









































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)












































































































































































































































-Mafia-The-Old-Country---The-Initiation-Trailer-00-00-54.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-Nintendo-Switch-2---Reveal-Trailer-00-01-52.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![Instacart’s new Fizz alcohol delivery app is aimed at Gen Z [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/Instacarts-new-Fizz-alcohol-delivery-app-is-aimed-at-Gen-Z.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




















![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)
























































































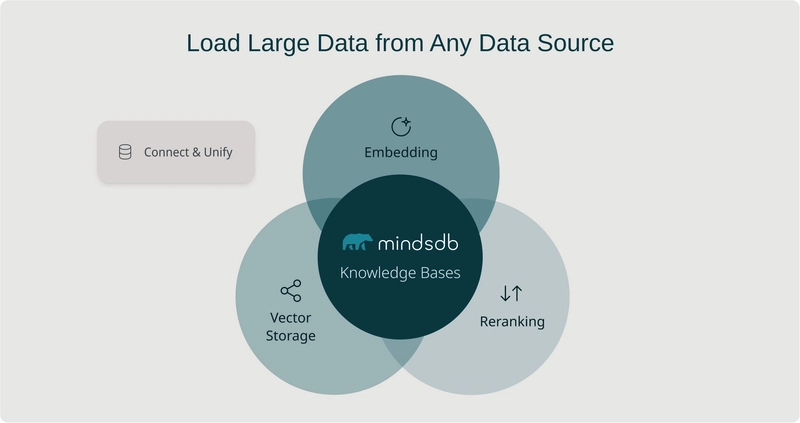
Beyond Vector Search: Why MindsDB Knowledge Bases Matter for Complete RAG Solutions
Written by Jorge Torres, Co-founder & CEO at MindsDB In our previous blog post, we introduced MindsDB Knowledge Bases as a powerful tool for RAG (Retrieval Augmented Generation) and semantic search. Today, we want to tackle an important question: "Isn't this just another vector database? Short answer: it’s even better, but why should you care?" The Limitations of Simple Vector Search Vector search has become a fundamental building block in modern AI applications. By converting text, images, or other data into numerical vectors and measuring similarities between them, we can find related content with impressive accuracy. But when building real-world RAG systems, vector search alone falls dramatically short for several critical reasons: 1. Data Pre-processing is Deceptively Complex Raw vector storage is just the tip of the iceberg. Before you can even start searching, you need to tackle: Optimal chunking strategies: Should you break text by paragraph, fixed size, semantic meaning, or hierarchically? The wrong choice can destroy search quality. Embedding model selection: Different models perform dramatically differently across domains. Index optimization: Speed versus accuracy tradeoffs that significantly impact user experience. Metadata management: Tracking content sources and maintaining proper attribution. 2. From Similarity to Relevance: The Knowledge Gap Vector similarity ≠ semantic relevance. Consider these limitations: Context sensitivity: Vector search struggles with ambiguity and contextual meaning. Temporal understanding: Inability to grasp time-dependent relationships. Multi-hop reasoning: Simple vector retrieval can't connect information across documents. Structured vs. unstructured content: Most vector stores can't seamlessly handle both. 3. The Critical Missing Piece: Reranking Standard vector search suffers from a fundamental problem: initial retrieval is often insufficient for accurate results. Here's why reranking is essential: Initial retrieval limitations: Vector search typically retrieves based on overall semantic similarity, which often misses the most relevant documents. Precision vs. recall tradeoff: Vector databases optimize for recall (finding potentially relevant items) but struggle with precision (ranking the most relevant items first). Query-document interaction: Simple vector similarity can't model the complex interaction between specific query terms and document passages. Nuanced relevance signals: Critical factors like factual accuracy, recency, and authoritativeness aren't captured in embedding space. Without reranking, RAG systems often feed irrelevant or misleading context to LLMs, resulting in hallucinations, factual errors, and poor overall quality. Effective reranking requires: Cross-encoders: Unlike bi-encoders (used in initial retrieval), cross-encoders analyze query-document pairs together to assess true relevance. Multi-stage pipelines: Efficient systems use fast initial retrieval followed by more computationally intensive reranking. Domain adaptation: Rerankers that understand your specific data and query patterns. Relevance feedback: Incorporating user behavior signals to continuously improve ranking quality. 4. The Data Integration Challenge Enterprise data lives in multiple locations and formats: Databases (SQL, NoSQL) Applications (SaaS platforms, internal tools) Document stores (PDFs, spreadsheets, presentations) Data warehouses Vector stores typically handle only the final, processed vectors - leaving you to build and maintain complex data pipelines from these disparate sources. 5. The Scale Problem As organizations accumulate data at exponential rates, simple vector solutions hit hard limitations: Massive document volumes: Indexing millions of documents demands specialized infrastructure Large document processing: Breaking down lengthy documents (50+ pages) requires intelligent chunking Real-time synchronization: Keeping knowledge bases updated with fresh data is computationally intensive Q*uery performance at scale:* Maintaining sub-second response times across terabyte-scale collections Resource optimization: Balancing memory usage, storage costs, and query performance At gigabyte to terabyte scales, with potentially millions of rows of unstructured text, the complexity becomes overwhelming for simple vector databases. Enter MindsDB Knowledge Bases: A Complete RAG Solution MindsDB Knowledge Bases were designed to solve the complete RAG challenge, not just the vector storage piece. Here's what sets them apart: 1. Batteries-Included Architecture MindsDB Knowledge Bases provide a true end-to-end solution: CREATE KNOWLEDGE_BASE my_kb -- That's it! Everything is handled automatically by default No need to worry about data embedding, chunking, vector optimization, or any other technical details unless you want to cus
Written by Jorge Torres, Co-founder & CEO at MindsDB
In our previous blog post, we introduced MindsDB Knowledge Bases as a powerful tool for RAG (Retrieval Augmented Generation) and semantic search. Today, we want to tackle an important question: "Isn't this just another vector database? Short answer: it’s even better, but why should you care?"
The Limitations of Simple Vector Search
Vector search has become a fundamental building block in modern AI applications. By converting text, images, or other data into numerical vectors and measuring similarities between them, we can find related content with impressive accuracy. But when building real-world RAG systems, vector search alone falls dramatically short for several critical reasons:
1. Data Pre-processing is Deceptively Complex
Raw vector storage is just the tip of the iceberg. Before you can even start searching, you need to tackle:
- Optimal chunking strategies: Should you break text by paragraph, fixed size, semantic meaning, or hierarchically? The wrong choice can destroy search quality.
- Embedding model selection: Different models perform dramatically differently across domains.
- Index optimization: Speed versus accuracy tradeoffs that significantly impact user experience.
- Metadata management: Tracking content sources and maintaining proper attribution.
2. From Similarity to Relevance: The Knowledge Gap
Vector similarity ≠ semantic relevance. Consider these limitations:
- Context sensitivity: Vector search struggles with ambiguity and contextual meaning.
- Temporal understanding: Inability to grasp time-dependent relationships.
- Multi-hop reasoning: Simple vector retrieval can't connect information across documents.
- Structured vs. unstructured content: Most vector stores can't seamlessly handle both.
3. The Critical Missing Piece: Reranking
Standard vector search suffers from a fundamental problem: initial retrieval is often insufficient for accurate results. Here's why reranking is essential:
- Initial retrieval limitations: Vector search typically retrieves based on overall semantic similarity, which often misses the most relevant documents.
- Precision vs. recall tradeoff: Vector databases optimize for recall (finding potentially relevant items) but struggle with precision (ranking the most relevant items first).
- Query-document interaction: Simple vector similarity can't model the complex interaction between specific query terms and document passages.
- Nuanced relevance signals: Critical factors like factual accuracy, recency, and authoritativeness aren't captured in embedding space.
Without reranking, RAG systems often feed irrelevant or misleading context to LLMs, resulting in hallucinations, factual errors, and poor overall quality. Effective reranking requires:
- Cross-encoders: Unlike bi-encoders (used in initial retrieval), cross-encoders analyze query-document pairs together to assess true relevance.
- Multi-stage pipelines: Efficient systems use fast initial retrieval followed by more computationally intensive reranking.
- Domain adaptation: Rerankers that understand your specific data and query patterns.
- Relevance feedback: Incorporating user behavior signals to continuously improve ranking quality.
4. The Data Integration Challenge

