![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)


















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)









































































































![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)

![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)














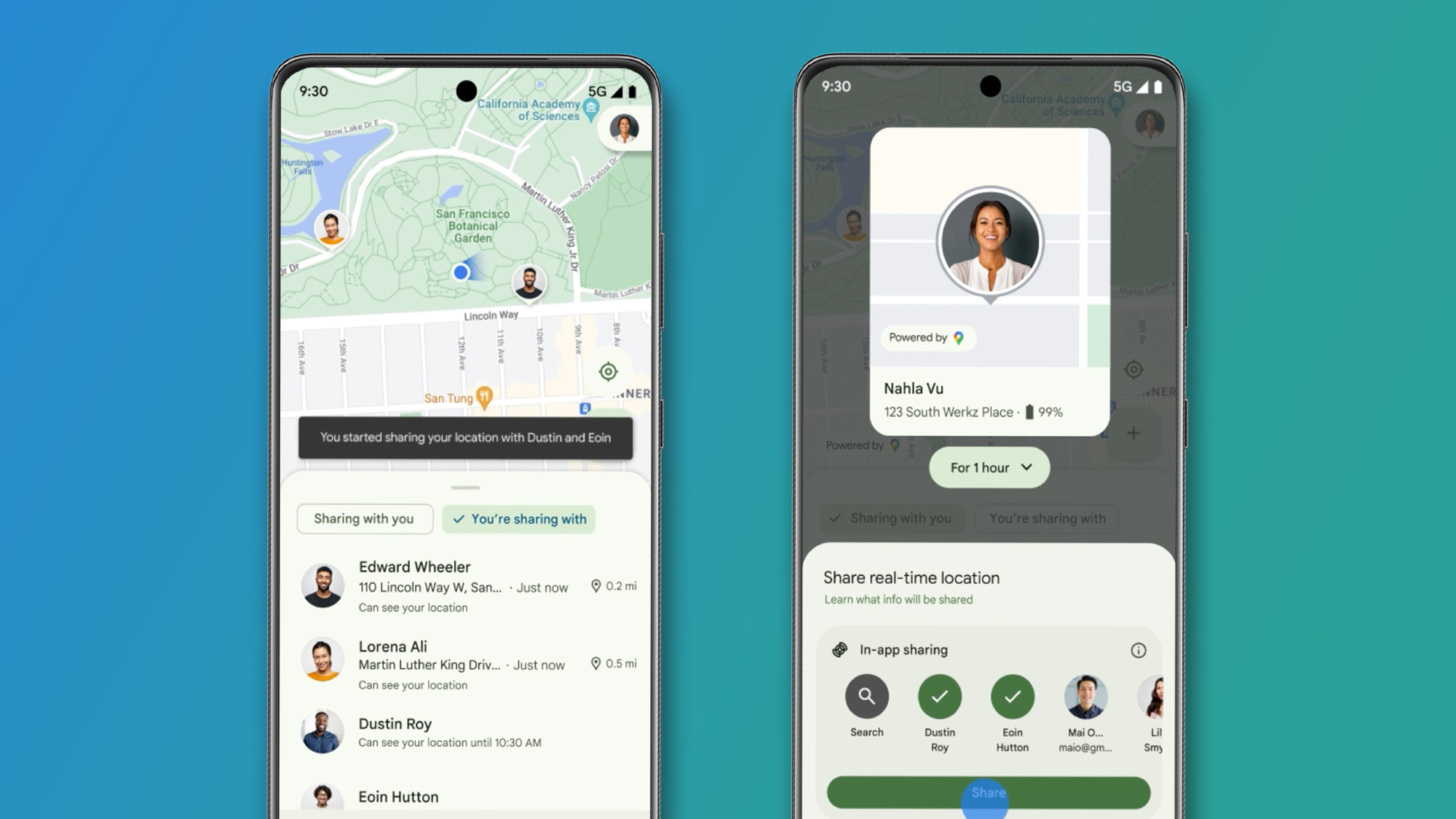
















































































VideoLLM Cuts Redundancy: 80% of Video Tokens Unnecessary!
