


















































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)



















































































































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























_Vladimir_Stanisic_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






































































































![Standalone Meta AI App Released for iPhone [Download]](https://www.iclarified.com/images/news/97157/97157/97157-640.jpg)

![AirPods Pro 2 With USB-C Back On Sale for Just $169! [Deal]](https://www.iclarified.com/images/news/96315/96315/96315-640.jpg)
![Apple Releases iOS 18.5 Beta 4 and iPadOS 18.5 Beta 4 [Download]](https://www.iclarified.com/images/news/97145/97145/97145-640.jpg)















































![Did T-Mobile just upgrade your plan again? Not exactly, despite confusing email [UPDATED]](https://m-cdn.phonearena.com/images/article/169902-two/Did-T-Mobile-just-upgrade-your-plan-again-Not-exactly-despite-confusing-email-UPDATED.jpg?#)










































OCR: Digitise Physical Text Documents with Ease
Easily convert scanned or photographed documents into editable, machine-readable text using Optical Character Recognition (OCR). From this: ] To This: Method 1: Using AWS Textract API This method leverages Amazon's powerful Textract OCR service to extract text from images. It works well for printed text, especially on structured documents. Features: Batch process multiple files Automatically saves extracted content to .txt files Supports line-by-line text extraction Easy to extend and integrate Sample code: Method 2: Pytesseract Tools We Use Python OpenCV – For image processing Pytesseract – A Python wrapper for Google’s Tesseract-OCR Engine Pillow (PIL) – For additional image support CSV – To export results Before diving into the code, make sure you have Tesseract installed and properly linked in your script. For macOS users: pytesseract.pytesseract.tesseract_cmd = r'/opt/homebrew/bin/tesseract' Step 1: Image Preprocessing Pipeline OCR engines work best when the input text is clear, contrast-rich, and isolated from background noise. Here's the sequence of transformations applied to each image: Grayscale Conversion Converting the image to grayscale helps reduce complexity and makes it easier to isolate text. Sharpening We apply a Laplacian filter to enhance edges and make the text pop. Inversion OCR engines often perform better when text is black on a white background. Thresholding We binarise the image using Otsu’s method, separating text from background. Denoising Removing small artifacts with a median blur filter. Font Smoothing (Optional) If text appears too thin or thick, you can apply morphological