![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)


















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)









































































































![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)

![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)






























































































GreenMind: Next-Gen Vietnamese LLM Excels at Reasoning
This is a Plain English Papers summary of a research paper called GreenMind: Next-Gen Vietnamese LLM Excels at Reasoning. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Enhancing Vietnamese AI with Step-by-Step Reasoning Capabilities Language models often produce direct answers without showing their reasoning, which leads to errors in complex tasks. This is particularly challenging for Vietnamese language models, which can suffer from language mixing issues when generating long-form responses. GreenMind-Medium-14B-R1 addresses these challenges as a Vietnamese language model specifically designed for structured reasoning through chain-of-thought (CoT) methodology. Unlike models that simply predict the next token, GreenMind generates detailed reasoning paths before arriving at conclusions. The model tackles two key limitations in Vietnamese language models: language mixing (where English or Chinese characters appear in Vietnamese text) and factual accuracy in reasoning chains. By implementing specialized reward functions during training, GreenMind maintains Vietnamese language consistency while producing logical, step-by-step explanations that lead to correct answers. A visualization of the reasoning data curation process for the GreenMind model, showing how instructions, context, and reasoning chains are assembled. Building on Previous Research Chain-of-Thought: Thinking Step-by-Step Chain-of-Thought (CoT) prompting encourages models to "think step by step" by providing examples with intermediate reasoning steps. This approach has shown remarkable success in improving performance on complex reasoning tasks. Empirical results demonstrate that CoT significantly enhances performance on arithmetic, commonsense, and symbolic reasoning benchmarks. For example, a 540-billion-parameter model achieved state-of-the-art accuracy on GSM8K using just eight CoT examples. Follow-up work on self-consistency decoding samples multiple reasoning paths and selects the most consistent answer, yielding substantial performance gains across various benchmarks including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), and others. These improvements reveal that structured intermediate reasoning emerges as a capability in sufficiently large models, making it valuable for Vietnamese language processing as well. The approach has been extended to multimodal tasks as shown in research on multimodal chain-of-thought reasoning in language models. The Emerging Landscape of Vietnamese Language Models While relatively new, the domain of open-source Vietnamese language models has several notable entries: Vietcuna models (3B and 7B-v3) developed from BLOOMZ base models and trained on 12GB of Vietnamese news texts URA-LLaMA models (7B and 13B) based on LLaMA-2 and pre-trained on Vietnamese Wikipedia and news content PhoGPT series with a base 7.5B-parameter model and instruction-following variants These models typically follow a development pattern of base pre-training followed by instruction fine-tuning, but most lack specific optimization for step-by-step reasoning capabilities. Group Relative Policy Optimization: A More Efficient Approach Group Relative Policy Optimization (GRPO) is a reinforcement learning technique that improves reasoning abilities in large language models. When applied to LLMs, this approach helps fine-tune models to better align with human preferences and improve performance on specialized tasks requiring complex reasoning. GRPO was initially introduced in DeepSeekMath to enhance mathematical problem-solving and code generation capabilities. It uses two primary reward types: Format rewards - Evaluates the model's ability to generate responses with the desired structure Accuracy rewards - Determines whether the extracted result matches the ground truth This approach offers advantages over traditional Proximal Policy Optimization (PPO) methods, particularly in computational efficiency while maintaining or improving performance. Creating a High-Quality Vietnamese Reasoning Dataset Defining the Problem and Approach The GreenMind dataset focuses on curating high-quality Vietnamese reasoning tasks with verifiable answers. Each instance consists of: A question-answer instruction (i) A corresponding reasoning chain (r) - a structured sequence of intermediate steps Supplementary context (c) retrieved from the web to enhance factual correctness The reasoning process is formally modeled as a function: f: I × C → R × A, which maps instructions and context to reasoning chains and answers. This structured approach ensures that reasoning is broken down into logical steps, making it easier to verify correctness and provide transparent explanations to users. Selecting Diverse and Challenging Instructions To ensure GreenMind's robustness, the team designed a multi-stage pipeline for se
This is a Plain English Papers summary of a research paper called GreenMind: Next-Gen Vietnamese LLM Excels at Reasoning. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Enhancing Vietnamese AI with Step-by-Step Reasoning Capabilities
Language models often produce direct answers without showing their reasoning, which leads to errors in complex tasks. This is particularly challenging for Vietnamese language models, which can suffer from language mixing issues when generating long-form responses.
