
















































































































































































![[The AI Show Episode 148]: Microsoft’s Quiet AI Layoffs, US Copyright Office’s Bombshell AI Guidance, 2025 State of Marketing AI Report, and OpenAI Codex](https://www.marketingaiinstitute.com/hubfs/ep%20148%20cover%20%281%29.png)


![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)






























































































































![Laid off but not afraid with X-senior Microsoft Dev MacKevin Fey [Podcast #173]](https://cdn.hashnode.com/res/hashnode/image/upload/v1747965474270/ae29dc33-4231-47b2-afd1-689b3785fb79.png?#)


















































































































_MEGHzTK.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-1-52-screenshot.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)










![T-Mobile Starlink beta’s list of eligible devices reduced, some phones no longer allowed [UPDATED]](https://m-cdn.phonearena.com/images/article/170719-two/T-Mobile-Starlink-betas-list-of-eligible-devices-reduced-some-phones-no-longer-allowed-UPDATED.jpg?#)









_David_Hall_-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Andriy_Popov_Alamy_Stock_Photo.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


















































































-xl.jpg)






















![Xiaomi Tops Wearables Market as Apple Slips to Second in Q1 2025 [Chart]](https://www.iclarified.com/images/news/97417/97417/97417-640.jpg)


![Apple Shares Official Trailer for Season 2 of 'The Buccaneers' [Video]](https://www.iclarified.com/images/news/97414/97414/97414-640.jpg)




























































Pipelining for Memcached
Typical Client-Server protocols operate a request - response model. With the HTTP1 protocol for example, Request N+1 is blocked by Request N on a single TCP connection. With clients like web browsers, the workaround is to establish a pool of connections which allow multiple assets like images, scripts to be requested all at once. This means that requests N and N+1 could be sent all at once. Pipelining was eventually implemented in HTTP1.1, which allows multiple requests to be sent over the same connection without waiting for the server's response. Even with this solution, The requests must still be processed in order. This is the head of line (HOL) blocking problem, where the processing of these requests are still as fast as the slowest request. HTTP2 solved this with multiplexing. Multiple requests which are distinguished by a unique stream ID can be interwoven on a single TCP connection and responses could be delivered out of order! HTTP2 still suffered the HOL blocking problem at the TCP layer. This is because at the TCP layer, everything is a stream of bytes over a single connection and if any bytes are dropped (packet loss), all the bytes after (other requests) are blocked till TCP detects and retransmits. With HTTP3, TCP was dropped for UDP which can handle streams, so only a single stream or request is blocked when there’s packet loss. This is a brief and simplified summary but it helps paint the picture. Why is Pipelining important ? Redis added support for pipelining and explains why beautifully. Basically, for every request (without pipelining), the client has to issue a write syscall to copy bytes from the application in user mode to the tcp buffer in kernel mode and send this over the network. The server on the other hand, makes a read syscall to read the tcp buffer and processes the request. Pipelining doesn’t reduce the time the server uses to process these requests but saves us time as we won’t have to context switch multiple times when we issue these syscalls. Even in cases where the client and server are on the same machine and communicate via the loopback address, we still see improvements when we utilise pipelining. Memcached Memcached is a key-value store (like redis) written in C. I've been working with it a lot recently and it uses either its ASCII protocol or its binary protocol. Starting a memcached server in verbose mode, i see these lines which show that the server supports both protocols and its up to the client to decide what to use: $ memcached -vv server listening (auto-negotiate) server listening (auto-negotiate) new auto-negotiating client connection …………… Client using the ascii protocol I noticed that the rust memcached client i was using didn’t have pipelining support for any commands except the “Get” command. The Set, Increment, Decrement commands have to be issued per key. Then i realised that memcached’s ASCII protocol doesn’t support pipelining, only its binary protocol does. The ASCII protocol implements some form of pipelining for the get command. get .... value 1, value 2, …. value N The binary protocol implements pipelining in a different way. It has “quiet” variants of these commands. GetQuiet, SetQuiet, AddQuiet, IncrementQuiet etc. The “quiet” variants tell the server to not respond. These responses are queued internally and are returned when the client sends a non-quiet command or a no-op. This returns all the queued keys. Eg: getq ..... ….NO RESPONSE FROM THE SERVER get key value 1, value 2, value N, value N + 1. Many clients are comfortable pipelining Get requests as these are read only operations but pipelining Increment requests can get tricky as these are not atomic. Some increments might fail and it’ll be difficult to track and account for. bmemcached I found a python library that implements the binary memcached protocol and the author also wrote a rust flavour. To ensure we're using the binary protocol, i run the tests and look at memcached logs: 28: Client using the binary protocol 27 0x00 0x00 0x00 0x00 >27 0x00 0x00 0x00 0x00 >27 0x00 0x00 0x00 0x02 We see that the value is set and we get a response back. Issue four commands to increment this "counter" quietly. We shouldn't see any responses which means that we're pipelining. for x in 1..5{ // This means increment key "counter" by 1 from its initial value "x" and set TTL to 7 seconds. let _ = client.increment_quiet("counter", 1, x, 7000).unwrap(); } Taking a look at memcached logs: incr counter 1, 2, 7000