This is a Plain English Papers summary of a research paper called VideoLLM Cuts Redundancy: 80% of Video Tokens Unnecessary!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. The Streaming Video Problem: Why We Need Better Real-Time Video Understanding The explosion of online video platforms and real-time applications has created an urgent need for systems that can process continuous video streams and respond to user queries instantaneously. These streaming video scenarios pose unique challenges that current Video Large Language Models (VideoLLMs) aren't equipped to handle efficiently. Two fundamental obstacles stand in the way of effective streaming video understanding: Long-form high-redundant video context: Streaming videos deliver frames at high rates (1-10 FPS) with substantial visual similarity between consecutive frames, creating redundancy. And since streams can be potentially infinite, systems must maintain extensive temporal context. Real-time interaction with proactive responding: Users expect immediate responses to queries about past content (backward tracing), current frames (real-time perception), and even future content not yet available (proactive responding). While recent VideoLLMs excel at processing complete videos, they struggle with streaming scenarios. Models that sample sparse frames miss critical visual context, while those processing dense frames face excessive computational burden and response delays. Illustration of TimeChat-Online and its Differential Token Drop mechanism showing how it eliminates redundant tokens while maintaining accuracy. To address these challenges, researchers from Peking University, South China University of Technology, The University of Hong Kong, and Kuaishou Technology introduce TimeChat-Online, a novel approach that revolutionizes real-time video interaction. At its core lies the innovative Differential Token Drop (DTD) module, which addresses the fundamental challenge of visual redundancy in streaming videos. DTD takes inspiration from human visual perception, specifically the Change Blindness phenomenon, preserving only meaningful temporal changes while filtering out static, redundant content between frames. The experiments reveal a stunning finding: DTD achieves an 82.8% reduction in video tokens while maintaining 98% performance on benchmark tasks, suggesting that over 80% of visual content in streaming videos is naturally redundant. Previous Approaches to Video Understanding Recent advancements in streaming video understanding have followed two main directions. The first approach focuses on efficiently encoding dense video streams. Memory-bank-based methods like VideoLLM-Online, VideoStreaming, Flash-VStream, StreamChat, and VideoChat-online use dynamic memory banks to retain informative video tokens. Other approaches like ReKV and Inf-MLLM optimize KV Cache management, while VideoLLM-MoD employs Mixture-of-Depth to reduce token count. Most of these methods require language guidance from user queries to select relevant video content. In contrast, TimeChat-Online's DTD reduces video tokens by over 80% purely at the visual level before any language model processing, making it more efficient than language-guided approaches. The second direction enhances real-time interaction experiences. Models like IXC2.5-Omni and Qwen2.5-Omni incorporate audio modality, while MMDuet refines video-text interaction formats. Dispider introduces a disentangled Perception-Decision-Reaction paradigm. TimeChat-Online differs by implementing a novel proactive response paradigm leveraging DTD's ability to detect scene transitions. Efficient video token pruning has been extensively explored in recent years. Some approaches compress frames or clips to a fixed number, disregarding the dynamic visual redundancy inherent in different videos. Others design adaptive token merging in either spatial or temporal dimensions, but often blur the vanilla spatial-temporal positions which hurts fine-grained video perception. Language-guided approaches leverage user queries or vision-language cross-attention mechanisms for token pruning. However, these methods are inefficient for streaming scenarios, as they require reprocessing all historical frames for each new user query. TimeChat-Online's DTD efficiently processes video streams by calculating redundancy only for newly-arriving frames, resulting in faster response times. The TimeChat-Online Architecture: How Differential Token Dropping Works TimeChat-Online represents a significant advancement in streaming video understanding, with its core innovation being the Differential Token Drop (DTD) mechanism that efficiently processes video streams. Detailed illustration of the DTD mechanism showing the three key steps of the approach. Understanding Streaming Video Question Answering In streaming video scenarios, frames arrive continuously ra

This is a Plain English Papers summary of a research paper called VideoLLM Cuts Redundancy: 80% of Video Tokens Unnecessary!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Streaming Video Problem: Why We Need Better Real-Time Video Understanding
The explosion of online video platforms and real-time applications has created an urgent need for systems that can process continuous video streams and respond to user queries instantaneously. These streaming video scenarios pose unique challenges that current Video Large Language Models (VideoLLMs) aren't equipped to handle efficiently.
