




































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)















































































































































































































































































_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































![Craft adds Readwise integration for working with book notes and highlights [50% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/craft3.jpg.png?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)































































































Parsing Unstructured Text Into Clean, Structured Data — A Regex-Powered Approach
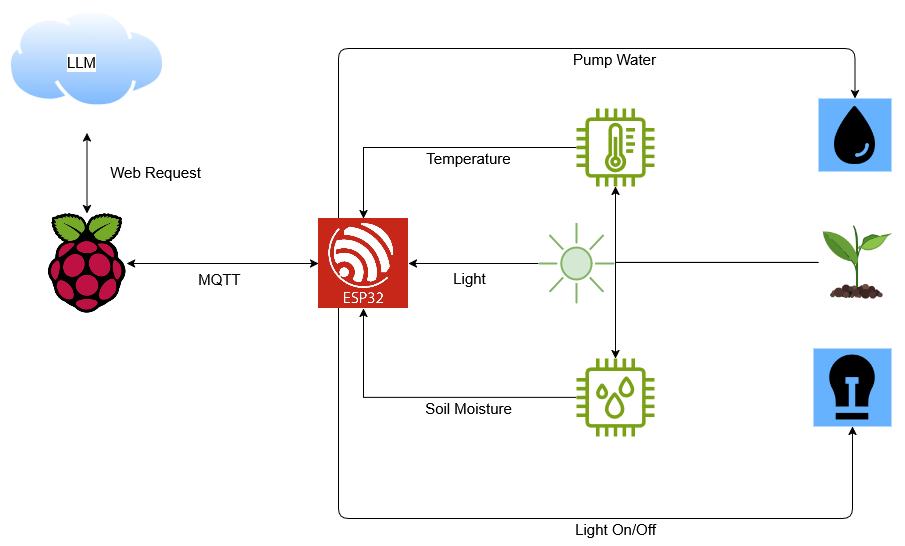
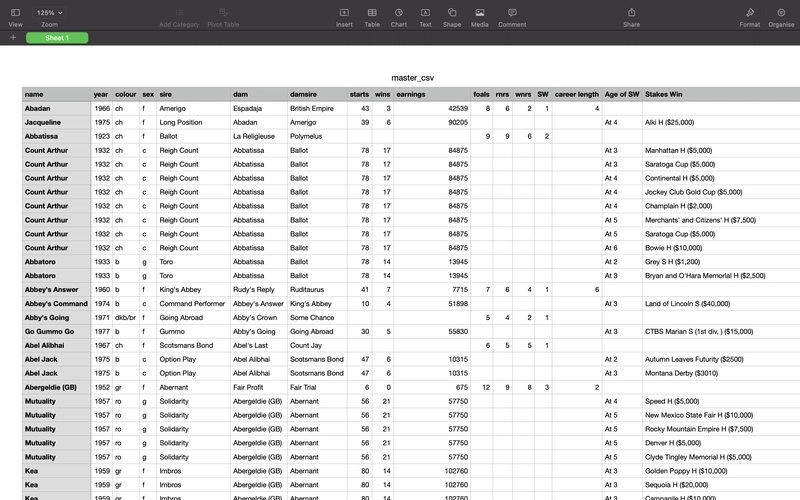
Transforming messy, human-readable text into clean, structured rows and columns is one of the most tedious but necessary tasks in data science, especially when you're working with legacy formats or domain-specific archives. Recently, I built a custom parser to do exactly that—converting chaotic, delimiter-laden horse racing records into clean, structured CSV files using Python and regular expressions. The Problem: Imagine trying to extract meaningful data from a block of text that’s littered with inconsistent delimiters like hyphens, tabs, ellipses, and bullet points. That’s what the raw input looked like—unstructured text files full of valuable racing data, but formatted in a way that made it nearly impossible to work with programmatically. The Tools: Python + Regex + Logic Here’s how the process was broken down: Preprocessing the Delimiters The first script scanned through each line in the raw .txt file and replaced noisy or ambiguous delimiters (-, ..., •, tabs, etc.) with clean commas. It also took care of collapsing multiple commas into one, providing a more consistent surface for parsing. i.e.,: This produced something like this: Regex Extraction Using a set of carefully crafted regular expressions, I extracted meaningful fields from each line—such as: Horse name and year of birth Colour and sex Starts, wins, earnings Bloodline information (sire, dam, damsire) Breeding stats (foals, runners, winners, SW) Career length Stakes wins by age This wasn't just string matching—it included handling missing values, intelligently inferring information based on previous entries, and parsing complex compound phrases like At 3 won the Abadan Derby (G2), Winter Classic. i.e.,: Multi-line Contextual Inference Some information wasn’t explicit in every row. For example, if a horse’s dam or damsire wasn’t listed, the script would backtrack up to 15 previous entries to find the most recent relevant female horse and assign her as the dam. Similarly, if the damsire was missing, it was inferred from the "previous-but-one" sire. Export to CSV Finally, all structured data was written into a clean CSV file ready for downstream analysis. The Result By the end, I had a structured CSV with clearly defined columns for each key attribute of the horses' performance and lineage. This opens up all sorts of data-driven possibilities—analytics, visualisation, modelling, or feeding into other horse racing applications. i.e.,: Why This Matters Turning unstructured data into structured datasets is a fundamental skill in real-world data projects. This parser is tailored for horse racing records, but the principles—preprocessing, pattern recognition, intelligent inference—apply to any domain where data comes in messy formats. If you’re wrangling legacy text files, don’t underestimate what a few good regex patterns and a bit of logic can do.
Transforming messy, human-readable text into clean, structured rows and columns is one of the most tedious but necessary tasks in data science, especially when you're working with legacy formats or domain-specific archives. Recently, I built a custom parser to do exactly that—converting chaotic, delimiter-laden horse racing records into clean, structured CSV files using Python and regular expressions.
The Problem:
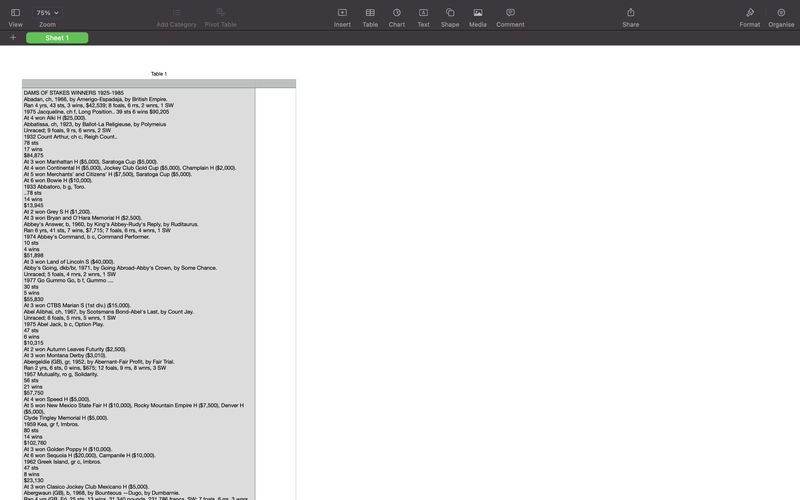
Imagine trying to extract meaningful data from a block of text that’s littered with inconsistent delimiters like hyphens, tabs, ellipses, and bullet points. That’s what the raw input looked like—unstructured text files full of valuable racing data, but formatted in a way that made it nearly impossible to work with programmatically.