Typical Client-Server protocols operate a request - response model.
With the HTTP1 protocol for example, Request N+1 is blocked by Request N on a single TCP connection. With clients like web browsers, the workaround is to establish a pool of connections which allow multiple assets like images, scripts to be requested all at once. This means that requests N and N+1 could be sent all at once.
Pipelining was eventually implemented in HTTP1.1, which allows multiple requests to be sent over the same connection without waiting for the server's response.
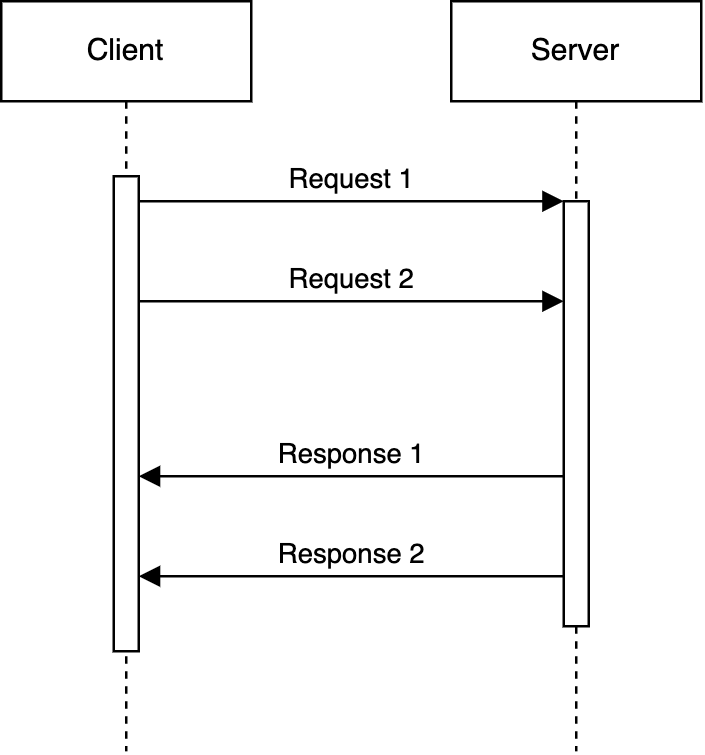
Even with this solution, The requests must still be processed in order. This is the head of line (HOL) blocking problem, where the processing of these requests are still as fast as the slowest request.
HTTP2 solved this with multiplexing. Multiple requests which are distinguished by a unique stream ID can be interwoven on a single TCP connection and responses could be delivered out of order!
HTTP2 still suffered the HOL blocking problem at the TCP layer. This is because at the TCP layer, everything is a stream of bytes over a single connection and if any bytes are dropped (packet loss), all the bytes after (other requests) are blocked till TCP detects and retransmits.
With HTTP3, TCP was dropped for UDP which can handle streams, so only a single stream or request is blocked when there’s packet loss.
This is a brief and simplified summary but it helps paint the picture.
Why is Pipelining important ?
Redis added support for pipelining and explains why beautifully. Basically, for every request (without pipelining), the client has to issue a write syscall to copy bytes from the application in user mode to the tcp buffer in kernel mode and send this over the network. The server on the other hand, makes a read syscall to read the tcp buffer and processes the request. Pipelining doesn’t reduce the time the server uses to process these requests but saves us time as we won’t have to context switch multiple times when we issue these syscalls. Even in cases where the client and server are on the same machine and communicate via the loopback address, we still see improvements when we utilise pipelining.
Memcached
Memcached is a key-value store (like redis) written in C. I've been working with it a lot recently and it uses either its ASCII protocol or its binary protocol.
Starting a memcached server in verbose mode, i see these lines which show that the server supports both protocols and its up to the client to decide what to use:
$ memcached -vv
server listening (auto-negotiate)
server listening (auto-negotiate)
new auto-negotiating client connection
……………
Client using the ascii protocol
I noticed that the rust memcached client i was using didn’t have pipelining support for any commands except the “Get” command. The Set, Increment, Decrement commands have to be issued per key.
Then i realised that memcached’s ASCII protocol doesn’t support pipelining, only its binary protocol does. The ASCII protocol implements some form of pipelining for the get command.
get ....
value 1, value 2, …. value N
