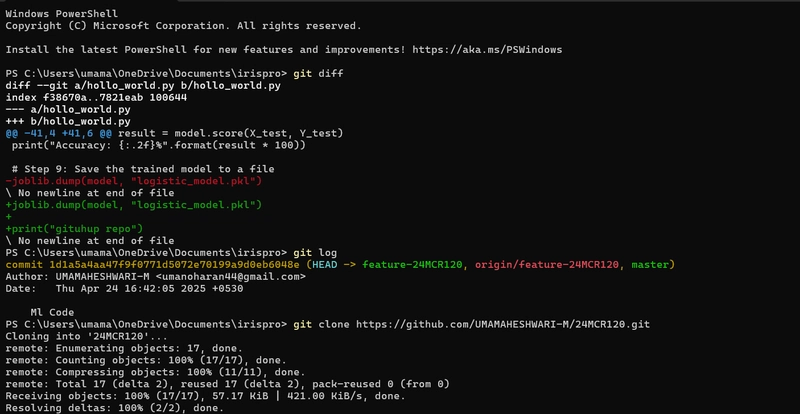
![[Free Webinar] Guide to Securing Your Entire Identity Lifecycle Against AI-Powered Threats](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjqbZf4bsDp6ei3fmQ8swm7GB5XoRrhZSFE7ZNhRLFO49KlmdgpIDCZWMSv7rydpEShIrNb9crnH5p6mFZbURzO5HC9I4RlzJazBBw5aHOTmI38sqiZIWPldRqut4bTgegipjOk5VgktVOwCKF_ncLeBX-pMTO_GMVMfbzZbf8eAj21V04y_NiOaSApGkM/s1600/webinar-play.jpg?#)






































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)











































































































































































































































































































































































![Google Home app fixes bug that repeatedly asked to ‘Set up Nest Cam features’ for Nest Hub Max [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/08/youtube-premium-music-nest-hub-max.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


































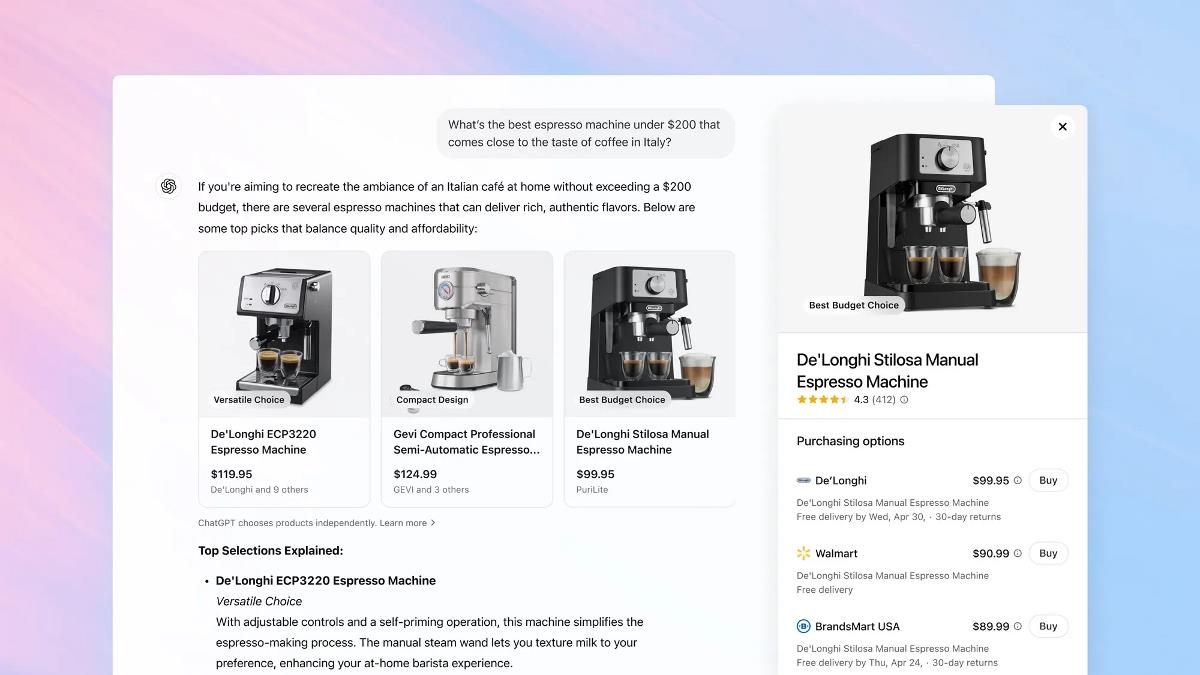



















![Epic Games Wins Major Victory as Apple is Ordered to Comply With App Store Anti-Steering Injunction [Updated]](https://images.macrumors.com/t/Z4nU2dRocDnr4NPvf-sGNedmPGA=/2250x/article-new/2022/01/iOS-App-Store-General-Feature-JoeBlue.jpg)






















































