




























![[Free Webinar] Guide to Securing Your Entire Identity Lifecycle Against AI-Powered Threats](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjqbZf4bsDp6ei3fmQ8swm7GB5XoRrhZSFE7ZNhRLFO49KlmdgpIDCZWMSv7rydpEShIrNb9crnH5p6mFZbURzO5HC9I4RlzJazBBw5aHOTmI38sqiZIWPldRqut4bTgegipjOk5VgktVOwCKF_ncLeBX-pMTO_GMVMfbzZbf8eAj21V04y_NiOaSApGkM/s1600/webinar-play.jpg?#)






































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)





































































































































































































































































































































































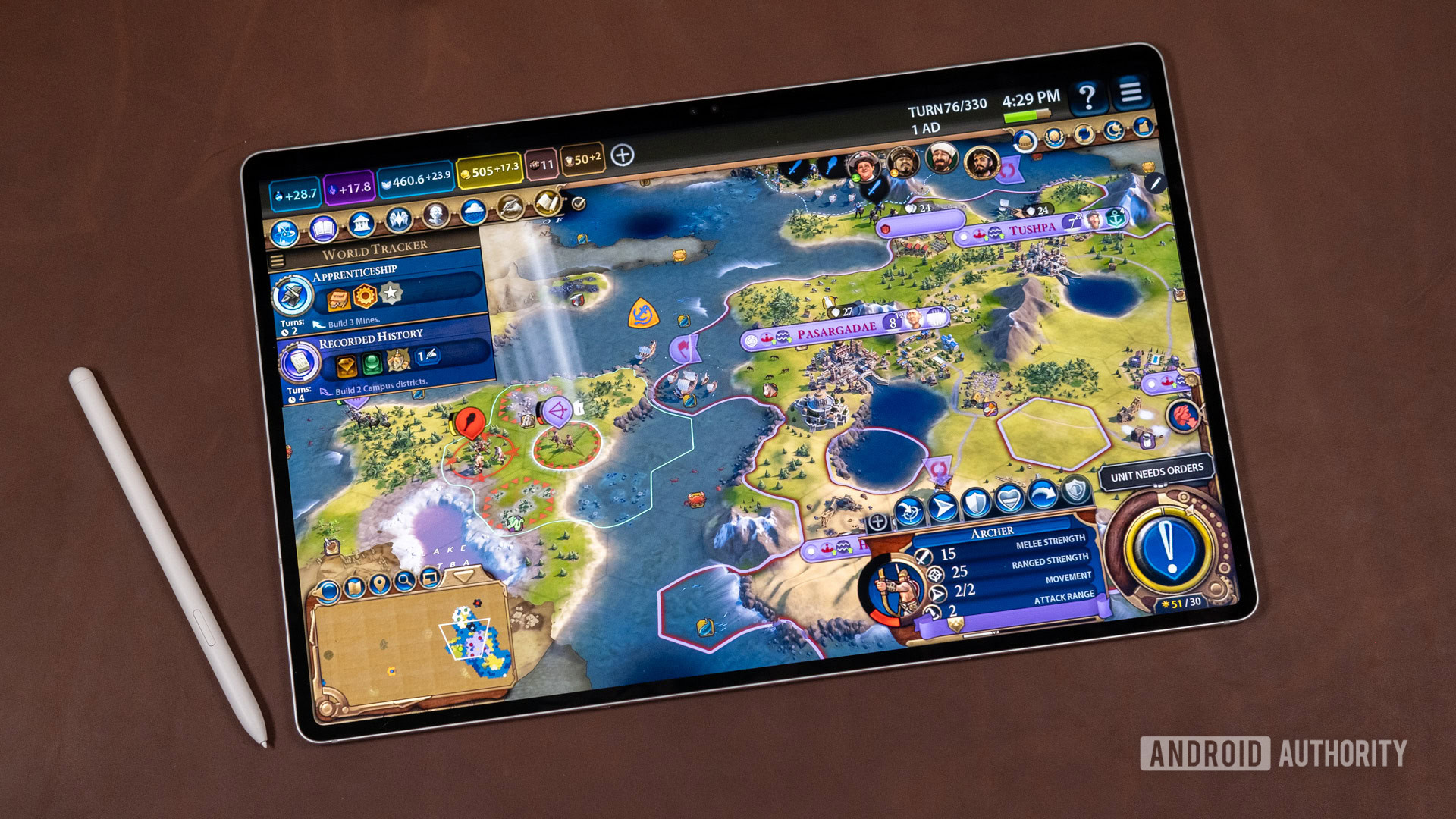





![Google Home app fixes bug that repeatedly asked to ‘Set up Nest Cam features’ for Nest Hub Max [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/08/youtube-premium-music-nest-hub-max.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)





















































![Epic Games Wins Major Victory as Apple is Ordered to Comply With App Store Anti-Steering Injunction [Updated]](https://images.macrumors.com/t/Z4nU2dRocDnr4NPvf-sGNedmPGA=/2250x/article-new/2022/01/iOS-App-Store-General-Feature-JoeBlue.jpg)






















































Reinforcement Learning from One Example?
Why 1-shot RLVR might be the breakthrough we've been waiting for The post Reinforcement Learning from One Example? appeared first on Towards Data Science.

New research from Microsoft and academic collaborators has overturned that assumption. Using Reinforcement Learning with Verifiable Rewards (RLVR) and just a single training example, researchers achieved results on par with models trained on over a thousand examples, sometimes even better.
This improvement isn’t just incremental progress. It’s a rethinking of how we fine-tune large language models (LLMs) for reasoning tasks. In this post, we’ll unpack what 1-shot RLVR is, how it works, and what it means for developers building math agents, automated tutors, and reasoning copilots.