GreenMind-Medium-14B-R1 addresses these challenges as a Vietnamese language model specifically designed for structured reasoning through chain-of-thought (CoT) methodology. Unlike models that simply predict the next token, GreenMind generates detailed reasoning paths before arriving at conclusions.
The model tackles two key limitations in Vietnamese language models: language mixing (where English or Chinese characters appear in Vietnamese text) and factual accuracy in reasoning chains. By implementing specialized reward functions during training, GreenMind maintains Vietnamese language consistency while producing logical, step-by-step explanations that lead to correct answers.
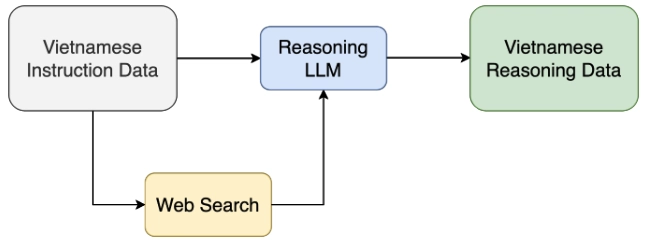
A visualization of the reasoning data curation process for the GreenMind model, showing how instructions, context, and reasoning chains are assembled.
Building on Previous Research
Chain-of-Thought: Thinking Step-by-Step
Chain-of-Thought (CoT) prompting encourages models to "think step by step" by providing examples with intermediate reasoning steps. This approach has shown remarkable success in improving performance on complex reasoning tasks.
Empirical results demonstrate that CoT significantly enhances performance on arithmetic, commonsense, and symbolic reasoning benchmarks. For example, a 540-billion-parameter model achieved state-of-the-art accuracy on GSM8K using just eight CoT examples.
Follow-up work on self-consistency decoding samples multiple reasoning paths and selects the most consistent answer, yielding substantial performance gains across various benchmarks including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), and others.
These improvements reveal that structured intermediate reasoning emerges as a capability in sufficiently large models, making it valuable for Vietnamese language processing as well. The approach has been extended to multimodal tasks as shown in research on multimodal chain-of-thought reasoning in language models.
The Emerging Landscape of Vietnamese Language Models
While relatively new, the domain of open-source Vietnamese language models has several notable entries:
- Vietcuna models (3B and 7B-v3) developed from BLOOMZ base models and trained on 12GB of Vietnamese news texts
- URA-LLaMA models (7B and 13B) based on LLaMA-2 and pre-trained on Vietnamese Wikipedia and news content
- PhoGPT series with a base 7.5B-parameter model and instruction-following variants
These models typically follow a development pattern of base pre-training followed by instruction fine-tuning, but most lack specific optimization for step-by-step reasoning capabilities.
Group Relative Policy Optimization: A More Efficient Approach
Group Relative Policy Optimization (GRPO) is a reinforcement learning technique that improves reasoning abilities in large language models. When applied to LLMs, this approach helps fine-tune models to better align with human preferences and improve performance on specialized tasks requiring complex reasoning.
GRPO was initially introduced in DeepSeekMath to enhance mathematical problem-solving and code generation capabilities. It uses two primary reward types:
- Format rewards - Evaluates the model's ability to generate responses with the desired structure
- Accuracy rewards - Determines whether the extracted result matches the ground truth
This approach offers advantages over traditional Proximal Policy Optimization (PPO) methods, particularly in computational efficiency while maintaining or improving performance.
Creating a High-Quality Vietnamese Reasoning Dataset
Defining the Problem and Approach
The GreenMind dataset focuses on curating high-quality Vietnamese reasoning tasks with verifiable answers. Each instance consists of:
- A question-answer instruction (i)
- A corresponding reasoning chain (r) - a structured sequence of intermediate steps
- Supplementary context (c) retrieved from the web to enhance factual correctness
The reasoning process is formally modeled as a function: f: I × C → R × A, which maps instructions and context to reasoning chains and answers.