Two fundamental obstacles stand in the way of effective streaming video understanding:
Long-form high-redundant video context: Streaming videos deliver frames at high rates (1-10 FPS) with substantial visual similarity between consecutive frames, creating redundancy. And since streams can be potentially infinite, systems must maintain extensive temporal context.
Real-time interaction with proactive responding: Users expect immediate responses to queries about past content (backward tracing), current frames (real-time perception), and even future content not yet available (proactive responding).
While recent VideoLLMs excel at processing complete videos, they struggle with streaming scenarios. Models that sample sparse frames miss critical visual context, while those processing dense frames face excessive computational burden and response delays.
Illustration of TimeChat-Online and its Differential Token Drop mechanism showing how it eliminates redundant tokens while maintaining accuracy.
To address these challenges, researchers from Peking University, South China University of Technology, The University of Hong Kong, and Kuaishou Technology introduce TimeChat-Online, a novel approach that revolutionizes real-time video interaction. At its core lies the innovative Differential Token Drop (DTD) module, which addresses the fundamental challenge of visual redundancy in streaming videos.
DTD takes inspiration from human visual perception, specifically the Change Blindness phenomenon, preserving only meaningful temporal changes while filtering out static, redundant content between frames. The experiments reveal a stunning finding: DTD achieves an 82.8% reduction in video tokens while maintaining 98% performance on benchmark tasks, suggesting that over 80% of visual content in streaming videos is naturally redundant.
Previous Approaches to Video Understanding
Recent advancements in streaming video understanding have followed two main directions.
The first approach focuses on efficiently encoding dense video streams. Memory-bank-based methods like VideoLLM-Online, VideoStreaming, Flash-VStream, StreamChat, and VideoChat-online use dynamic memory banks to retain informative video tokens. Other approaches like ReKV and Inf-MLLM optimize KV Cache management, while VideoLLM-MoD employs Mixture-of-Depth to reduce token count. Most of these methods require language guidance from user queries to select relevant video content.
In contrast, TimeChat-Online's DTD reduces video tokens by over 80% purely at the visual level before any language model processing, making it more efficient than language-guided approaches.
The second direction enhances real-time interaction experiences. Models like IXC2.5-Omni and Qwen2.5-Omni incorporate audio modality, while MMDuet refines video-text interaction formats. Dispider introduces a disentangled Perception-Decision-Reaction paradigm. TimeChat-Online differs by implementing a novel proactive response paradigm leveraging DTD's ability to detect scene transitions.
Efficient video token pruning has been extensively explored in recent years. Some approaches compress frames or clips to a fixed number, disregarding the dynamic visual redundancy inherent in different videos. Others design adaptive token merging in either spatial or temporal dimensions, but often blur the vanilla spatial-temporal positions which hurts fine-grained video perception.
Language-guided approaches leverage user queries or vision-language cross-attention mechanisms for token pruning. However, these methods are inefficient for streaming scenarios, as they require reprocessing all historical frames for each new user query. TimeChat-Online's DTD efficiently processes video streams by calculating redundancy only for newly-arriving frames, resulting in faster response times.
The TimeChat-Online Architecture: How Differential Token Dropping Works
TimeChat-Online represents a significant advancement in streaming video understanding, with its core innovation being the Differential Token Drop (DTD) mechanism that efficiently processes video streams.
Detailed illustration of the DTD mechanism showing the three key steps of the approach.
Understanding Streaming Video Question Answering
In streaming video scenarios, frames arrive continuously rather than being available all at once. When a user poses a question at timestamp t, the system must leverage the current frame and all previous frames to generate an appropriate response.
What makes streaming video particularly challenging is the need for proactive responding. When a user asks a question that can't be fully answered with currently available content, the system should generate a response at a future timestamp when sufficient visual information becomes available. As shown in the figure above, if a user asks "How does the man cook the cauliflower?" at t=10s, the system should proactively respond with updates at t=25s ("He chops the cauliflower") and t=35s ("He puts the cauliflower into the frying pan") as new visual content becomes available.
Existing offline VideoLLMs struggle with streaming scenarios for two reasons:
- They can't efficiently handle dense video frames at high FPS rates
- They lack proactive response capabilities for future-requiring questions
Differential Token Drop: The Key Innovation
The Differential Token Drop (DTD) mechanism draws inspiration from human visual perception, specifically the Change Blindness phenomenon where humans often miss visual changes between scenes. Like the human visual system, DTD focuses on salient temporal changes while filtering out static, redundant content.