1-Shot RLVR: What Is It?
RLVR is a flavor of reinforcement learning where the model is trained using verifiable reward signals, typically 0/1 based on whether the output is correct. In contrast to reward models used in Rlhf, RLVR uses hard ground truth.
What the authors discovered is that if you apply RLVR to a base model (e.g., Qwen2.5-Math-1.5B) and train it on just one carefully selected math example, performance on benchmark tasks can nearly double.
The Numbers That Stun
Here’s what happens when you train Qwen2.5-Math-1.5B on just one example:
- MATH500 Accuracy: Jumps from 36.0% → 73.6%
- Avg. Across 6 Math Benchmarks: Improves from 17.6% → 35.7%
Even using two examples yielded 74.8% on MATH500 and 36.6% average, slightly outperforming the full 1.2k dataset the example was selected from.
This result wasn’t limited to a fluke. Many different examples produced ~30% or more gains when used individually.
Why Does This Approach Work?
The paper introduces several hypotheses and findings:
- Policy Gradient Loss Does the Heavy Lifting: Removing this from the training pipeline causes gains to disappear, showing it’s the main driver of improvements.
- Entropy Loss Encourages Exploration: Adding entropy regularization, even without reward, boosts performance by over 25%.
- Post-Saturation Generalization: Accuracy on the training example quickly hits 100%, yet generalization on test sets keeps improving.
- Cross-Domain Effects: A geometry example improved performance on algebra and number theory, too.
- Self-Reflection Increases: Models trained via 1-shot RLVR show more frequent use of “rethink,” “recheck,” and “recalculate.”
Implications for Developers
If you’re building LLM-powered reasoning tools, math solvers, science tutors, or data agents, this technique offers enormous leverage:
- You don’t need big data: A single example can go a long way.
- You don’t need OpenAI access: It works with open models like Qwen and LLaMA.
- You don’t need human labels: Many examples already exist in curated math datasets like MATH or DeepScaleR.
Imagine building an AI tutor that learns from a single problem and generalizes across the curriculum. That future just got closer.
Beyond Math: Early Signs of Transfer
The authors evaluated on the ARC-Challenge and ARC-Easy, non-mathematical reasoning benchmarks.
Here’s what they found for Qwen2.5-Math-1.5B:
- Base model: 48.0 (ARC-E), 30.2 (ARC-C)
- After 1-shot RLVR (π13): 55.8 (ARC-E), 33.4 (ARC-C)
That’s a gain over even full-dataset RLVR. Training on a math problem helped the model become a better commonsense reasoner.
What Makes a Good Example?
Using historical training variance to select high-impact examples (π1 and π13) worked well. But surprisingly, many examples work, even those with low variance.
There’s no perfect recipe yet, but the early insight is promising:
“Almost all examples improve performance when used in 1-shot RLVR.”
When One Isn’t Enough
For some models, particularly distilled ones like DeepSeek-R1-Distill-Qwen-1.5B, performance gains from 1-shot RLVR were more modest (~6.9%). But moving to 4-shot or 16-shot setups showed steady improvement.
This implies that model family and training history matter, but the general trend holds: you need far less data than we thought.
The Role of Entropy: Why Exploration Matters
One of the paper’s most surprising discoveries is that entropy loss alone, even without rewards, can yield large gains.
Example: Training Qwen2.5-Math-1.5B with only entropy loss improves MATH500 from 36.0% to 63.4% in 20 steps.
This reveals a powerful principle:
Letting models explore more freely helps them generalize even from one example.
1-Shot ≠ Grokking
Post-saturation generalization may remind some of grokking, where models suddenly generalize after long periods of overfitting.
But ablation studies show 1-shot RLVR isn’t the same:
- It doesn’t rely on weight decay.
- Gains are immediate and sustained.
- It appears tied to policy gradients and entropy-driven exploration.
The Future: Smarter Data, Smaller Footprints
This paper serves as a timely reminder. More data isn’t always the answer. Better data, better selection, and reinforcement learning, even from one example, can unlock powerful capabilities in your base models.
For developers, this means
- You can build performant math agents with minimal compute.
- You can use RLVR to fine-tune open models with cheap, verifiable rewards.
- You can beat massive datasets with a single, well-chosen problem.
How Adaptive Helps You Go from Prototype to Production
While the results of 1-shot RLVR are impressive in research, applying them at scale requires the right tools and infrastructure. That’s where Adaptive Engine comes in.
Whether you’re fine-tuning models on a single math problem or optimizing agents across business domains, Adaptive gives you the full flywheel:
Adapt
Outperform frontier models with reinforcement fine-tuning that works, even with limited data. Adaptive makes it easy to run GRPO or PPO on open models with just a few examples and verifiable rewards.
Evaluate
Before you deploy, you need confidence. Adaptive supports personalized, production-aligned evaluations, so you can benchmark improvements on your real-world workloads, not just abstract benchmarks.
Serve
With fast, efficient inference, Adaptive lets you host tuned models wherever you need them, on cloud, edge, or hybrid infrastructure. High performance, low latency.
From day-one experimentation to at-scale deployment, Adaptive helps you:
- Identify high-impact examples with variance-based scoring.
- Run lightweight RL pipelines without wrangling compute.
- Measure what matters for your business use case.
The post Reinforcement Learning from One Example? appeared first on Towards Data Science.

