























































































































































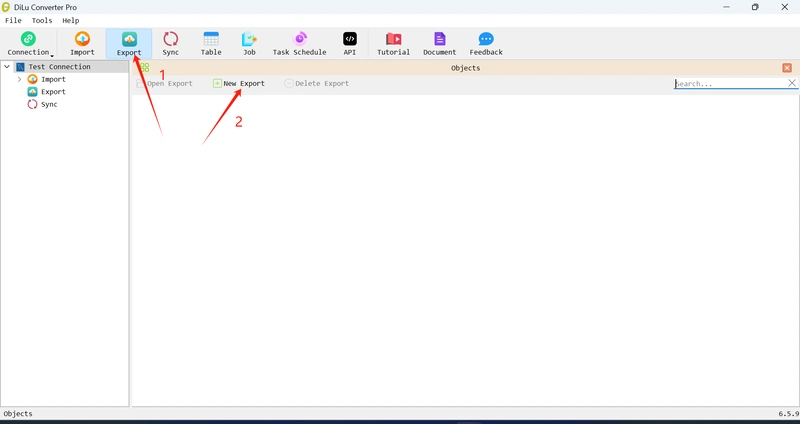
![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)











































































































































































































































.jpg?#)































_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![Craft adds Readwise integration for working with book notes and highlights [50% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/craft3.jpg.png?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)































































