The Tools: Python + Regex + Logic
Here’s how the process was broken down:
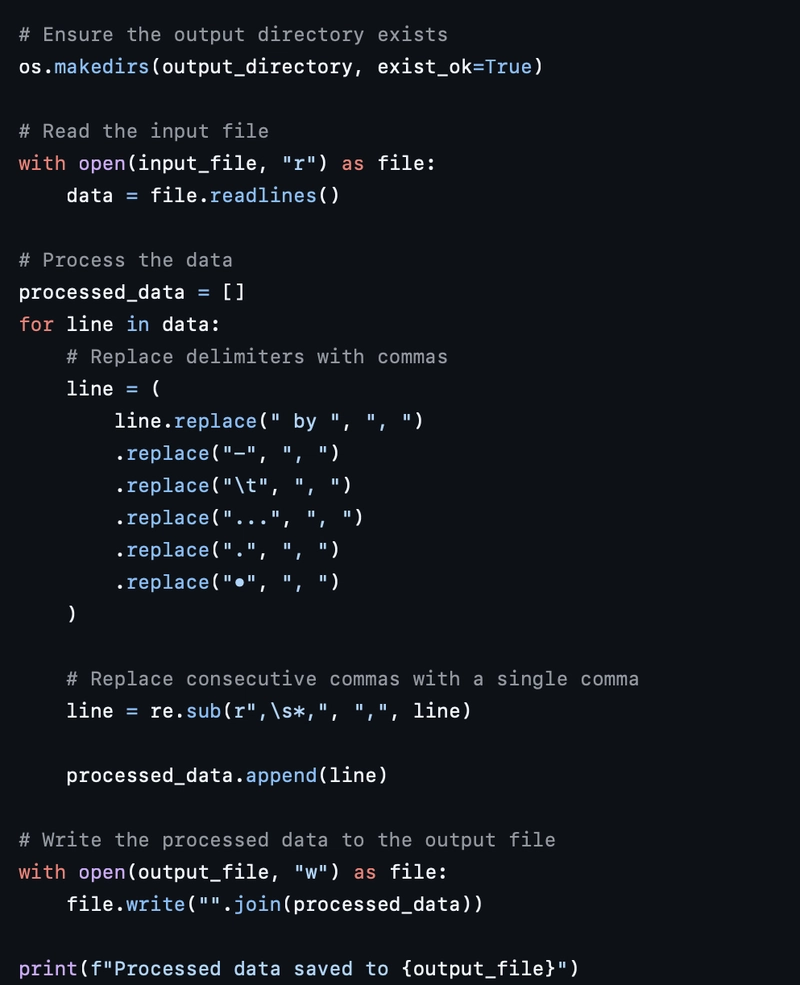
- Preprocessing the Delimiters
The first script scanned through each line in the raw .txt file and replaced noisy or ambiguous delimiters (-, ..., •, tabs, etc.) with clean commas. It also took care of collapsing multiple commas into one, providing a more consistent surface for parsing.
i.e.,:
This produced something like this:
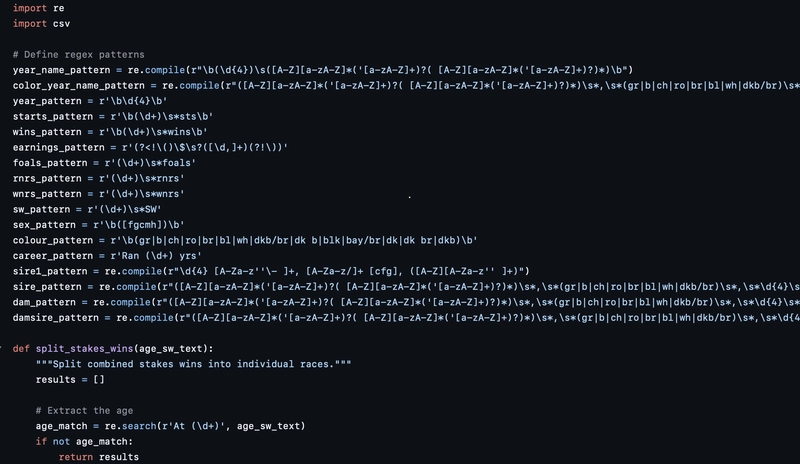
- Regex Extraction
Using a set of carefully crafted regular expressions, I extracted meaningful fields from each line—such as:
- Horse name and year of birth
- Colour and sex
- Starts, wins, earnings
- Bloodline information (sire, dam, damsire)
- Breeding stats (foals, runners, winners, SW)
- Career length
- Stakes wins by age
This wasn't just string matching—it included handling missing values, intelligently inferring information based on previous entries, and parsing complex compound phrases like At 3 won the Abadan Derby (G2), Winter Classic.