operations (dilation/erosion). Step 2: OCR Text Extraction Once the image is processed, we convert it back to RGB (required by Tesseract) and extract the text. Step 3: Save to CSV Finally, we store the extracted text in a CSV file for later use. Sample code: What Next? Once your text is extracted, check out my companion repository: https://github.com/TheOxfordDeveloper/Parsing-unstructured-data.git It shows how to clean and convert raw OCR text into structured, tabular formats, like this:
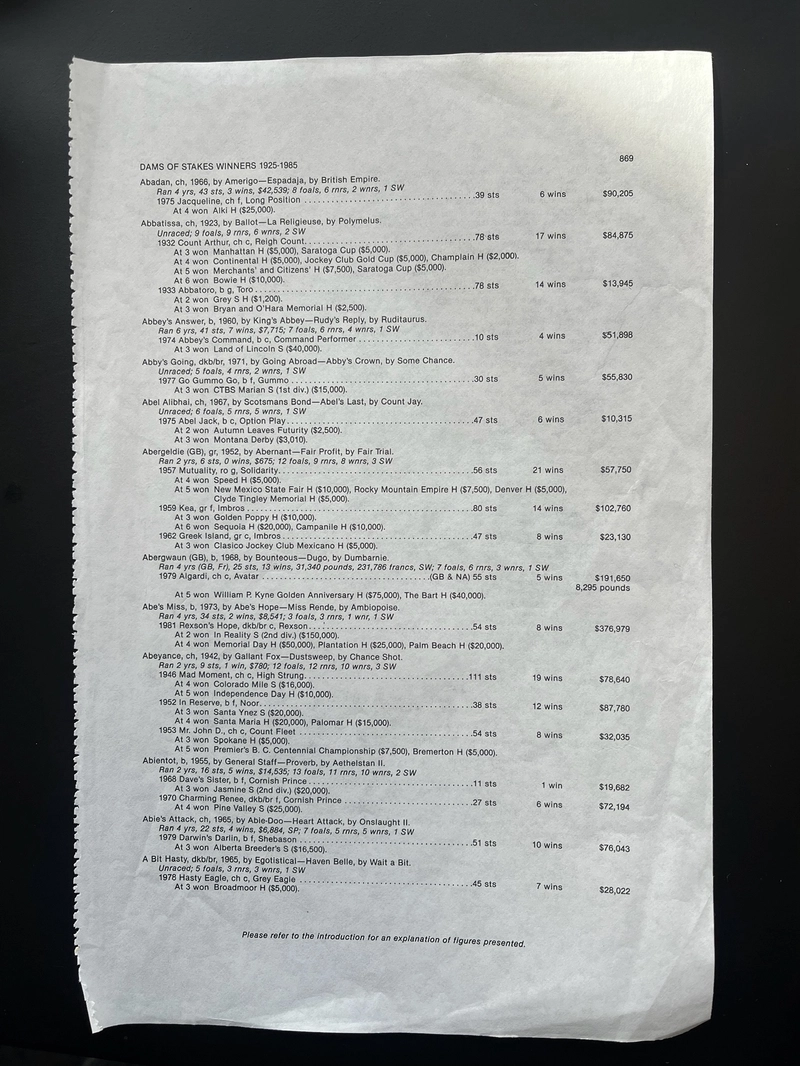
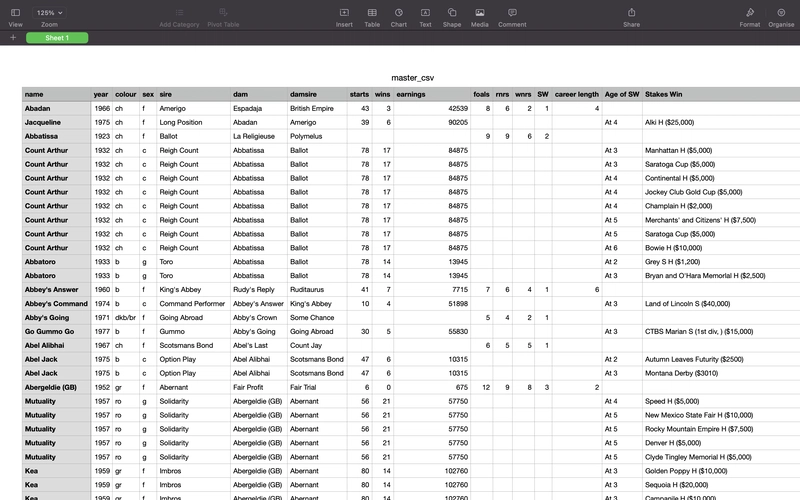
Easily convert scanned or photographed documents into editable, machine-readable text using Optical Character Recognition (OCR).
From this:
]
To This:
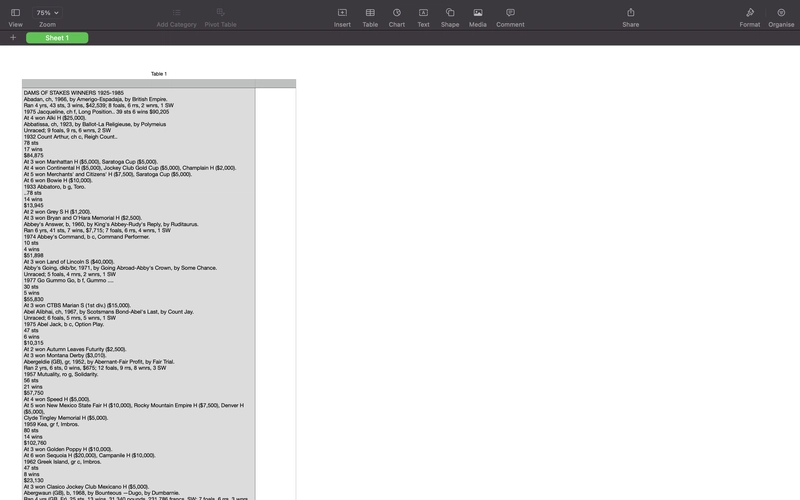
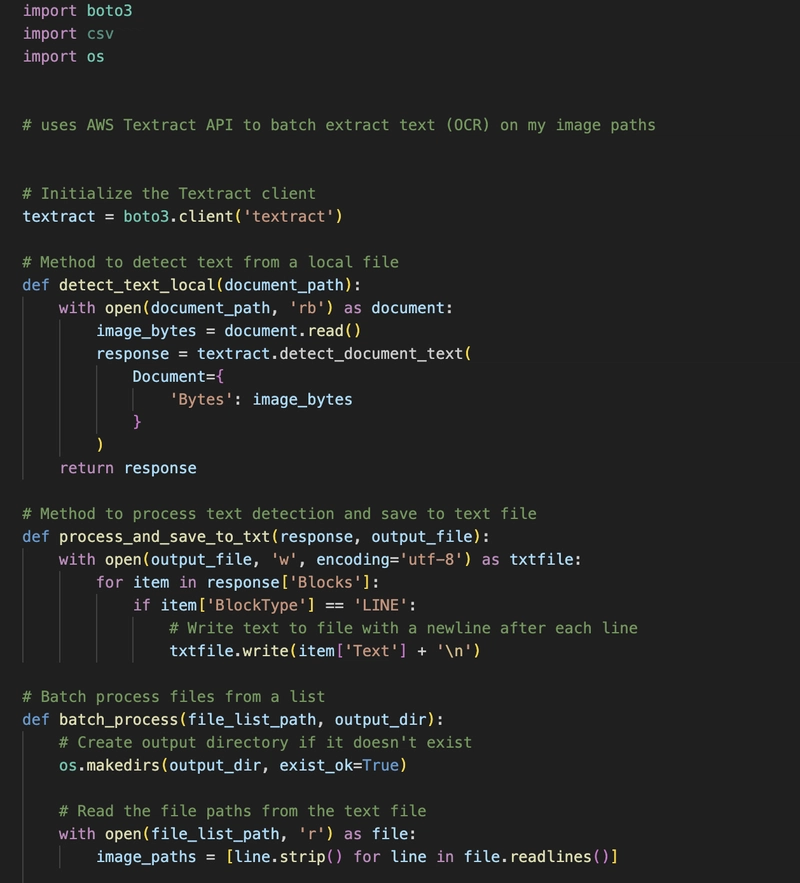
Method 1: Using AWS Textract API
This method leverages Amazon's powerful Textract OCR service to extract text from images. It works well for printed text, especially on structured documents.
Features:
- Batch process multiple files
- Automatically saves extracted content to .txt files
- Supports line-by-line text extraction
- Easy to extend and integrate
Sample code:
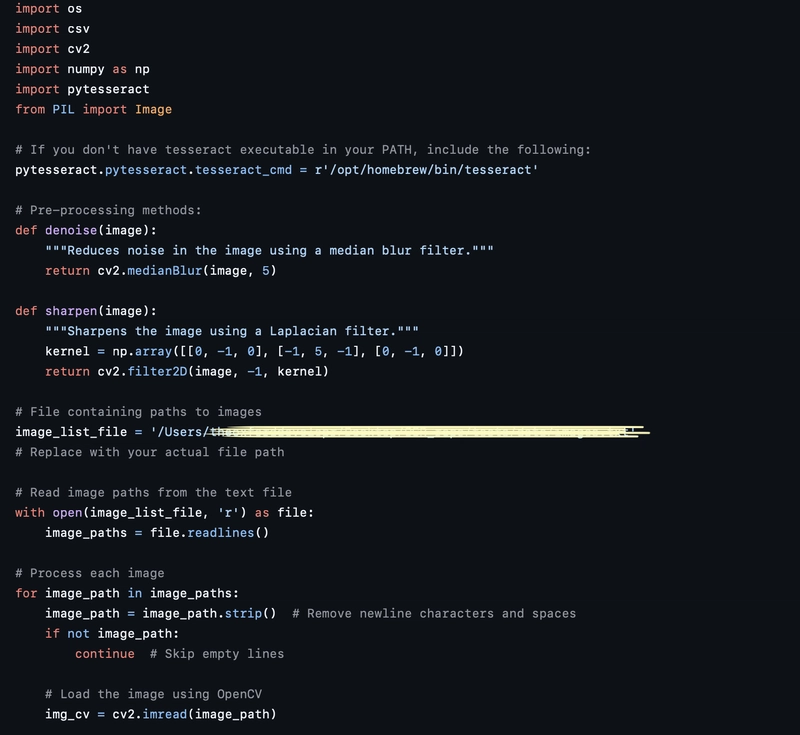
Method 2: Pytesseract
Tools We Use
- Python
- OpenCV – For image processing
- Pytesseract – A Python wrapper for Google’s Tesseract-OCR Engine
- Pillow (PIL) – For additional image support
- CSV – To export results