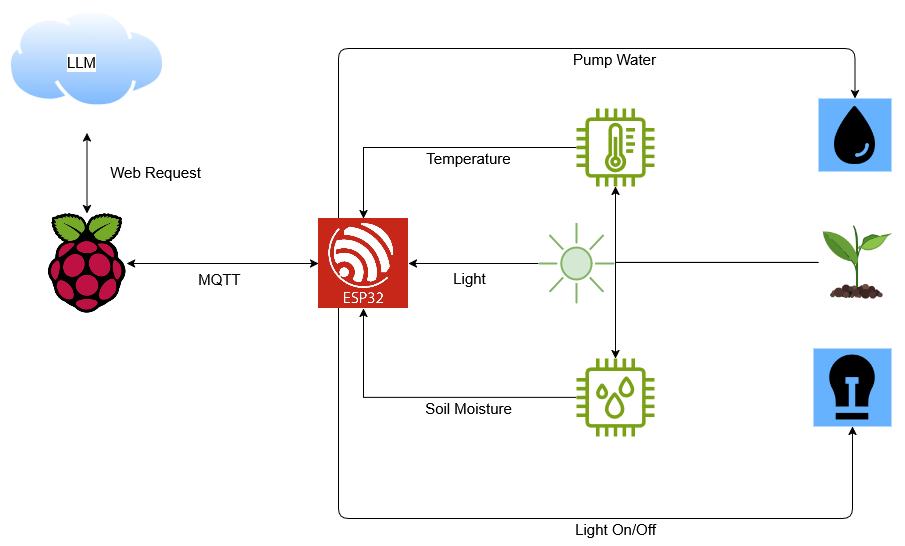
InsightFlow Part 2: Setting Up the Cloud Infrastructure with Terraform
In this post, I’ll walk you through how I set up the cloud infrastructure for my project, InsightFlow, using Terraform. InsightFlow is a data engineering project that integrates retail and fuel price data from Malaysia, processes it with dbt, and enables analysis via AWS Athena. The infrastructure is fully managed using Terraform, ensuring reproducibility and scalability. Why Terraform? Terraform is an open-source Infrastructure as Code (IaC) tool that allows you to define and provision cloud resources in a declarative way. For InsightFlow, Terraform was the perfect choice because: Reproducibility: The same infrastructure can be deployed across development and production environments. Version Control: Infrastructure changes are tracked in Git, ensuring a clear history of modifications. Scalability: Terraform supports AWS services like S3, Glue, Athena, and Batch, which are core to InsightFlow. Project Overview InsightFlow’s infrastructure is divided into two main layers: Storage Layer: Manages S3 buckets for raw and processed data. Compute Layer: Manages AWS Batch for ingestion, Glue for ETL, and Kestra for workflow orchestration. Each layer is defined in separate Terraform modules for better organization and reusability. Step 1: Setting Up the Storage Layer The storage layer consists of two S3 buckets: Raw Data Bucket: Stores unprocessed data ingested from external sources. Processed Data Bucket: Stores cleaned and transformed data ready for analysis. Terraform Configuration for Storage Here’s how the storage layer is defined in Terraform: # Raw Data Bucket resource "aws_s3_bucket" "raw_data" { bucket = "${var.project_name}-prod-raw-data" tags = local.common_tags } # Processed Data Bucket resource "aws_s3_bucket" "processed_data" { bucket = "${var.project_name}-prod-processed-data" tags = local.common_tags } # Enable versioning for both buckets resource "aws_s3_bucket_versioning" "raw_data_versioning" { bucket = aws_s3_bucket.raw_data.id versioning_configuration { status = "Enabled" } } resource "aws_s3_bucket_versioning" "processed_data_versioning" { bucket = aws_s3_bucket.processed_data.id versioning_configuration { status = "Enabled" } } Key Features Versioning: Ensures data integrity by keeping track of changes. Access Control: Public access is blocked for both buckets to ensure security. Step 2: Setting Up the Compute Layer The compute layer handles data ingestion, transformation, and orchestration. It includes: AWS Batch: Runs ingestion jobs to fetch and upload data to the raw data bucket. AWS Glue: Scans the raw data bucket and creates schema definitions in the Glue Data Catalog. Kestra: Orchestrates the entire workflow, including ingestion, transformation, and testing. Terraform Configuration for AWS Batch Here’s how the AWS Batch job definition is configured: resource "aws_batch_job_definition" "ingestion_job_def" { name = "${var.project_name}-prod-ingestion-job-def" type = "container" container_properties = jsonencode({ image = "864899839546.dkr.ecr.ap-southeast-2.amazonaws.com/insightflow-ingestion:latest" command = ["python", "main.py"] environment = [ { name = "TARGET_BUCKET" value = "insightflow-prod-raw-data" }, { name = "AWS_REGION" value = var.aws_region } ] resourceRequirements = [ { type = "VCPU", value = "1" }, { type = "MEMORY", value = "2048" } ] }) } Key Features Containerized Jobs: The ingestion script runs in a Docker container, ensuring consistency across environments. Dynamic Resource Allocation: Batch jobs can scale based on the workload. Step 3: Orchestrating Workflows with Kestra Kestra is used to orchestrate the entire pipeline. It submits AWS Batch jobs, triggers Glue crawlers, and runs dbt commands for data transformation. Example Kestra Workflow Here’s a snippet of the Kestra workflow for submitting an AWS Batch job: - id: submit_batch_ingestion_job_cli type: io.kestra.core.tasks.scripts.Bash commands: - | JOB_DEF_NAME="insightflow-prod-ingestion-job-def" JOB_QUEUE_NAME="insightflow-prod-job-queue" TARGET_BUCKET_NAME="insightflow-prod-raw-data" AWS_REGION="ap-southeast-2" aws batch submit-job \\ --region "$AWS_REGION" \\ --job-name "ingestion-job-{{execution.id}}" \\ --job-queue "$JOB_QUEUE_NAME" \\ --job-definition "$JOB_DEF_NAME" \\ --container-overrides '{ "environment": [ {"name": "TARGET_BUCKET", "value": "'"$TARGET_BUCKET_NAME"'"} ] }' Step 4: Managing Infrastructure State Terraform uses an S3 bucket as the backend to store the state file. This ensures that the state is shared and consistent across team membe

