








































































































































































![[The AI Show Episode 147]: OpenAI Abandons For-Profit Plan, AI College Cheating Epidemic, Apple Says AI Will Replace Search Engines & HubSpot’s AI-First Scorecard](https://www.marketingaiinstitute.com/hubfs/ep%20147%20cover.png)






















































































































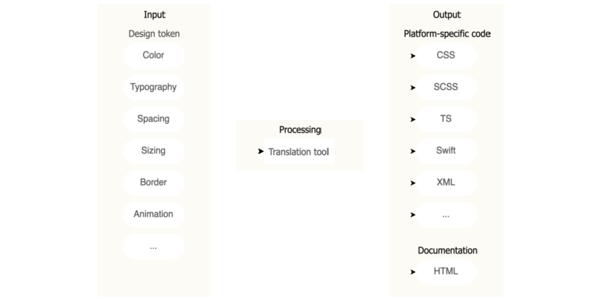























































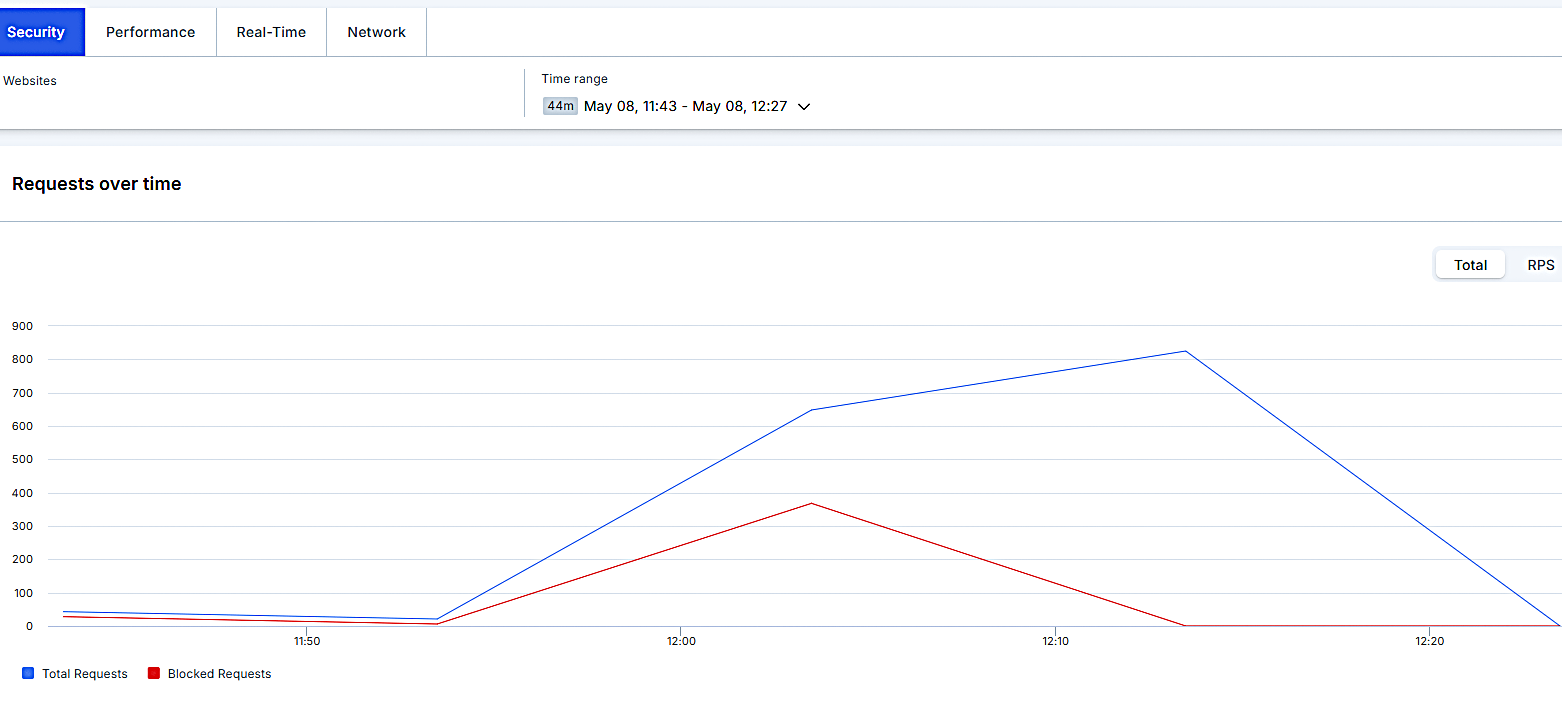
.jpeg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















































