DTD operates in three key steps:
Patchify and Encoding: Each video frame is split into visual patches and encoded into spatial tokens using a Vision Transformer (ViT).
Static Redundancy Calculation: DTD calculates redundancy between temporally consecutive frames at both the pixel level (using L1 distance) and feature level (using cosine similarity).
Position-aware Token Dropping: Redundant tokens are dropped while preserving the spatial-temporal positions of the remaining tokens, maintaining the video's structural integrity.
What makes DTD particularly effective is that it works purely at the visual level without requiring any textual information or language guidance. This approach significantly reduces the computational burden of processing video tokens before they even reach the language model.
Creating the TimeChat-Online-139K Dataset
To train TimeChat-Online effectively, the researchers created a comprehensive dataset specifically designed for streaming VideoQA tasks. The TimeChat-Online-139K dataset was developed through a systematic four-step process:
Visually Informative Video Collection: They collected 11,043 long-form videos with diverse scene changes, averaging 11.1 minutes per video.
Scene-oriented Detailed Caption Generation: Using GPT-4o, they generated comprehensive descriptions for key frames, covering both static and dynamic visual elements.
Streaming VideoQA Generation: They produced diverse question-answer pairs across four categories: Temporal-enhanced, Backward Tracing, Real-Time Visual Perception, and Forward Active Responding.
Negative Samples for Future-Response Training: They constructed samples intentionally unanswerable with current video content, labeling them accordingly to train the model's proactive responding capabilities.
This dataset encompasses a wide range of video sources and durations, with detailed annotations that enable the model to handle diverse interaction patterns in streaming scenarios.
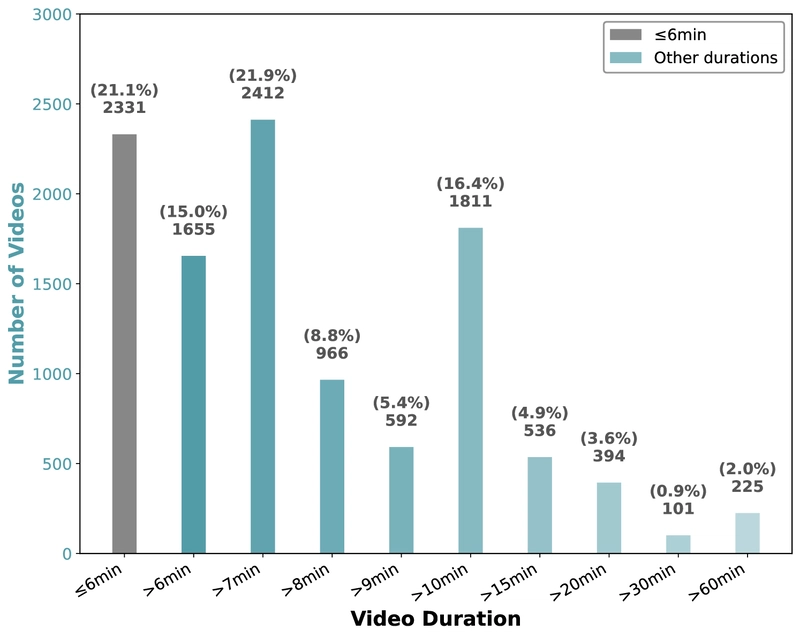
Distribution of video durations across the dataset, with a minimum video length of 5 minutes.
Training and Running TimeChat-Online in Real-Time
The TimeChat-Online model is implemented based on the long-context Qwen2.5-VL architecture to support high-FPS dense frame processing. During training, frames are densely sampled at 1 FPS with DTD applied with 50% probability to each training batch. The training combines the TimeChat-Online-139K dataset with offline video understanding datasets to ensure robust performance.
During inference, TimeChat-Online processes video frames at 1 FPS and uses DTD to drop approximately 85% of video tokens. A first-in-first-out memory bank stores the slimmed historical video tokens with a maximum latency of 2 seconds for responding.
A key innovation is the Proactive Response with Trigger Time capability. The system identifies optimal timestamps (Trigger times) to generate proactive responses, typically occurring when the video transitions to a new scene. These transitions are effectively monitored through the token drop ratio curve, with valleys indicating moments of significant change. The model generates responses at each trigger time using the most recent video content, providing "unanswerable" responses when available content is insufficient.
Experimental Results: Proving DTD's Effectiveness
The researchers conducted extensive experiments to evaluate TimeChat-Online's performance across various benchmarks and to analyze the effectiveness of the DTD mechanism.
