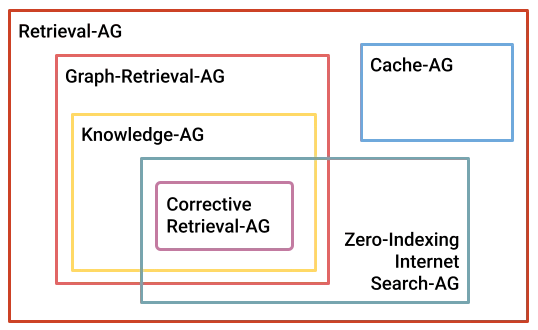








































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)








































































































(1).jpg?#)
































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)














































































































![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
![AirPods 4 On Sale for $99 [Lowest Price Ever]](https://www.iclarified.com/images/news/97206/97206/97206-640.jpg)





























![[Updated] Samsung’s 65-inch 4K Smart TV Just Crashed to $299 — That’s Cheaper Than an iPad](https://www.androidheadlines.com/wp-content/uploads/2025/05/samsung-du7200.jpg)


























































From CSV to SQL: Importing CSV Real World Data into PostgreSQL.
Like many other data projects, I found myself staring at a Kaggle dataset on student depression. However, this time equipped with a new skill, SQL, I couldn't help but wonder what insights I could obtain about the complex and sensitive topic of mental health. Out of curiosity, I set out to go from CSV to SQL in PostgreSQL. This article documents the steps I took to load the dataset into a PostgreSQL database: cleaning the data, designing a table schema, and loading the data using PostgreSQL's built-in tools. Inspecting and Cleaning the dataset The dataset seemed relatively intuitive to use. The cleaning process involved the following steps. Renaming the table and column names using lowercase snakecase. Removing special character "?" from the Financial Stress column. Validation of data types, e.g, ascertaining that numeric columns are numeric. Defining a PostgreSQL Schema With the dataset cleaned, I found the schema below to best represent the data in the file. CREATE TABLE student_depression ( id SERIAL PRIMARY KEY, gender TEXT, age INT, city TEXT, profession TEXT, academic_pressure NUMERIC, work_pressure NUMERIC, cgpa NUMERIC, study_satisfaction NUMERIC, job_satisfaction NUMERIC, sleep_duration TEXT, dietary_habits TEXT, degree TEXT, suicidal_thoughts BOOLEAN, work_study_hours NUMERIC, financial_stress NUMERIC, family_history BOOLEAN, depression BOOLEAN ); Importing the CSV file into PostgreSQL Depending on your tools and environment, there are several options for importing data, from using a graphical tool like pgAdmin to a direct SQL query. For my case, I was using a locally hosted PostgreSQL, and found the command line to be convenient. psql -U your_username -d student_depression -c "\COPY student_depression FROM 'path/to/student_depression_dataset.csv' DELIMITER ',' CSV HEADER;" The \copy command reads the file from your computer and sends it to the database, and is easier to use when there is no direct file access on the server. Requirement to successfully load a CSV file with psql . The table should already exist with a matching schema. Problematic columns and values should either be renamed or removed during the cleaning process. Only then can you use the \ COPY command embedded within the bash script. In the event of an error message, like mismatched columns or conflicting data types. Adjustment of the file was required. Running Sample SQL Queries With the data loaded, you can test and explore your dataset with SQL. Counting total records SELECT COUNT(*) AS total_students FROM student_depression; Grouping by gender SELECT gender, COUNT(*) AS count FROM student_depression GROUP BY gender; Average cgpa by depression status SELECT depression, AVG(cgpa) AS avg_cgpa FROM student_depression GROUP BY depression; Top five cities by number of students SELECT city, COUNT(*) AS num_students FROM student_depression GROUP BY city ORDER BY num_students DESC LIMIT 5; Conclusion and next steps This project turned out to be a rewarding venture into structuring data into a queryable SQL format. Even though I loaded the dataset into a single flat table, it was a great opportunity to explore and reinforce fundamental concepts of SQL. I now appreciate the importance of a proper schema design. However, the limitations of the singular table approach quickly became apparent. Analyzing CGPA trends across cities and other measures was difficult to perform effectively. Concepts like common Table Expressions, subqueries, correlated subqueries, and window functions are much more suitable when used with a relational setup. Moving forward, using primary and foreign keys, the dataset should be normalized and refactored into multiple linked tables to unlock more analytical power.

