ type: ‘string’, analyzer: ‘lucene.standard’ }- The name and bio fields have an index type of string. Don’t let appearances fool you—this is the most complex type of index in MongoDB Atlas Search/Lucene. This index type tokenizes (splits) the strings in these fields into a list of terms using an analyzer. Here, we’re explicitly calling out the default analyzer, which splits on non-character boundaries, lower-casing (to ignore case), ignores stop words like in, and, and the, and handles acronyms and email addresses. This leaves the index with a nice ordered term list which is super fast to search and has ordinal indexes to the documents.
-
Age
{"type": "number", "representation": "int64", "indexDoubles": false}- The age field is an integer number, and it will allow searching by ranges, equality, or faceting. Very flexible and handy!
-
Job
[{ type: ‘token’ }, { type: ‘stringFacet’ }]
So far, we have inserted some seed data using the data access, and created a MongoDB Atlas Search index.
We also used the nice awaitility library to await the READY status on the MongoDB Atlas Search index. This is important because you can’t use the index until it has fully indexed all the data. In this case, we are inserting the data first and then adding the index, so once it is READY, we can be sure all the data can be searched.
At this point, our tests are expected to fail—let’s go implement the findPersonByBio() method to bring them to green.
We’ll use a fuzzy text search on the bio field in PersonDataAccess:
public List<Person> findPersonByBio(String query) {
//use Atlas Search to find a person by their bio
List<Bson> aggregateStages = List.of(
Aggregates.search(
SearchOperator
.text(fieldPath("bio"), query)
.fuzzy(FuzzySearchOptions
.fuzzySearchOptions()
.maxEdits(2)
.prefixLength(2)
.maxExpansions(50)
)
, SearchOptions.searchOptions().index("person_search"))
);
if (log.isTraceEnabled()) {
for (Bson aggregateStage : aggregateStages) {
log.trace(aggregateStage.toBsonDocument().toJson(JsonWriterSettings.builder().indent(true).build()));
}
}
ArrayList<Person> results = collection.aggregate(aggregateStages, Person.class).into(new ArrayList<>());
if (log.isTraceEnabled()) {
for (Person result : results) {
log.trace(result.toString());
}
}
return results;
}
You can see a couple of nice capabilities of MongoDB Atlas Search demonstrated with regular match and fuzzy matches on string indexed fields.
The options we are using there control just how fuzzy our fuzzy text search can be:
maxEdits: Maximum number of single-character edits required to match the specified search term. Value can be 1 or 2. The default value is 2. Uses Damerau-Levenshtein distance.
prefixLength: This is a key one. I feel like if the term doesn’t even start with what you typed, it sometimes feels pretty inaccurate. It refers to the number of characters at the beginning of each term in the result that must exactly match. The default value is 0.
maxExpansions: Maximum number of variations to generate and search for. This limit applies on a per-token basis. The default value is 50.
You can experiment with these levers to see what kind of results you get with your data set and whether they make sense.
Hopefully, you (like me!) now have green ticks and passing tests. Very satisfying.
I renamed my original test class PersonDataAccessCRUDTest and can run them both together. You can see they each get their own independent container and set of test data, giving good isolation of test cases and seed data.
Advanced seed data loading: MongoDB Database Tools
Finally, we’ll use a couple of more advanced TestContainers methods to load a more significant amount of seed data and run commands on the database.
The Atlas Local container includes all of the MongoDB Database Tools and the mongo shell. The key utilities for us are:
| mongorestore | Restores data from a mongodump database dump into a mongod or mongos |
|---|---|
| mongoimport | Imports content from an Extended JSON, CSV, or TSV export file |
| mongosh | A client for MongoDB, including the ability to run ad-hoc scripts from files |
Why does that matter for us? Seed data loading!
TestContainers has some awesome options which we can use here for loading seed data—mounting directories and executing commands within the container.
In our previous example, we manually created 10 records for testing search… What if we wanted to test against 15,000 records?
Mounting directories
You can mount directories to the container in two ways: by a resource class path or by a file system directory path.
This is just like making a volume mapping when running a Docker container at the command line like:
docker run --rm -it -v $(pwd):/tmp/local -w /tmp/local --entrypoint bash mongodb/mongodb-atlas-local
To mount a resource directory, we can just add a call to withClasspathResourceMapping to the container instance we are constructing for unit tests:
@Container
private static final MongoDBAtlasLocalContainer mongoDBContainer = new MongoDBAtlasLocalContainer("mongodb/mongodb-atlas-local:8.0.5")
.withClasspathResourceMapping(
"/seed-data",
"/tmp/seed-data",
BindMode.READ_WRITE
);
So once this container is running, the resource files under the directory /seed-data will be mounted within the container under the path /tmp/seed-data.