Implementation Details
TimeChat-Online is built upon the Qwen2.5VL 7B architecture, sampling frames at 1 FPS with a maximum resolution of 448×448 pixels. The training combines offline datasets (LLaVA-Video-178K, Tarsier2, VideoChat-Flash) with the TimeChat-Online-139K dataset. During inference, the system extends to a maximum frame length of 1016, with feature-level dropping set to achieve around 85% token reduction.
Outstanding Performance on Streaming Video Tasks
TimeChat-Online demonstrates exceptional performance on streaming video benchmarks, outperforming both offline and online VideoLLMs.
| Model | #Frames VTokens(%) | OP | CR | CS | ATP | EU | TR | PR | SU | ACP | CT | All | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Human | - | - | 89.47 | 92.00 | 93.60 | 91.47 | 95.65 | 92.52 | 88.00 | 88.75 | 89.74 | 91.30 | 91.46 |
| Proprietary MLLMs | |||||||||||||
| Gemini 1.5 pro [18] | 1 fps | - | 79.02 | 80.47 | 83.54 | 79.67 | 80.00 | 84.74 | 77.78 | 64.23 | 71.95 | 48.70 | 75.69 |
| GPT-4o [41] | 64 | - | 77.11 | 80.47 | 83.91 | 76.47 | 70.19 | 83.80 | 66.67 | 62.19 | 69.12 | 49.22 | 73.28 |
| Claude 3.5 Sonnet [2] | 20 | - | 73.33 | 80.47 | 84.09 | 82.02 | 75.39 | 79.53 | 61.11 | 61.79 | 69.32 | 43.09 | 72.44 |
| Open-source Offline VideoLLMs | |||||||||||||
| Video-LLaMA2-7B [9] | 32 | - | 55.86 | 55.47 | 57.41 | 58.17 | 52.80 | 43.61 | 39.81 | 42.68 | 45.61 | 35.23 | 49.52 |
| VILA-1.5-8B [34] | 14 | - | 53.68 | 49.22 | 70.98 | 56.86 | 53.42 | 53.89 | 54.63 | 48.78 | 50.14 | 17.62 | 52.32 |
| Video-CCAM-14B [16] | 96 | - | 56.40 | 57.81 | 65.30 | 62.75 | 64.60 | 51.40 | 42.59 | 47.97 | 49.58 | 31.61 | 53.96 |
| LongVA-7B [79] | 128 | - | 70.03 | 63.28 | 61.20 | 70.92 | 62.73 | 59.50 | 61.11 | 53.66 | 54.67 | 34.72 | 59.96 |
| InternVL-V2-8B [8] | 16 | - | 68.12 | 60.94 | 69.40 | 77.12 | 67.70 | 62.93 | 59.26 | 53.25 | 54.96 | 56.48 | 63.72 |
| Kangaroo-7B [36] | 64 | - | 71.12 | 84.38 | 70.66 | 73.20 | 67.08 | 61.68 | 56.48 | 55.69 | 62.04 | 38.86 | 64.60 |
| LLaVA-NoXT-Video-32B [35] | 64 | - | 78.20 | 70.31 | 73.82 | 76.80 | 63.35 | 69.78 | 57.41 | 56.10 | 64.31 | 38.86 | 66.96 |
| MiniCPM-V-2.6-8B [19] | 32 | - | 71.93 | 71.09 | 77.92 | 75.82 | 64.60 | 65.73 | 70.37 | 56.10 | 62.32 | 53.37 | 67.44 |
| LLaVA-OneVision-7B [24] | 32 | - | 80.38 | 74.22 | 76.03 | 80.72 | 72.67 | 71.65 | 67.59 | 65.45 | 65.72 | 45.08 | 71.12 |
| Qwen2.5-VL-7B [5] | 1 fps | 78.32 | 80.47 | 78.86 | 80.45 | 76.73 | 78.50 | 79.63 | 63.41 | 66.19 | 53.19 | 73.68 | |
| Open-source Online VideoLLMs | |||||||||||||
| Flash-VStream-7B [75] | - | - | 25.89 | 43.57 | 24.91 | 23.87 | 27.33 | 13.08 | 18.52 | 25.20 | 23.87 | 48.70 | 23.23 |
| VideoLLM-online-8B [6] | 2 fps | - | 39.07 | 40.06 | 34.49 | 31.05 | 45.96 | 32.40 | 31.48 | 34.16 | 42.49 | 27.89 | 35.99 |
| Doppler-7B [43] | 1 fps | - | 74.92 | 75.53 | 74.10 | 73.08 | 74.44 | 59.92 | 76.14 | 62.91 | 62.16 | 45.80 | 67.63 |
| TimeChat-Online-7B | 1 fps | 44.2% | 80.76 | 79.69 | 80.76 | 83.33 | 74.84 | 78.82 | 78.70 | 64.23 | 68.75 | 57.98 | 75.28 |
| TimeChat-Online-7B | 1 fps | 17.4% | 79.13 | 81.25 | 78.86 | 80.77 | 70.44 | 77.26 | 77.78 | 67.07 | 66.19 | 53.72 | 73.64 |
| TimeChat-Online-7B | 1 fps | 100% | 80.22 | 82.03 | 79.50 | 83.33 | 76.10 | 78.50 | 78.70 | 64.63 | 69.60 | 57.98 | 75.36 |
Performance comparison on StreamingBench focusing on Real-Time Visual Understanding tasks across various subtasks including Object Perception (OP), Causal Reasoning (CR), Clips Summarization (CS), and others. "VTokens(%)" represents the percentage of video tokens remaining after dropping.