Like many other data projects, I found myself staring at a Kaggle dataset on student depression. However, this time equipped with a new skill, SQL, I couldn't help but wonder what insights I could obtain about the complex and sensitive topic of mental health. Out of curiosity, I set out to go from CSV to SQL in PostgreSQL.
This article documents the steps I took to load the dataset into a PostgreSQL database: cleaning the data, designing a table schema, and loading the data using PostgreSQL's built-in tools.
Inspecting and Cleaning the dataset
The dataset seemed relatively intuitive to use. The cleaning process involved the following steps.
- Renaming the table and column names using lowercase snakecase.
- Removing special character "?" from the Financial Stress column.
- Validation of data types, e.g, ascertaining that numeric columns are numeric.
Defining a PostgreSQL Schema
With the dataset cleaned, I found the schema below to best represent the data in the file.
CREATE TABLE student_depression (
id SERIAL PRIMARY KEY,
gender TEXT,
age INT,
city TEXT,
profession TEXT,
academic_pressure NUMERIC,
work_pressure NUMERIC,
cgpa NUMERIC,
study_satisfaction NUMERIC,
job_satisfaction NUMERIC,
sleep_duration TEXT,
dietary_habits TEXT,
degree TEXT,
suicidal_thoughts BOOLEAN,
work_study_hours NUMERIC,
financial_stress NUMERIC,
family_history BOOLEAN,
depression BOOLEAN
);
Importing the CSV file into PostgreSQL
Depending on your tools and environment, there are several options for importing data, from using a graphical tool like pgAdmin to a direct SQL query.
For my case, I was using a locally hosted PostgreSQL, and found the command line to be convenient.
psql -U your_username -d student_depression -c "\COPY student_depression FROM 'path/to/student_depression_dataset.csv' DELIMITER ',' CSV HEADER;"
The \copy command reads the file from your computer and sends it to the database, and is easier to use when there is no direct file access on the server.
Requirement to successfully load a CSV file with psql
.
- The table should already exist with a matching schema.
- Problematic columns and values should either be renamed or removed during the cleaning process.
- Only then can you use the \ COPY command embedded within the bash script.
- In the event of an error message, like mismatched columns or conflicting data types. Adjustment of the file was required.
Running Sample SQL Queries
With the data loaded, you can test and explore your dataset with SQL.
- Counting total records
SELECT COUNT(*) AS total_students
FROM student_depression;
- Grouping by gender
SELECT gender, COUNT(*) AS count
FROM student_depression
GROUP BY gender;
- Average cgpa by depression status
SELECT depression, AVG(cgpa) AS avg_cgpa
FROM student_depression
GROUP BY depression;
- Top five cities by number of students
SELECT city, COUNT(*) AS num_students
FROM student_depression
GROUP BY city
ORDER BY num_students DESC
LIMIT 5;
Conclusion and next steps
This project turned out to be a rewarding venture into structuring data into a queryable SQL format. Even though I loaded the dataset into a single flat table, it was a great opportunity to explore and reinforce fundamental concepts of SQL. I now appreciate the importance of a proper schema design.
However, the limitations of the singular table approach quickly became apparent. Analyzing CGPA trends across cities and other measures was difficult to perform effectively. Concepts like common Table Expressions, subqueries, correlated subqueries, and window functions are much more suitable when used with a relational setup.
Moving forward, using primary and foreign keys, the dataset should be normalized and refactored into multiple linked tables to unlock more analytical power.