_ElenaBs_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































































![Apple Working on Brain-Controlled iPhone With Synchron [Report]](https://www.iclarified.com/images/news/97312/97312/97312-640.jpg)
























































































Why Red Teaming Isn’t Just for Cybersecurity Anymore: The rise of AI Red Teaming
In cybersecurity, “red teaming” is a familiar concept—ethical hackers simulate real-world attacks to expose weaknesses before malicious actors do. But as AI systems become more powerful and deeply embedded in our daily lives, a new kind of red teaming has emerged. It’s called AI Red Teaming, and it’s not about breaking into networks. It’s about testing how AI systems behave, how they can be tricked, and how they might go wrong. So, What Is AI Red Teaming? AI Red Teaming is the practice of simulating attacks or misuse scenarios on AI models—especially large ones like GPT or image generators—to uncover flaws, vulnerabilities, or unintended behavior. Think of it like this: instead of testing whether a website can be hacked, you’re testing whether an AI model can be manipulated, misled, or exploited. You might try: Finding prompts that bypass content safety filters Trick the model into giving dangerous advice Uncovering biased or unfair responses Figuring out ways a model might leak private or sensitive information The goal isn’t to break AI for the sake of it. It’s to make it better—stronger, safer, and more trustworthy—by discovering its weak spots early. What Does an AI Red Teamer Actually Do? An AI Red Teamer thinks like an attacker, but acts with responsibility. Their job is to explore the edges of how AI behaves, looking for failure modes that aren’t always obvious. Some common attack types include: Prompt manipulation – crafting inputs that push the AI to misbehave Data poisoning – introducing bad or biased data into the training set Model extraction – figuring out how to copy or clone a model through repeated queries Filter evasion – creating inputs that sneak harmful content past safety guards A good red teamer doesn’t just find a problem and move on. They also give feedback—how to fix it, how to monitor for it, and how to prevent it in the future. Why Does This Matter for AI? AI systems, especially large language models, are impressive—but they’re not perfect. They can: Make up facts Reinforce stereotypes Be tricked into saying things they shouldn't Act unpredictably depending on the prompt And since these models are being used in education, healthcare, legal advice, creative work, and more, the stakes are high. We need to understand where things can go wrong before they do. Unlike traditional software, you can’t just slap on a patch. These models are built from massive datasets and complex behaviors that don’t always show up until someone pushes them to the edge. That’s exactly what red teaming is for. How Is AI Red Teaming Different From Traditional Red Teaming? While both involve thinking like an attacker, the targets and techniques are different. Traditional red teaming focuses on: Breaking into servers and networks Finding bugs or code vulnerabilities Testing physical or digital security systems AI red teaming focuses on: Testing how an AI model can be misled Finding harmful or biased behaviors Uncovering ethical and alignment issues It’s not just about security anymore. It’s about safety, trust, and responsibility. Real-World Scenarios Here are a few examples where AI red teaming makes a big difference: A chatbot gives unauthorized medical advice when prompted in a certain way A content filter fails to block hate speech hidden in emojis or typos A model returns biased results when asked about certain professions or demographics Sensitive information from training data gets exposed through clever queries These aren’t hypothetical. These are actual risks that red teams around the world are already finding—and helping fix. Why You Should Care If you’re a developer, researcher, or just someone interested in how technology affects the world, AI red teaming is worth your attention. It’s one of the most important things we can do to make sure AI is used safely and fairly. As AI gets smarter, our responsibility grows too. Red teaming helps us understand where the limits are—and how to build better systems that respect those limits. Wrapping up AI red teaming might sound technical or niche, but at its core, it’s about curiosity, ethics, and responsibility. It’s about asking hard questions and being willing to test the answers, not just trust them. If you’ve ever played with an AI model and thought, “What happens if I ask this?”—you’re already thinking like a red teamer. And that mindset might be exactly what the future of safe, responsible AI needs. If you're a software developer who enjoys exploring different technologies and techniques like this one, check out LiveAPI. It’s a super-convenient tool that lets you generate interactive API docs instantly. So, if you’re working with a codebase that lacks documentation, just use LiveAPI to generate it and save time! You can instantly try it out here!

