












































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)













































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












































































































![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)
![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)






















































































































6 retrieval augmented generation (RAG) techniques you should know
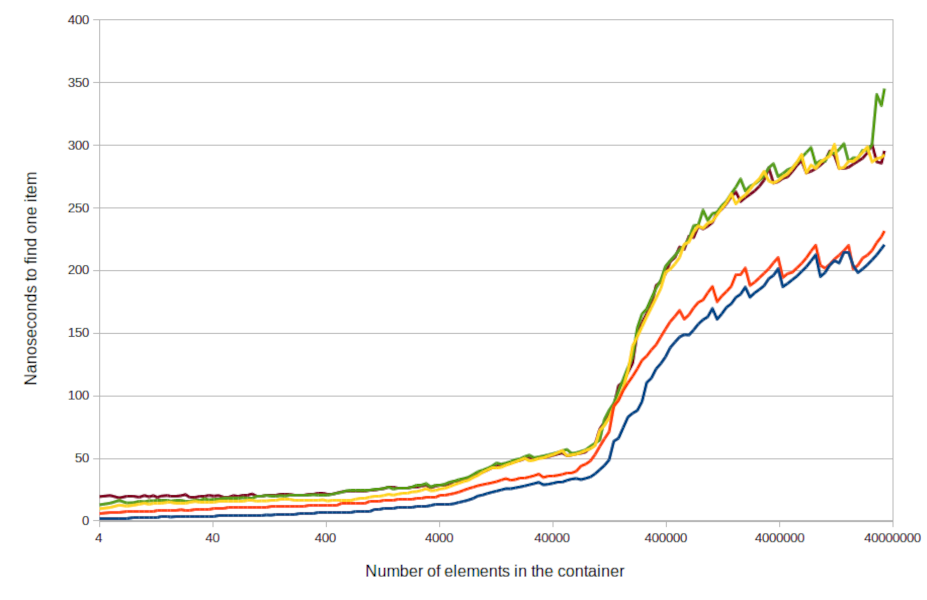
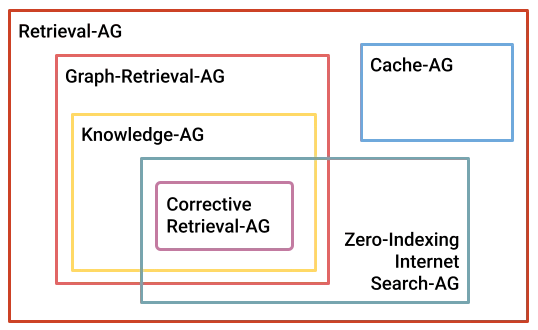
Written by Rosario De Chiara✏️ Retrieval-augmented generation (RAG) techniques enhance large language models (LLMs) by integrating external knowledge sources, improving their performance in tasks requiring up-to-date or specialized information. In this article, we will explore six RAG types: Retrieval-Augmented Generation (RAG) Graph Retrieval-Augmented Generation Knowledge-Augmented Generation (KAG) Cache-Augmented Generation (CAG) Zero-Indexing Internet Search-Augmented Generation Corrective Retrieval-Augmented Generation Remember that the list is not exhaustive because this is a hot topic in both the scientific community and among practitioners. As you’re reading this, somewhere, a researcher is working on a new, clever way of integrating new documental resources with an LLM. For frontend developers, this context is increasingly important. AI-powered features (chatbots, search assistants, etc.) are becoming more integrated into modern web apps. Understanding how RAG types function helps frontend teams collaborate more effectively with backend engineers, design better user interactions, and build smarter interfaces that take advantage of real-time, contextual data from LLMs. The six most common RAG techniques Let’s quickly define each of these six common RAG types: Retrieval-Augmented Generation (RAG) – Combines LLMs with external knowledge bases by retrieving relevant documents during inference. This method enhances the model's ability to generate accurate and contextually relevant responses Graph Retrieval-Augmented Generation – Utilizes graph-based retrieval mechanisms to enhance the generation process. Leveraging the structural relationships within knowledge graphs improves the model's ability to handle complex queries and reasoning tasks Knowledge-Augmented Generation (KAG) – Focuses on integrating structured knowledge from knowledge graphs into the generation process. This method is particularly effective in professional domains where factual accuracy and logical reasoning are crucial Cache-Augmented Generation (CAG) – Leverages long-context LLMs by preloading relevant knowledge into the model's extended context window. This approach eliminates the need for real-time retrieval, offering streamlined efficiency and faster response times Zero-Indexing Internet Search-Augmented Generation – Integrates real-time Internet search capabilities into the generation process without relying on traditional indexing mechanisms. It allows the model to access the most up-to-date information during inference, enhancing its performance in dynamic environments Corrective Retrieval-Augmented Generation – This is the most complete iteration of the RAG. Concepts from above are assembled