









































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)












































































































































































































































-Mafia-The-Old-Country---The-Initiation-Trailer-00-00-54.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-Nintendo-Switch-2---Reveal-Trailer-00-01-52.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![Instacart’s new Fizz alcohol delivery app is aimed at Gen Z [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/Instacarts-new-Fizz-alcohol-delivery-app-is-aimed-at-Gen-Z.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




















![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)





















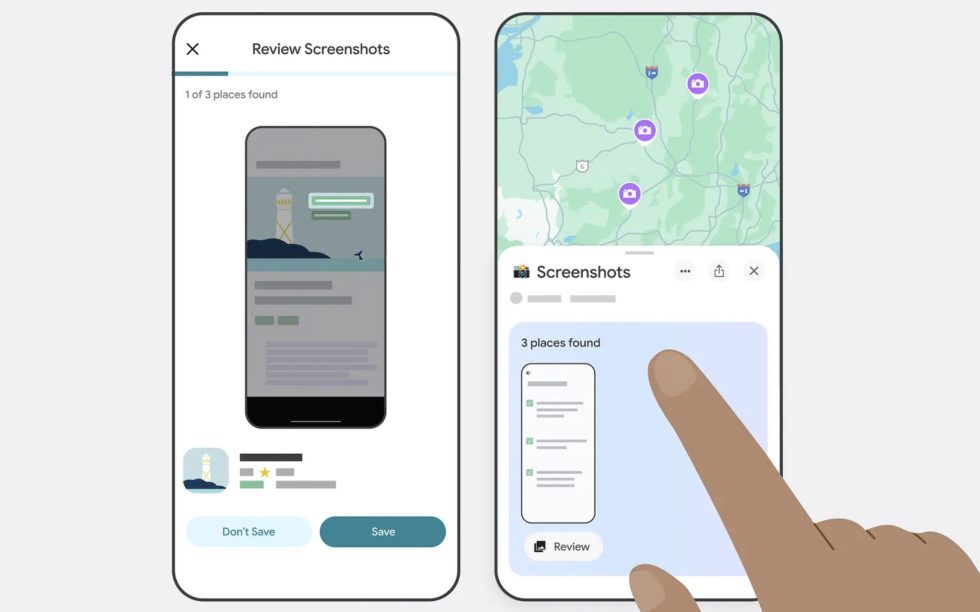



































































How is hallucination avoided in LLMs?
Hallucination in large language models (LLMs) refers to the generation of factually incorrect or misleading information that appears plausible. It’s a significant concern in applications like customer support, healthcare, legal advice, and education, where accuracy is crucial. Avoiding hallucinations involves a combination of model training techniques, architectural improvements, and external tools. One key method is reinforcement learning from human feedback (RLHF), where models are fine-tuned using human-evaluated responses to favor accurate and contextually appropriate outputs. This helps align the model’s responses with human expectations and reduces the tendency to fabricate information. Another strategy is retrieval-augmented generation (RAG). Instead of relying solely on the model’s internal parameters, RAG integrates external data sources like search engines or private knowledge bases. During a query, the model retrieves relevant documents and uses them to ground its responses in real-world information. Prompt engineering also plays a role. By carefully structuring prompts to specify the desired behavior (e.g., “Answer only if you are certain”), developers can reduce the risk of hallucination. Additionally, model transparency and output attribution—indicating where a statement came from—help users assess the reliability of information. Finally, continuous model evaluation and feedback loops allow developers to monitor and correct outputs, ensuring that deployed models remain accurate and trustworthy over time. Despite these efforts, complete elimination of hallucination is still an open challenge. However, by combining these techniques, developers and organizations can significantly reduce its occurrence and improve the reliability of LLM applications. To master these concepts and build trustworthy AI systems, consider enrolling in a Generative AI certification course.

Hallucination in large language models (LLMs) refers to the generation of factually incorrect or misleading information that appears plausible. It’s a significant concern in applications like customer support, healthcare, legal advice, and education, where accuracy is crucial. Avoiding hallucinations involves a combination of model training techniques, architectural improvements, and external tools.
One key method is reinforcement learning from human feedback (RLHF), where models are fine-tuned using human-evaluated responses to favor accurate and contextually appropriate outputs. This helps align the model’s responses with human expectations and reduces the tendency to fabricate information.
Another strategy is retrieval-augmented generation (RAG). Instead of relying solely on the model’s internal parameters, RAG integrates external data sources like search engines or private knowledge bases. During a query, the model retrieves relevant documents and uses them to ground its responses in real-world information.
Prompt engineering also plays a role. By carefully structuring prompts to specify the desired behavior (e.g., “Answer only if you are certain”), developers can reduce the risk of hallucination. Additionally, model transparency and output attribution—indicating where a statement came from—help users assess the reliability of information.
Finally, continuous model evaluation and feedback loops allow developers to monitor and correct outputs, ensuring that deployed models remain accurate and trustworthy over time.
Despite these efforts, complete elimination of hallucination is still an open challenge. However, by combining these techniques, developers and organizations can significantly reduce its occurrence and improve the reliability of LLM applications.
To master these concepts and build trustworthy AI systems, consider enrolling in a Generative AI certification course.