i.e.,:
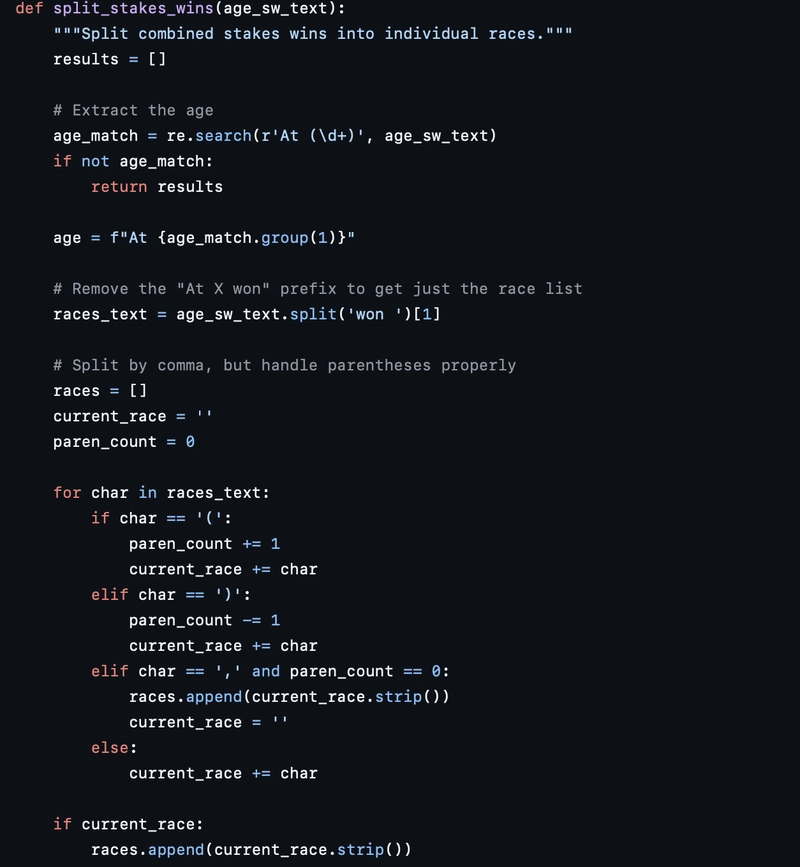
- Multi-line Contextual Inference
Some information wasn’t explicit in every row. For example, if a horse’s dam or damsire wasn’t listed, the script would backtrack up to 15 previous entries to find the most recent relevant female horse and assign her as the dam. Similarly, if the damsire was missing, it was inferred from the "previous-but-one" sire.
- Export to CSV
Finally, all structured data was written into a clean CSV file ready for downstream analysis.
The Result
By the end, I had a structured CSV with clearly defined columns for each key attribute of the horses' performance and lineage. This opens up all sorts of data-driven possibilities—analytics, visualisation, modelling, or feeding into other horse racing applications.
i.e.,:
Why This Matters
Turning unstructured data into structured datasets is a fundamental skill in real-world data projects. This parser is tailored for horse racing records, but the principles—preprocessing, pattern recognition, intelligent inference—apply to any domain where data comes in messy formats.
If you’re wrangling legacy text files, don’t underestimate what a few good regex patterns and a bit of logic can do.