This structured approach ensures that reasoning is broken down into logical steps, making it easier to verify correctness and provide transparent explanations to users.
Selecting Diverse and Challenging Instructions
To ensure GreenMind's robustness, the team designed a multi-stage pipeline for selecting instruction problems tailored for Vietnamese logical reasoning. The selection criteria emphasize:
- Task Type Diversity: Including arithmetic word problems, commonsense inference, symbolic logic, deductive reasoning, multi-hop question answering, and ethical dilemmas
- Linguistic Complexity: Samples across varying syntactic and lexical complexities to challenge understanding of nuanced Vietnamese expressions
- Reasoning Depth: Prioritizing tasks requiring multi-step deductions, analogical thinking, and counterfactual reasoning
- Verifiability: Manual verification or derivation from trusted Vietnamese educational and encyclopedic sources
This approach ensures that the model can handle a wide range of reasoning challenges in culturally and linguistically appropriate contexts.
Generating Clear and Coherent Reasoning Chains
Beyond having high-quality instructions, generating structured, verifiable reasoning chains is essential. The team adopted an automated pipeline incorporating web-scale retrieval to ensure factual correctness and logical coherence.
For each instruction, the process involves:
- Retrieving supplementary context from the web for factual grounding
- Generating a reasoning chain (r = s₁, s₂, ..., sₙ) with logically valid steps
- Applying quality control through:
- Consistency checks to verify logical progression
- Redundancy elimination to maintain conciseness
- Format conformity to ensure CoT compatibility
The team also included multiple valid reasoning chains for the same instruction to promote generalization and prevent memorization of fixed templates. This approach aligns with research on grounded chain-of-thought in multimodal large language models, which demonstrates the importance of solid factual grounding for reasoning.
Inside GreenMind: Architecture and Training Methodology
GreenMind-Medium-14B-R1 builds on the Qwen2.5-14B-Instruct model, which features a dense, decoder-only Transformer architecture with approximately 14.7 billion parameters. The model includes 48 layers with a hidden state dimensionality of 5,120 and incorporates SwiGLU feed-forward blocks and RMSNorm normalization.
Key architectural features include:
- Gated-Query Attention with 40 query heads and 8 key-value heads
- Rotary Position Embeddings combined with YaRN scaling
- Extended context window of up to 128,000 tokens
- Generation capacity of up to 8,192 tokens per request
The model was pre-trained on 18 trillion tokens across more than 29 languages, including Vietnamese. This was followed by supervised fine-tuning on over one million high-quality instruction-response pairs and reinforcement learning-based preference optimization.
For GreenMind's training, the team curated 55,418 high-quality Vietnamese instruction samples covering diverse domains:
- Mathematics: Problems that train symbolic reasoning and step-by-step problem solving
- Cultural: Vietnamese idioms, proverbs, traditions, and literary references
- Legal and Civic: Basic legal concepts and civic education in Vietnamese contexts
- Education: Real-world school and university-level examination formats
Two specialized reward functions were implemented to address key challenges:
- A format reward function to ensure structural correctness
- A semantic similarity reward function to maintain content quality and factual accuracy
Rigorous Testing and Evaluation
Training Setup and Implementation Details
The GreenMind model was fine-tuned with all parameters to ensure optimal performance and adaptability to Vietnamese reasoning tasks. The team used the DeepSpeed framework with ZeRO Stage 3 to efficiently partition optimizer states, gradients, and parameters across GPUs, allowing for training of models that would otherwise exceed device memory limitations.
Additional techniques included mixed-precision training to improve computational efficiency without sacrificing model accuracy. The fine-tuning process was conducted on 8 H100 GPUs.