The binary protocol implements pipelining in a different way. It has “quiet” variants of these commands. GetQuiet, SetQuiet, AddQuiet, IncrementQuiet etc.
The “quiet” variants tell the server to not respond. These responses are queued internally and are returned when the client sends a non-quiet command or a no-op. This returns all the queued keys.
Eg:
getq .....
….NO RESPONSE FROM THE SERVER
get key
value 1, value 2, value N, value N + 1.
Many clients are comfortable pipelining Get requests as these are read only operations but pipelining Increment requests can get tricky as these are not atomic. Some increments might fail and it’ll be difficult to track and account for.
bmemcached
I found a python library that implements the binary memcached protocol and the author also wrote a rust flavour.
To ensure we're using the binary protocol, i run the tests and look at memcached logs:
28: Client using the binary protocol
<28 Read binary protocol data:
The next hurdle is that these libraries don’t implement the quiet variant of the memcached commands. I have to fork the repo and implement IncrementQuiet (IncrementQ).
After some ChatGPT research, I learn that IncrementQ implements the same binary message as plain ol Increment. It just has a different binary code. This means this will be relatively easy to implement.
Testing our IncrementQ implementation
- Connect to Memcached and set a key called "counter" to an intial value of 1 with a TTL of 5 seconds.
let client = MemcachedClient::new(vec!["127.0.0.1:11211"], 1).unwrap();
let key = "counter";
let value = "1";
client.set(key, value, 5000).unwrap();
Looking at memcached logs:
<27 Read binary protocol data:
<27 0x80 0x01 0x00 0x07
<27 0x08 0x00 0x00 0x00
<27 SET counter Value len is 1
>27 Writing bin response:
>27 0x81 0x01 0x00 0x00
>27 0x00 0x00 0x00 0x00
>27 0x00 0x00 0x00 0x00
>27 0x00 0x00 0x00 0x00
>27 0x00 0x00 0x00 0x00
>27 0x00 0x00 0x00 0x02
We see that the value is set and we get a response back.
- Issue four commands to increment this "counter" quietly. We shouldn't see any responses which means that we're pipelining.
for x in 1..5{
// This means increment key "counter" by 1 from its initial value "x" and set TTL to 7 seconds.
let _ = client.increment_quiet("counter", 1, x, 7000).unwrap();
}
Taking a look at memcached logs:
incr counter 1, 2, 7000
<27 Read binary protocol data:
<27 0x80 0x15 0x00 0x07
<27 0x14 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x1b
<27 0x00 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x00
incr counter 1, 3, 7000
<27 Read binary protocol data:
<27 0x80 0x15 0x00 0x07
<27 0x14 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x1b
<27 0x00 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x00
incr counter 1, 4, 7000
<27 Read binary protocol data:
<27 0x80 0x00 0x00 0x07
<27 0x00 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x07
<27 0x00 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x00
<27 0x00 0x00 0x00 0x00
No responses!
- Validate the counter's new value is 5.
let new_value: String = client.get(key).unwrap();
assert_eq!(new_value, "5");
It pipelined ✅