In cybersecurity, “red teaming” is a familiar concept—ethical hackers simulate real-world attacks to expose weaknesses before malicious actors do. But as AI systems become more powerful and deeply embedded in our daily lives, a new kind of red teaming has emerged.
It’s called AI Red Teaming, and it’s not about breaking into networks. It’s about testing how AI systems behave, how they can be tricked, and how they might go wrong.
So, What Is AI Red Teaming?
AI Red Teaming is the practice of simulating attacks or misuse scenarios on AI models—especially large ones like GPT or image generators—to uncover flaws, vulnerabilities, or unintended behavior.
Think of it like this: instead of testing whether a website can be hacked, you’re testing whether an AI model can be manipulated, misled, or exploited.
You might try:
- Finding prompts that bypass content safety filters
- Trick the model into giving dangerous advice
- Uncovering biased or unfair responses
- Figuring out ways a model might leak private or sensitive information
The goal isn’t to break AI for the sake of it. It’s to make it better—stronger, safer, and more trustworthy—by discovering its weak spots early.
What Does an AI Red Teamer Actually Do?
An AI Red Teamer thinks like an attacker, but acts with responsibility. Their job is to explore the edges of how AI behaves, looking for failure modes that aren’t always obvious.
Some common attack types include:
- Prompt manipulation – crafting inputs that push the AI to misbehave
- Data poisoning – introducing bad or biased data into the training set
- Model extraction – figuring out how to copy or clone a model through repeated queries
- Filter evasion – creating inputs that sneak harmful content past safety guards
A good red teamer doesn’t just find a problem and move on. They also give feedback—how to fix it, how to monitor for it, and how to prevent it in the future.
Why Does This Matter for AI?
AI systems, especially large language models, are impressive—but they’re not perfect.
They can:
- Make up facts
- Reinforce stereotypes
- Be tricked into saying things they shouldn't
- Act unpredictably depending on the prompt
And since these models are being used in education, healthcare, legal advice, creative work, and more, the stakes are high. We need to understand where things can go wrong before they do.
Unlike traditional software, you can’t just slap on a patch. These models are built from massive datasets and complex behaviors that don’t always show up until someone pushes them to the edge.
That’s exactly what red teaming is for.
How Is AI Red Teaming Different From Traditional Red Teaming?
While both involve thinking like an attacker, the targets and techniques are different.
Traditional red teaming focuses on:
- Breaking into servers and networks
- Finding bugs or code vulnerabilities
- Testing physical or digital security systems
AI red teaming focuses on:
- Testing how an AI model can be misled
- Finding harmful or biased behaviors
- Uncovering ethical and alignment issues
It’s not just about security anymore. It’s about safety, trust, and responsibility.
Real-World Scenarios
Here are a few examples where AI red teaming makes a big difference:
- A chatbot gives unauthorized medical advice when prompted in a certain way
- A content filter fails to block hate speech hidden in emojis or typos
- A model returns biased results when asked about certain professions or demographics
- Sensitive information from training data gets exposed through clever queries
These aren’t hypothetical. These are actual risks that red teams around the world are already finding—and helping fix.
Why You Should Care
If you’re a developer, researcher, or just someone interested in how technology affects the world, AI red teaming is worth your attention.
It’s one of the most important things we can do to make sure AI is used safely and fairly.
As AI gets smarter, our responsibility grows too. Red teaming helps us understand where the limits are—and how to build better systems that respect those limits.
Wrapping up
AI red teaming might sound technical or niche, but at its core, it’s about curiosity, ethics, and responsibility. It’s about asking hard questions and being willing to test the answers, not just trust them.
If you’ve ever played with an AI model and thought, “What happens if I ask this?”—you’re already thinking like a red teamer.
And that mindset might be exactly what the future of safe, responsible AI needs.
If you're a software developer who enjoys exploring different technologies and techniques like this one, check out LiveAPI. It’s a super-convenient tool that lets you generate interactive API docs instantly.
So, if you’re working with a codebase that lacks documentation, just use LiveAPI to generate it and save time!
You can instantly try it out here!