to produce a workflow in which the classic RAG is validated against the user's query and, possibly, complemented by a web search. This is an interesting use case, especially considering the possibility of adding references (e.g., dynamic data, websites, etc) that augment the corpus of documents commonly used for RAG Each of these approaches offers unique advantages depending on the application's specific requirements, such as the need for real-time information, structured knowledge integration, or efficiency considerations. To better understand how these approaches are related, I have prepared a diagram to categorize them: Now that we have a high-level overview, let’s review each of the six RAG types a little closer. Retrieval-Augmented Generation (RAG) RAG is an umbrella expression that defines the process of supplementing the generation of an LLM with additional information retrieved and added to the prompt before starting the generation. The first step in setting up a RAG system is defining the additional information source: In the schema, some additional data is split into chunks, and such chunks are added or indexed in a database. Chunking splits the additional data into smaller pieces with the intent of cleverly adding them in a prompt to expand the knowledge of the LLM right before the generation. A common use case is, for example, a company that sells mechanical components and deploys a chatbot to assist its customers. The chunking phase will extract chunks from the technical datasheets for each element, and these chunks will be added to the database. How the database is structured is a complex topic. Typically, specific database engines that are especially aware of the kind of data they will handle are used: When the user chats with the LLM, the query is sent to the database to select the chunks that are relevant to the topic and are added to the prompt to personalize the answer. Here is an example of the process: we are developing a chatbot specialized in Paris to provide tourist information; the (fictional) chunks are Chunk 1 – "The Eiffel Tower is located in Paris." Chunk 2 – "It was completed in 1889 and designed by Gustave Eiffel." Chunk 3 – "The tow
Written by Rosario De Chiara✏️
Retrieval-augmented generation (RAG) techniques enhance large language models (LLMs) by integrating external knowledge sources, improving their performance in tasks requiring up-to-date or specialized information. In this article, we will explore six RAG types:
- Retrieval-Augmented Generation (RAG)
- Graph Retrieval-Augmented Generation
- Knowledge-Augmented Generation (KAG)
- Cache-Augmented Generation (CAG)
- Zero-Indexing Internet Search-Augmented Generation
- Corrective Retrieval-Augmented Generation
Remember that the list is not exhaustive because this is a hot topic in both the scientific community and among practitioners. As you’re reading this, somewhere, a researcher is working on a new, clever way of integrating new documental resources with an LLM. For frontend developers, this context is increasingly important. AI-powered features (chatbots, search assistants, etc.) are becoming more integrated into modern web apps. Understanding how RAG types function helps frontend teams collaborate more effectively with backend engineers, design better user interactions, and build smarter interfaces that take advantage of real-time, contextual data from LLMs.