Running tools
Let’s assume we had a JSON file documents.jsonl in that resources location. We could then run mongoimport to import it:
mongoDBContainer.execInContainer(ExecConfig.builder()
.workDir("/tmp/seed-data")
.command(toArray("mongoimport", "-d", "examples", "-c", "person", "documents.jsonl"))
.build());
Running Mongo Shell scripts
You can also run Mongo Shell scripts which can be helpful for performing little maintenance tasks, applying indexes, or other tasks.
Mongo Shell supports eval to directly execute a command:
mongoDBContainer.execInContainer(ExecConfig.builder()
.workDir("/tmp/seed-data")
.command(toArray("mongosh", "--eval", "db.getSiblingDB('examples').person.insert({'test': '123'})"))
.build());
Or you can pass a JavaScript file to execute:
mongoDBContainer.execInContainer(ExecConfig.builder()
.workDir("/tmp/seed-data")
.command(toArray("mongosh", "-f", "atlas-index-utils.js"))
.build());
Running Shell scripts
If you want, you can also execute a bash script like:
mongoDBContainer.execInContainer(ExecConfig.builder()
.workDir("/tmp/seed-data")
.command(toArray("bash", "seed-data.sh"))
.build());
Loading a mongodump BSON database and index
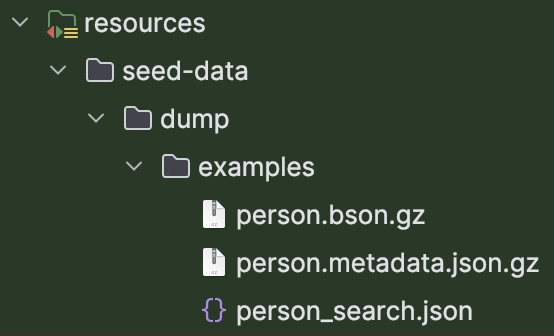
Let’s create some seed data and MongoDB Atlas Search indexes, which we’ll store in a resource directory /seed-data.
I’ve built a little test dataset of 15,000 Person documents in MongoDB and used mongodump to export it. Just for fun, I used a local LLM to generate it.
If you want these files, you can get the seed data files from the examples folder on GitHub.
Now, we can change our MongoDB Atlas Search test class to load up data from the resources:
package com.mycodefu;
import com.mongodb.client.ListSearchIndexesIterable;
import com.mycodefu.PersonDataAccess.Person;
import org.bson.BsonDocument;
import org.bson.Document;
import org.junit.jupiter.api.*;
import org.testcontainers.containers.BindMode;
import org.testcontainers.containers.ExecConfig;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import org.testcontainers.mongodb.MongoDBAtlasLocalContainer;
import org.testcontainers.shaded.com.google.common.io.Resources;
import org.testcontainers.shaded.org.awaitility.Awaitility;
import java.io.IOException;
import java.time.Duration;
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import static java.nio.charset.StandardCharsets.UTF_8;
import static org.junit.jupiter.api.Assertions.*;
import static org.testcontainers.shaded.org.apache.commons.lang3.ArrayUtils.toArray;
@Testcontainers
class PersonDataAccessSearchTest {
@Container
private static final MongoDBAtlasLocalContainer mongoDBContainer = new MongoDBAtlasLocalContainer("mongodb/mongodb-atlas-local:8.0.5")
.withClasspathResourceMapping(
"/seed-data",
"/tmp/seed-data",
BindMode.READ_WRITE
);
@AutoClose
private static PersonDataAccess personDataAccess;
@BeforeAll
static void beforeAll() throws IOException, InterruptedException {
System.out.println("Initializing data access with MongoDB connection string: " + mongoDBContainer.getConnectionString());
personDataAccess = new PersonDataAccess(mongoDBContainer.getConnectionString());
Instant startSeedDataRestore = Instant.now();
mongoDBContainer.execInContainer(ExecConfig.builder()
.workDir("/tmp/seed-data")
.command(toArray("mongorestore", "--gzip"))
.build());
System.out.println("Loading seed data took: " + Instant.now().minusMillis(startSeedDataRestore.toEpochMilli()).toEpochMilli() + "ms");
Instant startIndex = Instant.now();
String personSearchMappings = Resources.toString(Resources.getResource("seed-data/dump/examples/person_search.json"), UTF_8);
personDataAccess.collection.createSearchIndex("person_search", BsonDocument.parse(personSearchMappings));
Awaitility.await()
.atMost(10, TimeUnit.SECONDS)
.until(() -> {
ListSearchIndexesIterable<Document> searchIndexes = personDataAccess.collection.listSearchIndexes();
Document personIndex = searchIndexes.into(new ArrayList<>()).stream().filter(index -> index.getString("name").equals("person_search")).findFirst().orElseThrow();
return personIndex.getString("status").equals("READY");
});