In this post, I’ll walk you through how I set up the cloud infrastructure for my project, InsightFlow, using Terraform. InsightFlow is a data engineering project that integrates retail and fuel price data from Malaysia, processes it with dbt, and enables analysis via AWS Athena. The infrastructure is fully managed using Terraform, ensuring reproducibility and scalability.
Why Terraform?
Terraform is an open-source Infrastructure as Code (IaC) tool that allows you to define and provision cloud resources in a declarative way. For InsightFlow, Terraform was the perfect choice because:
- Reproducibility: The same infrastructure can be deployed across development and production environments.
- Version Control: Infrastructure changes are tracked in Git, ensuring a clear history of modifications.
- Scalability: Terraform supports AWS services like S3, Glue, Athena, and Batch, which are core to InsightFlow.
Project Overview
InsightFlow’s infrastructure is divided into two main layers:
- Storage Layer: Manages S3 buckets for raw and processed data.
- Compute Layer: Manages AWS Batch for ingestion, Glue for ETL, and Kestra for workflow orchestration.
Each layer is defined in separate Terraform modules for better organization and reusability.
Step 1: Setting Up the Storage Layer
The storage layer consists of two S3 buckets:
- Raw Data Bucket: Stores unprocessed data ingested from external sources.
- Processed Data Bucket: Stores cleaned and transformed data ready for analysis.
Terraform Configuration for Storage
Here’s how the storage layer is defined in Terraform:
# Raw Data Bucket
resource "aws_s3_bucket" "raw_data" {
bucket = "${var.project_name}-prod-raw-data"
tags = local.common_tags
}
# Processed Data Bucket
resource "aws_s3_bucket" "processed_data" {
bucket = "${var.project_name}-prod-processed-data"
tags = local.common_tags
}
# Enable versioning for both buckets
resource "aws_s3_bucket_versioning" "raw_data_versioning" {
bucket = aws_s3_bucket.raw_data.id
versioning_configuration {
status = "Enabled"
}
}
resource "aws_s3_bucket_versioning" "processed_data_versioning" {
bucket = aws_s3_bucket.processed_data.id
versioning_configuration {
status = "Enabled"
}
}
Key Features
- Versioning: Ensures data integrity by keeping track of changes.
- Access Control: Public access is blocked for both buckets to ensure security.
Step 2: Setting Up the Compute Layer
The compute layer handles data ingestion, transformation, and orchestration. It includes:
- AWS Batch: Runs ingestion jobs to fetch and upload data to the raw data bucket.
- AWS Glue: Scans the raw data bucket and creates schema definitions in the Glue Data Catalog.
- Kestra: Orchestrates the entire workflow, including ingestion, transformation, and testing.
Terraform Configuration for AWS Batch
Here’s how the AWS Batch job definition is configured:
resource "aws_batch_job_definition" "ingestion_job_def" {
name = "${var.project_name}-prod-ingestion-job-def"
type = "container"
container_properties = jsonencode({
image = "864899839546.dkr.ecr.ap-southeast-2.amazonaws.com/insightflow-ingestion:latest"
command = ["python", "main.py"]
environment = [
{
name = "TARGET_BUCKET"
value = "insightflow-prod-raw-data"
},
{
name = "AWS_REGION"
value = var.aws_region
}
]
resourceRequirements = [
{ type = "VCPU", value = "1" },
{ type = "MEMORY", value = "2048" }
]
})
}
Key Features
- Containerized Jobs: The ingestion script runs in a Docker container, ensuring consistency across environments.
- Dynamic Resource Allocation: Batch jobs can scale based on the workload.
Step 3: Orchestrating Workflows with Kestra
Kestra is used to orchestrate the entire pipeline. It submits AWS Batch jobs, triggers Glue crawlers, and runs dbt commands for data transformation.
Example Kestra Workflow
Here’s a snippet of the Kestra workflow for submitting an AWS Batch job:
- id: submit_batch_ingestion_job_cli
type: io.kestra.core.tasks.scripts.Bash
commands:
- |
JOB_DEF_NAME="insightflow-prod-ingestion-job-def"
JOB_QUEUE_NAME="insightflow-prod-job-queue"
TARGET_BUCKET_NAME="insightflow-prod-raw-data"
AWS_REGION="ap-southeast-2"
aws batch submit-job \\
--region "$AWS_REGION" \\
--job-name "ingestion-job-{{execution.id}}" \\
--job-queue "$JOB_QUEUE_NAME" \\
--job-definition "$JOB_DEF_NAME" \\
--container-overrides '{
"environment": [
{"name": "TARGET_BUCKET", "value": "'"$TARGET_BUCKET_NAME"'"}
]
}'
Step 4: Managing Infrastructure State
Terraform uses an S3 bucket as the backend to store the state file. This ensures that the state is shared and consistent across team members.
Backend Configuration
terraform {
backend "s3" {
bucket = "insightflow-terraform-state-bucket"
key = "env:/prod/prod/compute.tfstate"
region = "ap-southeast-2"
dynamodb_table = "terraform-state-lock-dynamo"
encrypt = true
}
}
Step 5: Validating and Deploying
Before deploying the infrastructure, it’s important to validate the configuration and generate a plan.
Commands
-
Validate Configuration:
terraform validate -
Generate a Plan:
terraform plan -var-file=prod.tfvars -
Apply the Changes:
terraform apply -var-file=prod.tfvars
Conclusion
By using Terraform, I was able to set up a robust and scalable cloud infrastructure for InsightFlow. The modular approach ensures that the infrastructure is easy to manage and extend as the project grows. Whether you’re building a data pipeline or deploying a web application, Terraform is a powerful tool to have in your arsenal.