| Hyperparameter | Value |
|---|---|
| epochs | 4 |
| per_device_train_batch_size | 1 |
| gradient_accumulation_steps | 8 |
| gradient_checkpointing | true |
| learning_rate | 5.0e-7 |
| lr_scheduler_type | cosine |
| warmup_ratio | 0.03 |
| beta | 0.001 |
| max_prompt_length | 256 |
| max_completion_length | 1024 |
| num_generations | 4 |
| use_vllm | true |
| vllm_gpu_memory_utilization | 0.9 |
Table 1: Training Hyperparameters used for fine-tuning GreenMind
For inference, the team employed the vLLM framework on a single GPU, balancing creativity with factual accuracy through carefully selected generation parameters:
| Hyperparameter | Value |
|---|---|
| Repetition Penalty | 1.2 |
| Temperature | 0.6 |
| Top-p (nucleus) | 0.8 |
| Top-k | 4 |
Table 2: vLLM Inferencing Hyperparameters used for generating outputs from GreenMind
Comprehensive Performance Analysis
After fine-tuning for approximately 4 epochs, the GRPO loss function showed a characteristic progression, starting at 0 and gradually increasing as the distributions of πθ and πref became more differentiated.
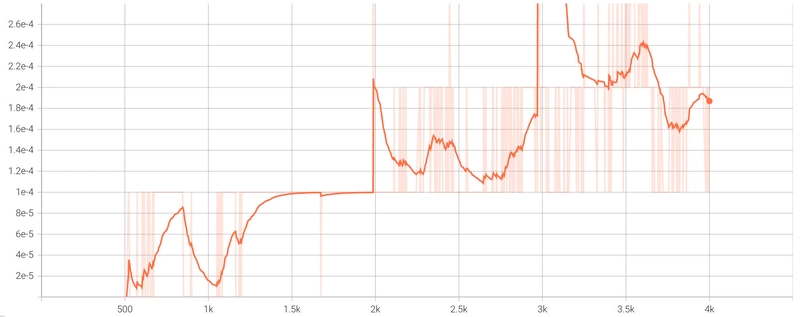
Training Loss progression during GreenMind's fine-tuning process.
The model was evaluated on multiple benchmarks, with particularly strong results on the SeaExam multiple-choice dataset, where GreenMind outperformed much larger models (up to 70B parameters) across Southeast Asian languages:
| Model | SeaExam-ID | SeaExam-TH | SeaExam-VI | Avg |
|---|---|---|---|---|
| Meta-Llama-3.1-70B-Insiruct | 65.8 | 70.6 | 72.6 | 69.7 |
| genma3-27b-ii | 64.4 | 67.5 | 73.1 | 68.4 |
| Qwen2.5-14B-Insiruct | 67.6 | 68.8 | 73.1 | 69.8 |
| GreenMind-Medium-14B-R1 | 74.36 | 69.75 | 74.44 | 72.79 |
Table 3: SeaExam performance compared to SOTA models, showing GreenMind's superior performance despite having fewer parameters
On the VMLU benchmark, which tests Vietnamese-specific capabilities, GreenMind demonstrated substantial improvements over previous models:
| Model | ComprehensionQA-vi | Exams-vi | LAMBADA-vi | WikiQA-vi | MMLU-vi |
|---|---|---|---|---|---|
| cpt-smartbot-13b | 0.6633 | 0.3473 | 21.9864 | 0.4455 | 0.414 |
| ura-llama-13b | 0.6556 | 0.342 | 17.5614 | 0.438 | 0.3973 |
| greennode-7b (prior work) | 0.6122 | 0.2892 | 189.7782 | 0.3335 | 0.387 |
| greennode-14b (prior work) | 0.6711 | 0.3672 | 29.5967 | 0.468 | 0.5281 |
| GreenMind-Medium-14B-R1 (our) | 0.8689 | 0.7796 | 10.7609 | 0.7915 | 0.7124 |
Table 4: VMLU performance compared to fine-tuned models, demonstrating GreenMind's improvements across various Vietnamese language tasks
Qualitative analysis reveals the model's ability to generate structured reasoning chains across diverse domains. For example, in mathematics problems, GreenMind correctly applies formulas and systematically works through calculations:
| Task: | Mathematics |
|---|---|
| Prompt: | Hình lập phương có cạnh là 5 m . Vậy thể tích hình đó là: A. $150 \mathrm{~m}^{3}$ B. $25 \mathrm{~m}^{3}$ C. $100 \mathrm{~m}^{3}$ D. $125 \mathrm{~m}^{3}$ |
| Answer: | Đầu tiên, chúng ta cần nhớ công thức tinh thể tích của hình lập phương: Thể tích $=$ $\mathrm{a}^{3}$ (trong đó a là độ dài cạnh của hình lập phương) Trong trường hợp này, cạnh của hình lập phương là 5 m . Tiếp theo, áp dụng công thức vào dữ liệu cho sẵn: $\mathrm{V}=5^{3}=5 \times 5 \times 5=125 \mathrm{~m}^{3}$ Cuối cùng, so sánh kết quả với các lựa chọn được cung cấp: - A. $150 \mathrm{~m}^{3}$ - B. $25 \mathrm{~m}^{3}$ - C. $100 \mathrm{~m}^{3}$ - D. $125 \mathrm{~m}^{3}$ Kết quả đúng nhất chính là $125 \mathrm{~m}^{3} .$ D |
| Task: | Natural Science |
| Prompt: | Các cơ quan sinh dục cái và cơ quan sinh dục đực của thực vật có hoa là: A. Đài hoa và nhụy hoa. B. Cánh hoa và bao phần. C. Nhụy và nhị. D. Cả 3 ý trên. |
| Answer: | Đầu tiên, chúng ta cần xác định: - Cơ quan sinh dục cái (nữ) ở thực vật có hoa là gì? - Cơ quan sinh dục đực (nam) ở thực vật có hoa là gì? 1. Cơ quan sinh dục cái thường gồm phần noãn hay kén noãn nằm bên dưới. 2. Cơ quan sinh dục đực thường gồm nhị hoa sản xuất tinh trùng dạng phần hoa. Tiếp theo, phân tích mỗi phương án: A - Đài hoa và nhụy hoa không chính xác vì đây chỉ là bộ phận bảo vệ hoặc phụ trợ. B - Cánh hoa và bao phần cũng tương tự như trên. C - Nhụy và nhị đúng với mô tả phía trên. D - Tất cả ba đều sai khi xét đến vị trí cụ thể của cơ quan sinh dục. Vậy rõ ràng nhất từ góc nhìn cấu trúc chức năng thì C sẽ phù hợp. swer>C |
| Task: | Social Science |
| Prompt: | Chống bảo ở nước ta phải luôn kết hợp với chồng A. hạn hán. B. động đất. C. ngập lụt. D. sương muối. |
| Answer: | Đầu tiên, chúng cần xác định vấn đề chính của câu hỏi: "chống bảo". Tiếp theo, phân tích mỗi phương án: - Phương án A: Hạn hán - Đây không liên quan trực tiếp đến hậu quả thường gặp khi có bão. - Phương án B: Động đất - Cũng không liên quan nhiều tới tình hình thời tiết do bảo gây nên. - Phương án C: Ngập lụt - Khi xảy ra bão, mưa lớn dần đến nguy cơ ngập lụt rất cao. - Phương án D: Sương muối - Thường xuất hiện vào mùa khô hoặc trên vùng biển nhất định, ít liên quan đến bão. Từ đó, rõ ràng phương án phù hợp nhất sẽ là sự kết hợp giữa chồng bão và chồng ngập lụt vì hai yếu tố này đi cùng nhau trong thực tế. C |
Table 5: Qualitative results showing GreenMind's step-by-step reasoning on mathematics, natural science, and social science questions
This approach to reasoning allows the model to break down complex problems into manageable steps, similar to how research has shown chain-of-thought enhances vision-language model reasoning. The technique has also been explored in 3D reasoning tasks as demonstrated in research integrating chain-of-thought with multimodal alignment.
Looking Forward: Impact and Future Directions
GreenMind-Medium-14B-R1 represents a significant advancement in Vietnamese language modeling, particularly for tasks requiring complex reasoning. By combining the efficiency of Group Relative Policy Optimization with specialized reward functions for Vietnamese language consistency and factual accuracy, the model achieves performance that surpasses many larger models on Vietnamese benchmarks.
The model's ability to generate clear, structured reasoning steps makes it valuable for educational applications, where explaining the process is as important as providing the correct answer. This capability could transform how Vietnamese-speaking students learn complex subjects by providing step-by-step walkthroughs of problem-solving processes.
Beyond education, GreenMind's reasoning capabilities make it well-suited for:
- Customer service applications requiring complex problem resolution
- Legal and financial advisory services needing transparent decision processes
- Content creation that requires logical structuring and factual accuracy
The techniques developed for GreenMind could be extended to other low-resource languages that face similar challenges with language mixing and reasoning quality. The combination of specialized reward functions and efficient training methodologies offers a blueprint for building high-quality reasoning models without the computational resources required for the largest models.