Vector Databases: their utility and functioning (RAG usage)
A reflection on vector databases and their usage by LLMs, by implementing a rudimentary one! Introduction TLDR; Vector databases have emerged as a critical infrastructure component in the era of Large Language Models (LLMs). Traditional databases, designed for structured data and exact keyword matching, fall short when dealing with the nuanced, high-dimensional data that LLMs process and generate. LLMs excel at understanding the semantic meaning of text and other data types, transforming them into dense vector embeddings that capture these relationships. Vector databases are specifically engineered to store, index, and efficiently query these complex vector embeddings. The necessity of vector databases for LLMs stems from the following key reasons: Semantic Understanding: LLMs convert text, images, audio, and other unstructured data into vector embeddings, which numerically represent the meaning and context of the data. Vector databases provide a way to store and retrieve these embeddings based on semantic similarity, enabling LLMs to understand the relationships between different pieces of information. Efficient Similarity Search: LLM applications often require finding information that is semantically similar to a query. Vector databases are optimized for performing fast and accurate similarity searches across large volumes of high-dimensional vectors, a task that traditional databases struggle with. Extending LLM Knowledge with External Data (RAG): A significant use case is Retrieval-Augmented Generation (RAG). LLMs have broad general knowledge from their training data, but they might lack specific or up-to-date information. By integrating LLMs with vector databases containing embeddings of domain-specific knowledge, relevant context can be retrieved and provided to the LLM before generating a response. This significantly improves the accuracy and relevance of the LLM’s output and mitigates the issue of “hallucinations.” Handling Unstructured Data: LLMs are adept at processing unstructured data. Vector databases provide a mechanism to store and query the vector representations of this unstructured data, allowing LLMs to work with and reason over diverse data formats effectively. Scalability and Performance: As the amount of data processed by LLMs grows, the underlying infrastructure needs to scale efficiently. Vector databases are designed to handle large datasets of vector embeddings and provide low-latency retrieval, which is crucial for real-time LLM applications. In essence, vector databases act as a specialized memory and retrieval system for LLMs, enabling them to access and utilize vast amounts of information in a semantically meaningful and efficient way. This synergy unlocks a wide range of advanced AI applications, from enhanced search and question answering to personalized recommendations and sophisticated content generation. Sources: Cisco, Jfrog, snowflake, aws and IBM
A reflection on vector databases and their usage by LLMs, by implementing a rudimentary one!
Introduction
TLDR;
Vector databases have emerged as a critical infrastructure component in the era of Large Language Models (LLMs). Traditional databases, designed for structured data and exact keyword matching, fall short when dealing with the nuanced, high-dimensional data that LLMs process and generate. LLMs excel at understanding the semantic meaning of text and other data types, transforming them into dense vector embeddings that capture these relationships. Vector databases are specifically engineered to store, index, and efficiently query these complex vector embeddings.
The necessity of vector databases for LLMs stems from the following key reasons:
- Semantic Understanding: LLMs convert text, images, audio, and other unstructured data into vector embeddings, which numerically represent the meaning and context of the data. Vector databases provide a way to store and retrieve these embeddings based on semantic similarity, enabling LLMs to understand the relationships between different pieces of information.
- Efficient Similarity Search: LLM applications often require finding information that is semantically similar to a query. Vector databases are optimized for performing fast and accurate similarity searches across large volumes of high-dimensional vectors, a task that traditional databases struggle with.
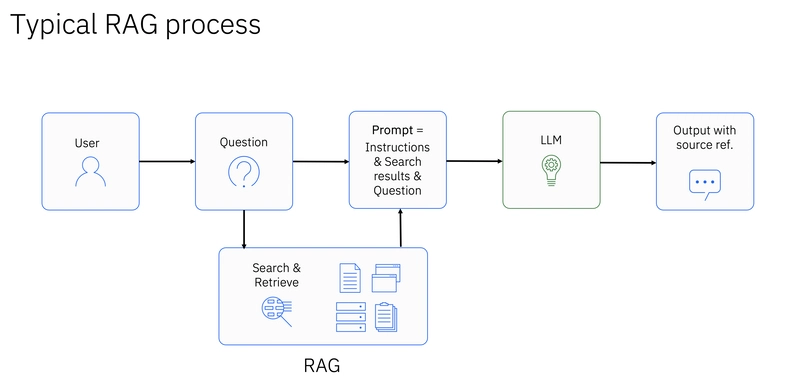
- Extending LLM Knowledge with External Data (RAG): A significant use case is Retrieval-Augmented Generation (RAG). LLMs have broad general knowledge from their training data, but they might lack specific or up-to-date information. By integrating LLMs with vector databases containing embeddings of domain-specific knowledge, relevant context can be retrieved and provided to the LLM before generating a response. This significantly improves the accuracy and relevance of the LLM’s output and mitigates the issue of “hallucinations.”
- Handling Unstructured Data: LLMs are adept at processing unstructured data. Vector databases provide a mechanism to store and query the vector representations of this unstructured data, allowing LLMs to work with and reason over diverse data formats effectively.
- Scalability and Performance: As the amount of data processed by LLMs grows, the underlying infrastructure needs to scale efficiently. Vector databases are designed to handle large datasets of vector embeddings and provide low-latency retrieval, which is crucial for real-time LLM applications.
In essence, vector databases act as a specialized memory and retrieval system for LLMs, enabling them to access and utilize vast amounts of information in a semantically meaningful and efficient way. This synergy unlocks a wide range of advanced AI applications, from enhanced search and question answering to personalized recommendations and sophisticated content generation.
Sources: Cisco, Jfrog, snowflake, aws and IBM