Before diving into the code, make sure you have Tesseract installed and properly linked in your script. For macOS users:
pytesseract.pytesseract.tesseract_cmd = r'/opt/homebrew/bin/tesseract'
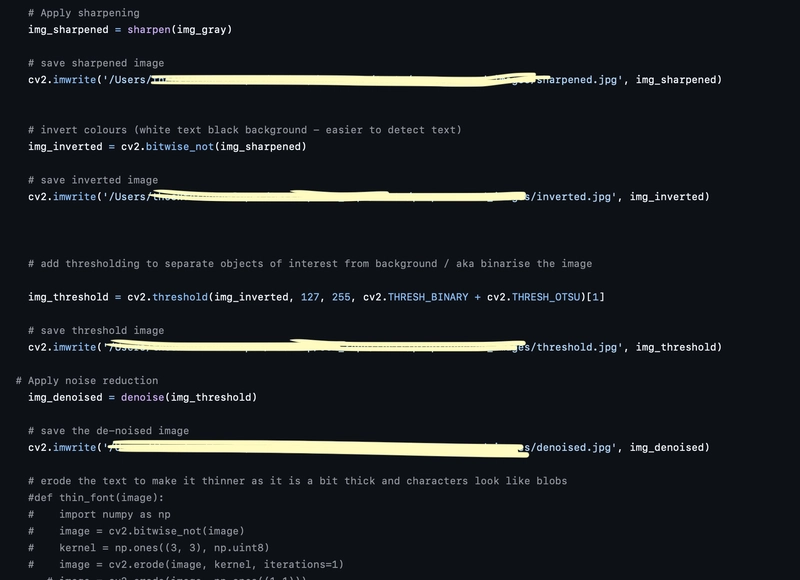
Step 1: Image Preprocessing Pipeline
OCR engines work best when the input text is clear, contrast-rich, and isolated from background noise. Here's the sequence of transformations applied to each image:
Grayscale Conversion
Converting the image to grayscale helps reduce complexity and makes it easier to isolate text.Sharpening
We apply a Laplacian filter to enhance edges and make the text pop.Inversion
OCR engines often perform better when text is black on a white background.Thresholding
We binarise the image using Otsu’s method, separating text from background.Denoising
Removing small artifacts with a median blur filter.Font Smoothing (Optional)
If text appears too thin or thick, you can apply morphological operations (dilation/erosion).
Step 2: OCR Text Extraction
Once the image is processed, we convert it back to RGB (required by Tesseract) and extract the text.
Step 3: Save to CSV
Finally, we store the extracted text in a CSV file for later use.
Sample code:
What Next?
Once your text is extracted, check out my companion repository:
https://github.com/TheOxfordDeveloper/Parsing-unstructured-data.git
It shows how to clean and convert raw OCR text into structured, tabular formats, like this: