![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)












































































































































































































































-Mafia-The-Old-Country---The-Initiation-Trailer-00-00-54.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-Nintendo-Switch-2---Reveal-Trailer-00-01-52.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![Instacart’s new Fizz alcohol delivery app is aimed at Gen Z [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/Instacarts-new-Fizz-alcohol-delivery-app-is-aimed-at-Gen-Z.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




















![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)





















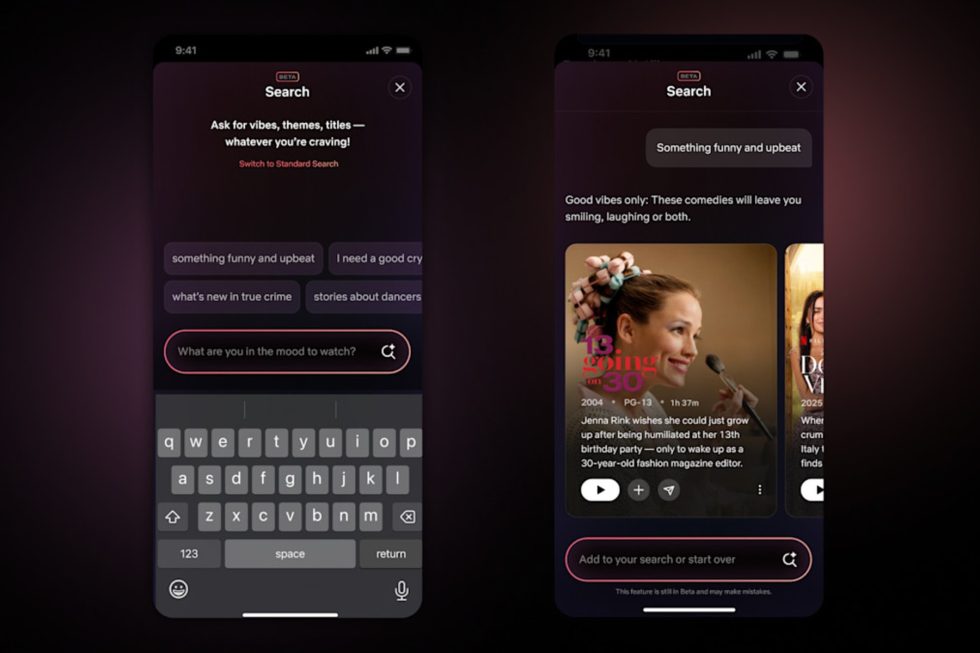



































































Migrating From DVC to KitOps
If you're using DVC for ML version control, you're familiar with tracking datasets and models in a Git-like system. However, when your projects grow in complexity with more experiments and larger artifacts, versioning alone becomes a bottleneck for production deployment. ML workflows encounter several technical challenges beyond basic version control: reproducible environments, dependency management, consistent deployment across environments, and integration with CI/CD pipelines. KitOps addresses these challenges by implementing OCI-compliant containers that encapsulate your entire ML project. This guide provides a technical walkthrough for migrating from DVC to KitOps using a straightforward implementation process. The focus is on practical integration rather than theoretical benefits. Understanding Versioning vs. Packaging in ML ML workflows involve two distinct technical challenges - versioning and packaging. These concepts serve different purposes in the development lifecycle. Versioning tracks the evolution of artifacts through development: Tracks state changes in datasets, models, and configurations Enables rollback to previous iterations Facilitates experimental branching DVC implements this by extending Git for large binary files Packaging addresses deployment and distribution: Bundles code, models, dependencies, and configuration Creates self-contained deployment units Ensures environment consistency Facilitates CI/CD integration The key technical difference is scope: versioning focuses on artifacts in isolation, while packaging focuses on system coherence. ML projects face unique packaging challenges due to artifact size, environmental dependencies, and the mix of data/code required for inference. Technical Similarities Both implement content-addressable storage for efficient handling of large files Both track metadata for artifacts including provenance and dependencies Both solve reproducibility challenges by capturing state Both extend or complement Git workflows Technical Comparison: DVC vs KitOps DVC and KitOps address overlapping problems with fundamentally different technical approaches: DVC is primarily a Git extension for ML assets. It: Implements pointer files in Git while storing large binaries separately Integrates directly into existing Git repositories Uses content-addressable storage to track large files efficiently Defines DAG-based pipelines with YAML configuration Functions primarily for development-time versioning KitOps follows a container-based approach. It: Implements OCI-compatible containers for ML artifacts Works independently from source control systems Uses manifests (kitfile) to define artifact relationships Creates self-contained units that include runtime dependencies Integrates natively with container orchestration platforms Technical Feature Comparison Feature KitOps DVC Storage mechanism OCI registry with content-addressable storage Content-addressable storage with remote caching Configuration YAML-based kitfile describing entire project .dvc files per artifact + optional dvc.yaml Dependency management Container-based with manifest-defined requirements Git-based with optional pipeline dependencies Runtime environment Self-contained with packaged dependencies Relies on external environment configuration Distribution mechanism Registry-based pulling/pushing of versioned artifacts Git+remote storage with explicit push/pull operations CI/CD integration Native container registry integration Requires custom scripts for CI/CD integration Local development Container-based consistent environment Local environment that may differ between developers Implementation complexity Higher initial setup, simpler deployment Lower initial setup, more complex deployment The primary architectural difference is that DVC extends Git's versioning model for ML, while KitOps implements container-based infrastructure common in production environments. This design difference makes KitOps more suited for deployment scenarios with existing container infrastructure. Technical Limitations of DVC in Production Workflows DVC excels during model development but encounters limitations when moving to production: Environment inconsistency: DVC doesn't package runtime environments, leading to "works on my machine" problems when deploying models across different infrastructure. Pipeline fragmentation: Bridging from DVC pipelines to production orchestration requires custom scripts and integration logic. Collaboration overhead: Cross-functional teams experience friction when data scientists must coordinate complex Git operations with engineers. Deployment complexity: Production deployment requires extracting artifacts from DVC, rebuilding environment dependencies, and managing configuration separately. CI/CD integration gaps: Git-centric workflow doesn't map cleanly to container-based CI/CD systems.

If you're using DVC for ML version control, you're familiar with tracking datasets and models in a Git-like system. However, when your projects grow in complexity with more experiments and larger artifacts, versioning alone becomes a bottleneck for production deployment.
ML workflows encounter several technical challenges beyond basic version control: reproducible environments, dependency management, consistent deployment across environments, and integration with CI/CD pipelines. KitOps addresses these challenges by implementing OCI-compliant containers that encapsulate your entire ML project.
This guide provides a technical walkthrough for migrating from DVC to KitOps using a straightforward implementation process. The focus is on practical integration rather than theoretical benefits.
Understanding Versioning vs. Packaging in ML
ML workflows involve two distinct technical challenges - versioning and packaging. These concepts serve different purposes in the development lifecycle.
Versioning tracks the evolution of artifacts through development:
- Tracks state changes in datasets, models, and configurations
- Enables rollback to previous iterations
- Facilitates experimental branching
- DVC implements this by extending Git for large binary files
Packaging addresses deployment and distribution:
- Bundles code, models, dependencies, and configuration
- Creates self-contained deployment units
- Ensures environment consistency
- Facilitates CI/CD integration
The key technical difference is scope: versioning focuses on artifacts in isolation, while packaging focuses on system coherence. ML projects face unique packaging challenges due to artifact size, environmental dependencies, and the mix of data/code required for inference.
Technical Similarities
- Both implement content-addressable storage for efficient handling of large files
- Both track metadata for artifacts including provenance and dependencies
- Both solve reproducibility challenges by capturing state
- Both extend or complement Git workflows
Technical Comparison: DVC vs KitOps
DVC and KitOps address overlapping problems with fundamentally different technical approaches:
DVC is primarily a Git extension for ML assets. It:
- Implements pointer files in Git while storing large binaries separately
- Integrates directly into existing Git repositories
- Uses content-addressable storage to track large files efficiently
- Defines DAG-based pipelines with YAML configuration
- Functions primarily for development-time versioning
KitOps follows a container-based approach. It:
- Implements OCI-compatible containers for ML artifacts
- Works independently from source control systems
- Uses manifests (
kitfile) to define artifact relationships - Creates self-contained units that include runtime dependencies
- Integrates natively with container orchestration platforms
Technical Feature Comparison
| Feature | KitOps | DVC |
|---|---|---|
| Storage mechanism | OCI registry with content-addressable storage | Content-addressable storage with remote caching |
| Configuration | YAML-based kitfile describing entire project |
.dvc files per artifact + optional dvc.yaml
|
| Dependency management | Container-based with manifest-defined requirements | Git-based with optional pipeline dependencies |
| Runtime environment | Self-contained with packaged dependencies | Relies on external environment configuration |
| Distribution mechanism | Registry-based pulling/pushing of versioned artifacts | Git+remote storage with explicit push/pull operations |
| CI/CD integration | Native container registry integration | Requires custom scripts for CI/CD integration |
| Local development | Container-based consistent environment | Local environment that may differ between developers |
| Implementation complexity | Higher initial setup, simpler deployment | Lower initial setup, more complex deployment |
The primary architectural difference is that DVC extends Git's versioning model for ML, while KitOps implements container-based infrastructure common in production environments. This design difference makes KitOps more suited for deployment scenarios with existing container infrastructure.
Technical Limitations of DVC in Production Workflows
DVC excels during model development but encounters limitations when moving to production:
Environment inconsistency: DVC doesn't package runtime environments, leading to "works on my machine" problems when deploying models across different infrastructure.
Pipeline fragmentation: Bridging from DVC pipelines to production orchestration requires custom scripts and integration logic.
Collaboration overhead: Cross-functional teams experience friction when data scientists must coordinate complex Git operations with engineers.
Deployment complexity: Production deployment requires extracting artifacts from DVC, rebuilding environment dependencies, and managing configuration separately.
CI/CD integration gaps: Git-centric workflow doesn't map cleanly to container-based CI/CD systems.
KitOps addresses these issues by implementing containerization patterns standard in production software. It creates self-contained artifacts that:
- Package code, models, and dependencies in OCI-compatible containers
- Support registry-based distribution with semantic versioning
- Integrate natively with container orchestration platforms
- Provide immutable, reproducible environments across development and production
- Implement content-addressable storage that only changes when artifacts change
The kitfile manifest provides a declarative approach to defining your ML project structure, similar to how Dockerfiles define application containers. This approach maintains versioning capabilities while adding deployment-ready packaging.
Technical Implementation: DVC to KitOps Migration
This migration consists of two main phases: preparing your current DVC project and implementing KitOps containerization. The process preserves your version history while adding deployment capabilities.
Prerequisites
- Git (version 2.25+)
- DVC (version 2.0+)
- KitOps CLI (
kit, version 0.5+) - Container registry access (we'll use Jozu ML, but any OCI-compatible registry works)
The approach involves:
- Setting up basic DVC version control for your ML artifacts
- Creating a KitOps manifest and containerizing the project
Phase 1: Project Setup with DVC
This section establishes baseline version control with DVC. If you already have a DVC-tracked project, you can skip to Phase 2.
1 - Install DVC via pip:
pip install dvc
2 - Verify installation:
dvc --version

3 - Initialize Git repository:
git init
4 - Initialize DVC in the repository:
dvc init

5 - Commit DVC initialization:
git commit -m "Initialize DVC"

6 - Create sample PyTorch model:
import os
import torch
import torch.nn as nn
os.makedirs("models", exist_ok=True)
# Simple linear model implementation
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(10, 1)
def forward(self, x):
return self.linear(x)
# Save model artifacts
model = SimpleModel()
torch.save(model.state_dict(), "models/model.pth")
print("Model saved successfully in 'models/model.pth'!")
7 - Train and save model:
python train_model.py

8 - Track model with DVC:
dvc add models/model.pth

9 - Configure DVC remote storage:
# Local storage example
dvc remote add myremote /path/to/storage
# Or for cloud storage:
# dvc remote add s3remote s3://bucket/path
10 - Push artifacts to remote:
dvc push

9 - Head over to Jozu Hub to see your model:


Once done, the directory tree of your file, if you run ls, should look like the output below. This directory structure shows:
- Our root files, which hold our .dvcignore (files and directories that DVC should ignore), Kitfile, and train_model.py (our Python script).
- .dvc, which holds our cache, temp files, and configurations.
- The models folder contains a tracked model file (
model.pth), with.dvcensuring version control and reproducibility.

What's Next?
So what's next? Well, that depends entirely on you. You can deploy this ML project with Argo CD, through a Jenkins pipeline, build scalable MLOps pipelines with Dagger.io and KitOps, or much more. The possibilities really are endless!
Start versioning and packaging with KitOps today! If you run into any issues, reach out to us on our official Discord.