The six most common RAG techniques
Let’s quickly define each of these six common RAG types:
- Retrieval-Augmented Generation (RAG) – Combines LLMs with external knowledge bases by retrieving relevant documents during inference. This method enhances the model's ability to generate accurate and contextually relevant responses
- Graph Retrieval-Augmented Generation – Utilizes graph-based retrieval mechanisms to enhance the generation process. Leveraging the structural relationships within knowledge graphs improves the model's ability to handle complex queries and reasoning tasks
- Knowledge-Augmented Generation (KAG) – Focuses on integrating structured knowledge from knowledge graphs into the generation process. This method is particularly effective in professional domains where factual accuracy and logical reasoning are crucial
- Cache-Augmented Generation (CAG) – Leverages long-context LLMs by preloading relevant knowledge into the model's extended context window. This approach eliminates the need for real-time retrieval, offering streamlined efficiency and faster response times
- Zero-Indexing Internet Search-Augmented Generation – Integrates real-time Internet search capabilities into the generation process without relying on traditional indexing mechanisms. It allows the model to access the most up-to-date information during inference, enhancing its performance in dynamic environments
- Corrective Retrieval-Augmented Generation – This is the most complete iteration of the RAG. Concepts from above are assembled to produce a workflow in which the classic RAG is validated against the user's query and, possibly, complemented by a web search. This is an interesting use case, especially considering the possibility of adding references (e.g., dynamic data, websites, etc) that augment the corpus of documents commonly used for RAG
Each of these approaches offers unique advantages depending on the application's specific requirements, such as the need for real-time information, structured knowledge integration, or efficiency considerations. To better understand how these approaches are related, I have prepared a diagram to categorize them:
Now that we have a high-level overview, let’s review each of the six RAG types a little closer.
Retrieval-Augmented Generation (RAG)
RAG is an umbrella expression that defines the process of supplementing the generation of an LLM with additional information retrieved and added to the prompt before starting the generation. The first step in setting up a RAG system is defining the additional information source:
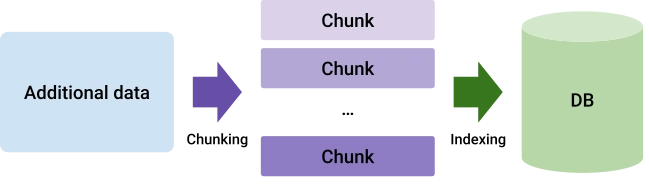
In the schema, some additional data is split into chunks, and such chunks are added or indexed in a database. Chunking splits the additional data into smaller pieces with the intent of cleverly adding them in a prompt to expand the knowledge of the LLM right before the generation.
A common use case is, for example, a company that sells mechanical components and deploys a chatbot to assist its customers. The chunking phase will extract chunks from the technical datasheets for each element, and these chunks will be added to the database. How the database is structured is a complex topic. Typically, specific database engines that are especially aware of the kind of data they will handle are used:
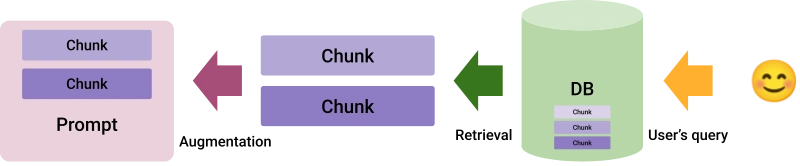
When the user chats with the LLM, the query is sent to the database to select the chunks that are relevant to the topic and are added to the prompt to personalize the answer. Here is an example of the process: we are developing a chatbot specialized in Paris to provide tourist information; the (fictional) chunks are
- Chunk 1 – "The Eiffel Tower is located in Paris."
- Chunk 2 – "It was completed in 1889 and designed by Gustave Eiffel."
- Chunk 3 – "The tower stands at a height of 330 meters."
If the user asks, "Who designed the Eiffel Tower, and when was it completed?", only Chunk 2 is selected and added to the prompt sent to the LLM. In the simplest version of RAG, the database is part of a very specific family. This vector database is optimized for storing and retrieving data in the form of vectors, which are numerical representations of information, such as text or images.
The vector database stores embeddings, which are high-dimensional vectors that, to some extent, capture the meaning of the text. When a query is made, the vector database searches for the most semantically similar vectors (representing relevant chunks of information) and retrieves them for the model to generate accurate, context-aware responses.
This allows for efficient and scalable handling of large datasets. There are two vector database possibilities for RAG: Pinecone is a vector database delivered as a PaaS, while FAISS (from Meta) is a library that can be used on-premises.