System.out.printf("Index created and ready in %dms%n", Duration.between(startIndex, Instant.now()).toMillis());
}
@Test
void shouldFindPersonByBioWord_dedicated() {
// Given
String word = "dedicated";
// When
List<Person> dedicatedPeople = personDataAccess.findPersonByBio(word, false);
// Then
assertEquals(50, dedicatedPeople.size());
assertTrue(dedicatedPeople.stream().allMatch(person -> person.bio().contains(word)));
}
@Test
void shouldFindPersonByBioWord_fuzzy_yesr() {
// Given year (with a typo)
String word = "yesr";
// When fuzzy searched
List<Person> yearPeople = personDataAccess.findPersonByBio(word, true);
// Then match bios with 'year', or 'years'
assertEquals(50, yearPeople.size());
assertTrue(yearPeople.stream().allMatch(person -> person.bio().contains("year")));
//find the surrounding words and print them
yearPeople.forEach(person -> {
String bio = person.bio();
int index = bio.indexOf("year");
int start = Math.max(0, index - 20);
int end = Math.min(bio.length(), index + word.length() + 20);
String surroundingYear = bio.substring(start, end);
System.out.println(surroundingYear);
});
}
}
I also tweaked the data access class findPersonByBio() method to cope with a larger dataset:
public List<Person> findPersonByBio(String query, boolean fuzzy) {
//use Atlas Search to find a person by their bio
TextSearchOperator bioOperator = SearchOperator.text(fieldPath("bio"), query);
if (fuzzy) {
bioOperator = bioOperator
.fuzzy(FuzzySearchOptions
.fuzzySearchOptions()
.maxEdits(2)
.prefixLength(2)
.maxExpansions(100)
);
}
List<Bson> aggregateStages = List.of(
Aggregates.search(
bioOperator
, SearchOptions.searchOptions().index("person_search")),
Aggregates.limit(50)
);
if (log.isTraceEnabled()) {
for (Bson aggregateStage : aggregateStages) {
log.trace(aggregateStage.toBsonDocument().toJson(JsonWriterSettings.builder().indent(true).build()));
}
}
ArrayList<Person> results = collection.aggregate(aggregateStages, Person.class).into(new ArrayList<>());
if (log.isTraceEnabled()) {
for (Person result : results) {
log.trace(result.toString());
}
}
return results;
}
So now, we are loading our data (all 15,000 documents!) from a gzip’ed archive using the mongorestore utility on a mounted volume in the container. Then, we’re loading another resource file with the MongoDB Atlas Search index mapping and creating the index over the loaded data.
Having the seed data external to the code is extremely flexible and useful.
For example, we can:
- Load seed data from a remote cloud storage (e.g., AWS simple storage service (S3)).
- Reuse seed data between test contexts.
- Use seed data on remote Atlas cloud databases.
- Use seed data on local containers outside of unit tests.
Having the mappings JSON external is also useful, for instance:
- Index validation: I like to have a piece of production code validate that when my app runs in production, the index mapping it is expecting is present on production. I do that by comparing the current production DB with the resource JSON. Check out an example of how you might do that. I recommend logging a warning rather than raising an error if there is a mismatch, to alert you to the difference whilst allowing for rollout of changes gradually.
- Local index creation: In new environments (e.g., starting a new local container to test with), you can use this index mapping to initialise the MongoDB Atlas Search indexes.
- Production index rollout: Using a source controlled index mapping and performing a (controlled) rollout ahead of changes to software which will rely on it makes sense.
Wrapping up
So we’ve been through a few examples of how you can use the awesome TestContainers projects to enhance testing of your MongoDB Atlas Search Java apps.
I hope you find it useful. Feel free to reach out if you have questions through the comments. Happy coding!
Further reading
Here are a few links for further reading:
- TestContainers is an awesome project. For instance, you can try this one for mocking Amazon Web Services (AWS) with LocalStack.
- Build faceted full-text search APIs with Java.
- I highly recommend MongoDB University. There are excellent courses that cover MongoDB with Java generally, Atlas Search, and much more.