On StreamingBench, TimeChat-Online achieves a state-of-the-art score of 75.28 on Real-time Visual Understanding, representing a 7.65-point improvement over Dispider-7B. Impressively, it maintains 98% of its performance even with 82.8% token reduction, demonstrating the substantial redundancy in video streams.
| Model | #Frames | Real-Time Visual Perception | Backward Tracing | Forward Active Responding | Overall | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OCR | ACR | ATR | STU | FPD | OJR | Avg. | EPM | ASI | HLD | Avg. | REC | SSR | CRR | Avg. | Avg. | ||
| Human Agents | - | 94.0 | 92.6 | 94.8 | 92.7 | 91.1 | 94.0 | 93.2 | 92.6 | 93.0 | 91.4 | 92.3 | 95.5 | 89.7 | 93.6 | 92.9 | 92.8 |
| Proprietary Multimodal Models | |||||||||||||||||
| Gemini 1.5 Pro | 1fps | 87.3 | 67.0 | 80.2 | 54.5 | 68.3 | 67.4 | 70.8 | 68.6 | 75.7 | 52.7 | 62.3 | 35.5 | 74.2 | 61.7 | 57.2 | 65.3 |
| GPT-4o | 64 | 69.1 | 65.1 | 65.5 | 50.0 | 68.3 | 63.7 | 63.6 | 49.8 | 71.0 | 55.4 | 58.7 | 27.6 | 73.2 | 59.4 | 53.4 | 58.6 |
| Open-source Offline VideoLLMs | |||||||||||||||||
| LLaVA-NeXT-Video-7B | 64 | 69.8 | 59.6 | 66.4 | 50.6 | 72.3 | 61.4 | 63.3 | 51.2 | 64.2 | 9.7 | 41.7 | 34.1 | 67.6 | 60.8 | 54.2 | 53.1 |
| LLaVA-OmVision-7B | 64 | 67.1 | 58.7 | 69.8 | 49.4 | 71.3 | 60.3 | 62.8 | 52.5 | 58.8 | 23.7 | 45.0 | 24.8 | 66.9 | 60.8 | 50.9 | 52.9 |
| Qwen2-VL-7B | 64 | 69.1 | 53.2 | 63.8 | 50.6 | 66.3 | 60.9 | 60.7 | 44.4 | 66.9 | 34.4 | 48.6 | 30.1 | 65.7 | 50.8 | 48.9 | 52.7 |
| InternVL-V2-8B | 64 | 68.5 | 58.7 | 69.0 | 44.9 | 67.3 | 56.0 | 60.7 | 43.1 | 61.5 | 27.4 | 44.0 | 25.8 | 57.6 | 52.9 | 45.4 | 50.1 |
| LongVU-7B | 1fps | 55.7 | 49.5 | 59.5 | 48.3 | 68.3 | 63.0 | 57.4 | 43.1 | 66.2 | 9.1 | 39.5 | 16.6 | 69.0 | 60.0 | 48.5 | 48.5 |
| Open-source Online Video-LLMs | |||||||||||||||||
| Flash-VStream-7B | 1fps | 25.5 | 32.1 | 29.3 | 33.7 | 29.7 | 28.8 | 29.9 | 36.4 | 33.8 | 5.9 | 25.4 | 5.4 | 67.3 | 60.0 | 44.2 | 33.2 |
| VideoLLM-online-8B | 2fps | 8.1 | 23.9 | 12.1 | 14.0 | 45.5 | 21.2 | 20.8 | 22.2 | 18.8 | 12.2 | 17.7 | |||||
| TimeChat-Online-7B | 1fps ( 244.6%) | 74.5 | 48.6 | 68.1 | 48.3 | 69.3 | 59.8 | 61.4 | 56.9 | 64.9 | 11.8 | 44.5 | 31.8 | 38.5 | 40.0 | 36.8 | 47.6 ( +14.4 ) |
| TimeChat-Online-7B | 1fps ( 284.8%) | 69.8 | 48.6 | 64.7 | 44.9 | 68.3 | 55.4 | 58.6 | 53.9 | 62.8 | 9.1 | 42.0 | 32.5 | 36.5 | 40.0 | 36.4 | 42.6 ( +12.4 ) |
| TimeChat-Online-7B | 1fps (100%) | 75.2 | 46.8 | 70.7 | 47.8 | 69.3 | 61.4 | 61.9 | 55.9 | 59.5 | 9.7 | 41.7 | 31.6 | 38.5 | 40.0 | 36.7 | 46.7 |
Evaluation results on OVO-Bench comprising three categories: i) Real-Time Visual Perception, ii) Backward Tracing, and iii) Forward Active Responding across 12 diverse subtasks.