Graph Retrieval-Augmented Generation
Graph Retrieval-Augmented Generation (Graph-RAG) is an evolution of RAG. The difference is that it uses a graph database instead of a vector database for retrieval. Graph-RAG is suitable for organizing and retrieving information by leveraging relationships and connections between different chunks in a graph structure. This is particularly efficient for handling information that is naturally graph-based. For example, a collection of scientific articles on a given topic that reference each other in their bibliographies:
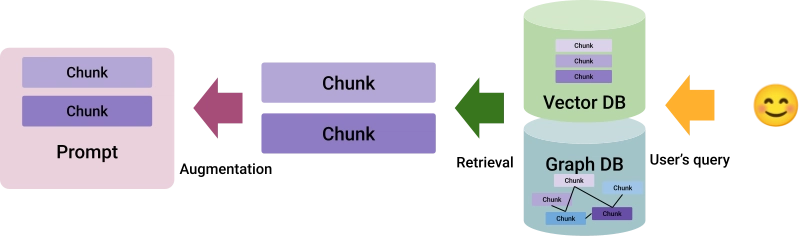
The key difference lies in the retrieval mechanism. Vector databases focus on semantic similarity by comparing numerical embeddings, while graph databases emphasize relations between entities. Two solutions for graph databases are Neptune from Amazon and Neo4j. In a case where you need a solution that can accommodate both vector and graph, Weaviate fits the bill.
Knowledge-Augmented Generation (KAG)
Knowledge-Augmented Generation (KAG) is a specific application of Graph-RAG where both the nodes (information chunks) and the edges (relationships between them) carry semantic meaning. Unlike in standard Graph-RAG, where connections may simply denote associations, in KAG, these relationships have defined semantics, such as "causes," "is a type of," or "depends on."
This adds a layer of meaning to the graph structure, enabling the system to retrieve not only relevant information but also understand how these pieces of information are logically or causally linked. Semantic edges are important because they enhance the model's ability to generate contextually rich and accurate responses. KAG can provide deeper insights and more coherent answers by considering the specific nature of the relationships between chunks.
For example, in a medical context, understanding that "symptom A causes condition B" allows the model to generate more informed responses than simply retrieving related information without understanding the nature of the connection. This makes KAG particularly valuable in complex domains where relationships between pieces of knowledge are crucial:
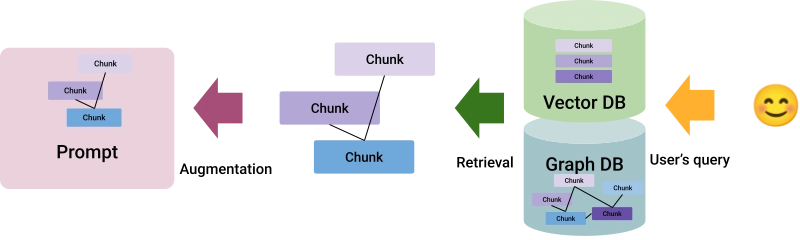
The platforms for the graph database listed above let you select chunks matching a given query and the chunks linked by specific edges. This allows you to implement a KAG architecture.
Cache-Augmented Generation (CAG)
Recent advances in long-context LLMs have extended their ability to process and reason over substantial textual inputs. By accommodating more tokens, these models can assimilate extensive information in a single prompt. This makes them well-suited for tasks like document comprehension, multi-turn dialogue, and summarization of lengthy texts. In CAG, this new possibility is leveraged by using a key-value repository that, like a cache for a microprocessor, works as a rapid access mechanism to information to be preloaded in the prompt, instead of relying on a vector or graph database like above:
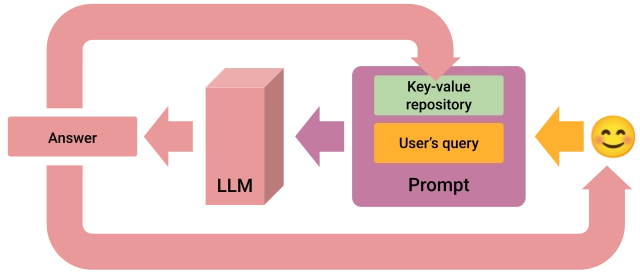
The figure shows how the key-value repository can be used efficiently throughout the interactions with the user to augment the prompt iteratively. Each answer generated by the LLM is returned to the user and added to the key-value repository within the prompt.
Remember to keep the number of tokens in the prompt below the limit for the LLM you are using. To do so, periodically clean the key-value repository of older content. It is worth noting that the CAG approach can be plugged into any of the other solutions described here to accelerate retrieval as long as the interactive session with the user evolves.