Enterprise data lives in multiple locations and formats:
- Databases (SQL, NoSQL)
- Applications (SaaS platforms, internal tools)
- Document stores (PDFs, spreadsheets, presentations)
- Data warehouses
Vector stores typically handle only the final, processed vectors - leaving you to build and maintain complex data pipelines from these disparate sources.
5. The Scale Problem
As organizations accumulate data at exponential rates, simple vector solutions hit hard limitations:
- Massive document volumes: Indexing millions of documents demands specialized infrastructure
- Large document processing: Breaking down lengthy documents (50+ pages) requires intelligent chunking
- Real-time synchronization: Keeping knowledge bases updated with fresh data is computationally intensive
- Q*uery performance at scale:* Maintaining sub-second response times across terabyte-scale collections
- Resource optimization: Balancing memory usage, storage costs, and query performance
At gigabyte to terabyte scales, with potentially millions of rows of unstructured text, the complexity becomes overwhelming for simple vector databases.
Enter MindsDB Knowledge Bases: A Complete RAG Solution
MindsDB Knowledge Bases were designed to solve the complete RAG challenge, not just the vector storage piece. Here's what sets them apart:
1. Batteries-Included Architecture
MindsDB Knowledge Bases provide a true end-to-end solution:
CREATE KNOWLEDGE_BASE my_kb
-- That's it! Everything is handled automatically by default
No need to worry about data embedding, chunking, vector optimization, or any other technical details unless you want to customize them. As our documentation states, our Knowledge Base engine figures out how to find relevant information whether your data is "structured and neater than a Swiss watch factory or unstructured and messy as a teenager's bedroom."
2. Universal Data Connectivity and Synchronization
Unlike vector databases that only handle pre-processed embeddings, MindsDB connects directly to:
- Any database MindsDB supports (PostgreSQL, MySQL, MongoDB, etc.)
- File systems (PDFs, CSVs, Excel files)
- API endpoints and applications
- Existing vector databases
This eliminates complex ETL pipelines and keeps your data fresh. Even better, MindsDB makes it simple to add and continuously synchronize data from any source:
-- Insert data from a database table
INSERT INTO my_knowledge_base (
SELECT document_id, content, category, author
FROM my_database.documents
);
-- Insert from uploaded files
INSERT INTO my_knowledge_base (
SELECT * FROM files.my_pdf_documents
);
-- Set up real-time synchronization with JOBS
CREATE JOB keep_kb_updated AS (
INSERT INTO my_knowledge_base (
SELECT id, content, metadata
FROM data_source.new_documents
WHERE id > LAST
)
) EVERY hour;
The powerful LAST keyword ensures that only new data is processed, effectively turning any data source into a streaming input for your knowledge base. This works seamlessly even with terabyte-scale datasets containing tens of millions of rows.
3. Intelligent Retrieval and Advanced Reranking

MindsDB Knowledge Bases go far beyond basic vector similarity with sophisticated retrieval and reranking:
- Hybrid search: Combining vector, keyword, and metadata filtering for initial retrieval
- Adaptive chunking: Automatically adjusting document splitting based on content
- Advanced reranking pipeline: Multi-stage result refinement that dramatically improves precision
- Cross-encoder relevance scoring: Deep neural networks that analyze query-document pairs together
- Context-aware reranking: Considering the full conversation history when prioritizing results
- Automatic relevance feedback: Learning from user interactions to improve ranking quality
4. SQL-Native Interface
While most vector databases require special APIs, MindsDB Knowledge Bases integrate seamlessly with SQL:
SELECT * FROM my_kb
WHERE content LIKE 'what are the latest sales trends in California?'
This SQL compatibility means:
- No new query languages to learn
- Integration with existing BI tools
- Compatibility with your current data stack
5. Enterprise-Grade Scalability
MindsDB Knowledge Bases are engineered to handle massive data volumes:
- Petabyte-scale federation: Connect and query across enterprise data without moving it
- Distributed processing: Efficiently handle millions of documents with intelligent partitioning
- Optimized throughput: Process thousands of documents per minute during ingestion
- Automatic resource scaling: Dynamically allocate computing resources based on workload
- Incremental updates: Only process and embed new or modified content
When dealing with extremely large documents or datasets in the terabyte range, MindsDB's architecture handles the complexity for you, maintaining performance where simple vector databases would collapse.
6. Customization Without Complexity
For those who want full control:
CREATE KNOWLEDGE_BASE advanced_kb USING
model = my_custom_embedding_model,
storage = my_preferred_vector_db,
chunking = 'semantic'
You can optimize every aspect while still benefiting from MindsDB's unified architecture.
Real-World Impact: Why It Matters
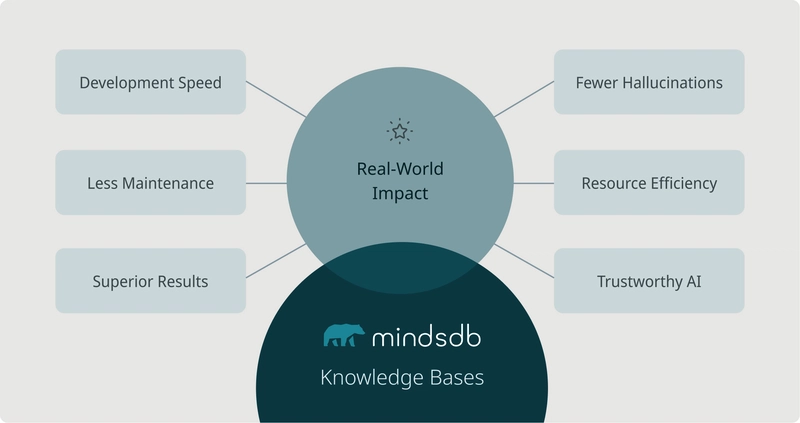
The difference becomes clear when building AI applications:
- Development speed: Deploy in hours instead of weeks
- Maintenance overhead: Drastic reduction in infrastructure complexity
- Superior result quality: More accurate, relevant responses through advanced reranking
- Dramatic reduction in hallucinations: Properly reranked context means LLMs receive only the most relevant information
- Resource efficiency: Lower computational requirements and costs
- Trustworthy AI: Proper attribution and verifiable answers
Conclusion
Vector search is a critical component, but focusing only on vector storage is like buying a steering wheel when you need a car. MindsDB Knowledge Bases provide the complete vehicle - with the engine, transmission, navigation system, and safety features all working together seamlessly.
By tackling the full spectrum of RAG challenges, MindsDB enables you to focus on building AI applications that provide real value, rather than wrestling with the underlying plumbing.
Ready to move beyond vector search? Get started with MindsDB Knowledge Bases today.