On OVO-Bench, TimeChat-Online substantially outperforms existing online VideoLLMs, achieving a score of 47.6, representing a 14.4-point absolute improvement over Flash-VStream and VideoLLM-online. Even with 84.8% token reduction, it maintains robust performance with a score of 45.6.
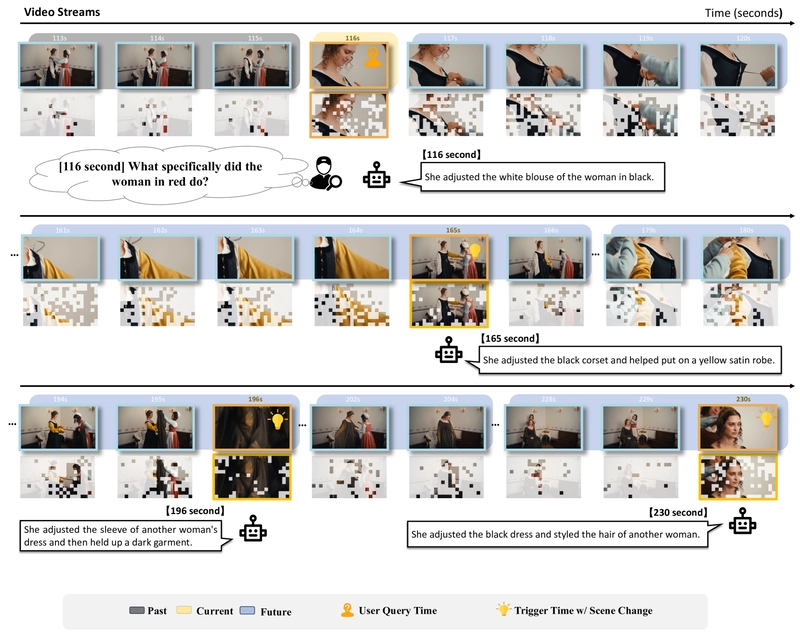
Case study showing how TimeChat-Online generates proactive responses at future trigger times for the question "What specifically did the woman in red do?"
Strong Results Even on Offline Long Video Tasks
TimeChat-Online also demonstrates impressive performance on offline long-form video understanding benchmarks, particularly excelling with extremely long videos.