Zero-Indexing Internet Search-Augmented Generation
Zero-Indexing Internet Search-Augmented Generation aims to enhance the generation's performance by dynamically integrating the latest online information using standard search engine APIs like Google or more specialized ones.
It tries to circumvent the limitations of RAG systems that rely on a static, pre-indexed corpus. Zero-indexing refers to the absence of a pre-built index, allowing the system to access real-time data directly from the Internet:
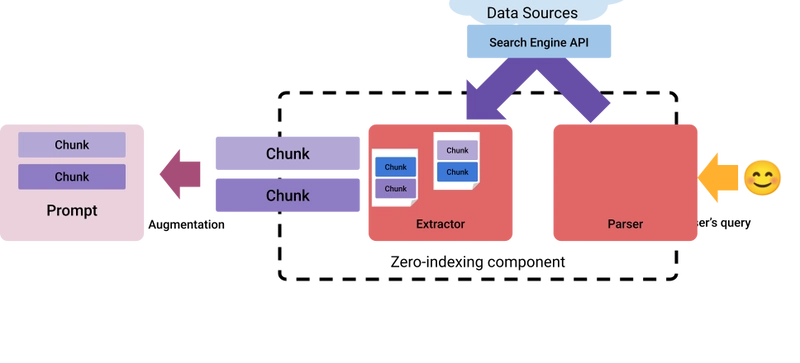
This method involves two main components:
- Parser – Determines if internet-augmented generation is needed and extracts search keywords, performs the search, and returns a series of pages
- Extractor – Accurately extracts relevant information from these pages and selects the chunk to be used to augment the prompt
A practical use case for this approach is generating responses that require up-to-date information, such as news updates, market trends, or recent scientific discoveries, ensuring the content is timely and relevant.
Corrective Retrieval-Augmented Generation
Corrective Retrieval Augmented Generation (CRAG) is a method designed to enhance the robustness of RAG. CRAG introduces an evaluator component that assesses the quality of retrieved chunks and assigns a confidence score to them before feeding them to the prompt. Based on this score, they are labeled as correct, incorrect, or ambiguous:
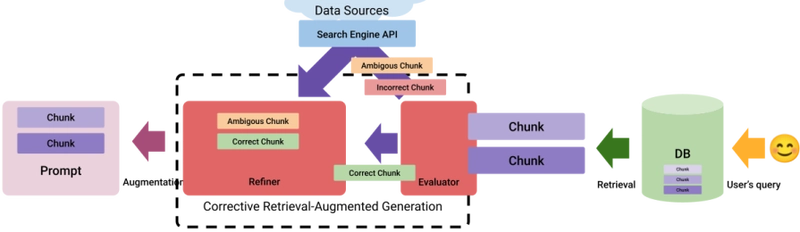
For correct retrievals, the refiner component refines the documents to extract key information. For incorrect retrievals, web searches are used to find better sources, similar to the zero-indexing approach above.
Ambiguous cases combine both approaches. This method helps ensure that the generated content is accurate and relevant, even when initial retrievals are suboptimal. CRAG can be seamlessly integrated into existing RAG frameworks to improve their performance across various tasks.
Conclusion
In the article, we discussed the basic RAG approach to augment the generation of an LLM plus five different approaches to expand the RAG functionalities. The first two, the Graph Retrieval-Augmented Generation and the Knowledge-Augmented Generation, are successive refinements to better understand the underlying structure of the information and documents used to augment the generation. To accelerate the retrieval Cache-Augmented Generation can be used in combination with other approaches.
The Zero-Indexing Internet Search-Augmented Generation approach and Corrective Retrieval-Augmented Generation approach aim at keeping the documents used for the retrieval up-to-date by extracting information from online sources and API and to increase the reliability of the generation.
The exact combination of these approaches is a matter of experience and knowledge: experience because you must know your audience and how it will interact with the LLM, and knowledge because you must grasp the inner structure of the knowledge you intend to use to augment the generation.
Get set up with LogRocket's modern error tracking in minutes:
- Visit https://logrocket.com/signup/ to get an app ID.
- Install LogRocket via NPM or script tag.
LogRocket.init()must be called client-side, not server-side.
NPM:
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
Script Tag:
Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>
3.(Optional) Install plugins for deeper integrations with your stack:
- Redux middleware
- ngrx middleware
- Vuex plugin