| Model | #Frames | MLVU | LongVideoBench | VideoMME | |
|---|---|---|---|---|---|
| overall | long | ||||
| Video Length | - | 3-120 min | 8 sec -60 min | 1-60 min | 30-60 min |
| Open-Source Offline VideoLLMs | |||||
| LLaMA-VID-7B | 1 fps | 33.2 | - | - | - |
| Movi-Chat-7B | 2048 | 25.8 | - | 38.2 | 33.4 |
| LLaVA-Nexi-Video-7B | 32 | - | 43.5 | 46.6 | - |
| VideoChat2-7B | 16 | 47.9 | 39.3 | 39.5 | 33.2 |
| LongVA-7B | 128 | 56.3 | - | 52.6 | 46.2 |
| Kangaroo-7B | 64 | 61.0 | 54.2 | 56.0 | 46.6 |
| Video-CCAM-14B | 96 | 63.1 | - | 53.2 | 46.7 |
| VideoXL-7B | 128 | 64.9 | - | 55.5 | 49.2 |
| Qwen2.5-VL-7B † | 1 fps ( 100% ) | 66.9 | 61.5 | 63.2 | 50.4 |
| Qwen2.5-VL-7B w DTD | 1 fps ( 46.2% ) | 68.6 | 61.6 | 63.4 | 51.9 |
| Qwen2.5-VL-7B w DTD | 1 fps ( 84.6% ) | 68.8 | 59.3 | 64.9 | 56.1 |
| Open-source Online VideoLLMs | |||||
| Doppler-7B wVVR 2025 | 1 fps | 61.7 | - | 57.2 | - |
| VideoChat-Online-8B wVVR 2025 | 2 fps | - | - | 52.8 | 44.9 |
| TimeChat-Online-7B | 1 fps ( 100% ) | 62.6 | 55.4 | 62.4 | 48.4 |
| TimeChat-Online-7B | 1 fps ( 46.3% ) | 62.9 | 57.1 | 63.3 | 52.4 |
| TimeChat-Online-7B | 1 fps ( 85.0% ) | 65.4 | 57.7 | 62.5 | 49.2 |
Results on offline long video benchmarks showing accuracy on MLVU, LongVideoBench and VideoMME (without subtitles).
Compared to VideoChat-Online, TimeChat-Online achieves a 7.5-point improvement on the long subset of VideoMME which contains videos ranging from 30 to 60 minutes in length. Surprisingly, increasing token drop ratio from 46.2% to 84.6% consistently improves Qwen2.5-VL-7B's performance on MLVU and VideoMME, outperforming the full token setting. For VideoMME's long subset, accuracy rises from 50.4 to 56.1 using only 15.4% of retained video tokens.
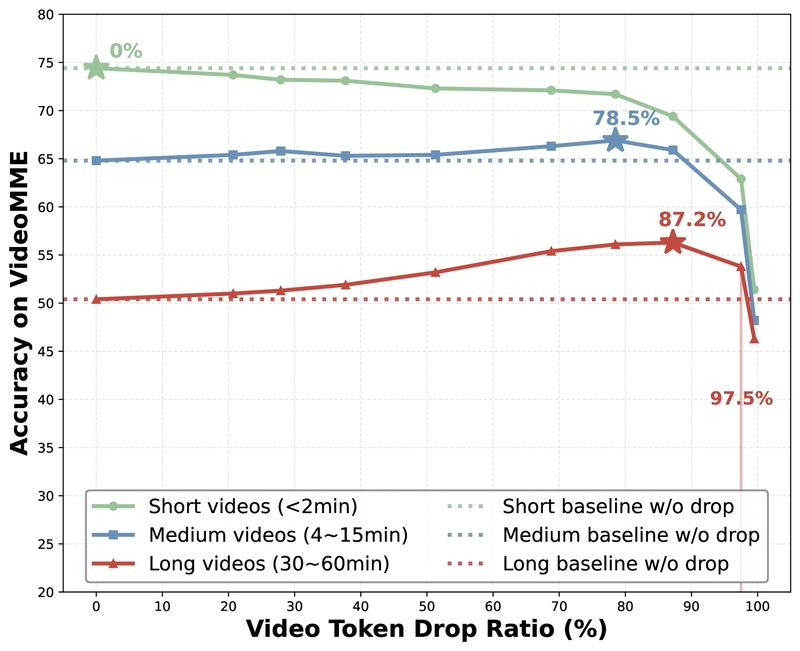
Graph showing video redundancy levels across different video lengths on VideoMME.
Ablation Study: What Makes DTD Work?
The researchers conducted ablation studies to understand the effectiveness of different token dropping strategies.
| Method w/o SFT | StreamingBench ( 24 min) | Δ |
|---|---|---|
| Vanilla, Avg 228, Video Tokens per Video (1 fps) | ||
| Qwen2.5VL-7B | 73.7 | 100% |
| Drop 44.1%, Avg 128, Video Tokens per Video | ||
| + VisionZip | 72.3 | 98.1% |
| + Pixel-level drop | 72.8 | 98.8% |
| + Feature-level drop (frame-aware) | 73.0 | 99.1% |
| + Feature-level drop (video-aware) | 73.4 | 99.6% |
| Drop 82.5%, Avg 48, Tokens per Video | ||
| + VisionZip | 68.8 | 93.4% |
| + Pixel-level drop | 68.8 | 93.4 |