![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)











































































































































































































































































































































































![Google Home app fixes bug that repeatedly asked to ‘Set up Nest Cam features’ for Nest Hub Max [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/08/youtube-premium-music-nest-hub-max.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
























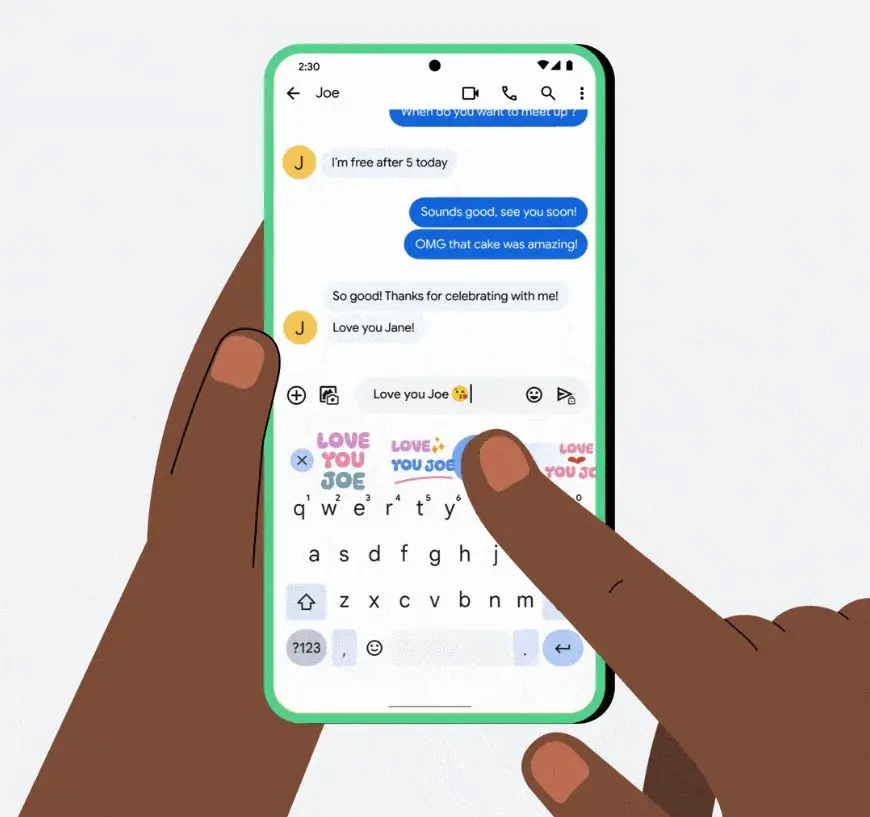


























![Epic Games Wins Major Victory as Apple is Ordered to Comply With App Store Anti-Steering Injunction [Updated]](https://images.macrumors.com/t/Z4nU2dRocDnr4NPvf-sGNedmPGA=/2250x/article-new/2022/01/iOS-App-Store-General-Feature-JoeBlue.jpg)






















































The ultimate open source stack for building AI agents
Guide for devs who want to do more than chat with chatbots 1. introduction We’ve gone from “talking to bots” to “building entire armies of agents” in less time than it takes Google to sunset a product. Everyone’s trying to slap a face on an LLM and call it a co-pilot, but let’s be real most AI agents today are overhyped wrappers with fancy prompt engineering. But something wild is happening in open source: the tools are getting good. The AI agent ecosystem is no longer just LangChain tutorials and broken JSON outputs. We’re talking autonomous loops, real memory, tools that take actions, and open models that aren’t gatekept by billion-dollar APIs. This guide is for developers who: want to build AI agents that do things, not just talk prefer GitHub stars over Gartner charts think memes belong in technical docs (you’re right) We’re going to unpack the most useful open-source tools, the stacks that actually work, what sucks, and how to stitch it all together with just enough code to feel powerful not overwhelmed. 2. the anatomy of an ai agent how agents actually “think” without hallucinating their way into your system logs So… what exactly is an AI agent? It’s not just ChatGPT with a calendar plugin. A real AI agent is like a scrappy little intern that can: perceive the world (through user input or sensors) decide what to do (planning or reasoning) remember stuff (short/long-term memory) take action (run code, use APIs, control devices) and loop that whole process again and again. Here’s a simple loop that most modern agent systems follow: perceive → think → decide → act → repeat You can think of it like a game loop but instead of drawing pixels or shooting bullets, it’s fetching data, analyzing it, and triggering actions. And yes, it can still crash for dumb reasons like forgetting a variable name. key components of an AI agent: You could wrap this in a LangChain agent, a CrewAI setup, or even build your own DAG-based loop using LangGraph. But under the hood, this is the skeleton every serious agent shares. Tip for devs: Start with something dumb like “Read this page, summarize, and email it” then evolve from there. 3. your starter toolkit: the core stack build your AI agent with tools that don’t ghost you behind an API paywall So, you’ve got the loop: perceive → think → decide → act. Now let’s give your agent the actual tools to do its job. Think of this like building a modded Minecraft character default Steve just won’t cut it. Below are the open-source components you’ll want in your base stack: 1. language models (the brain) This is where most people start the LLM that does the “thinking.” Top open-source picks: Mistral 7B Fast, strong on reasoning, supports function calling. LLaMA 3 Meta’s latest; great accuracy but resource-heavy. OpenChat Fine-tuned for chat agents with great function-calling logic. If you want to run them locally, use: Ollama (Mac/Linux/Windows) dead simple model runner. LM Studio dev-friendly desktop UI. 2. embeddings (for memory & search) Your agent needs to understand context, retrieve documents, and relate ideas. That’s where embeddings come in. Go-to open models: BGE Works great with RAG setups. E5 Balanced between performance and size. GTE Good accuracy in multilingual use cases. These turn your docs, user chats, or memories into numbers your agent can “remember.” 3. vector databases (where memory lives) You’ll store those embeddings somewhere searchable. Top options: Qdrant — Rust-powered, fast, with filtering & hybrid search. Weaviate — Comes with hybrid search and GraphQL support. LanceDB — Built for local workflows, fast and lightweight. Bonus: Many of these work with chromadb if you're just prototyping. 4. memory/state manager (short-term brain) Memory is tricky your agent needs to remember past interactions and use them properly. Solid picks: LangGraph’s memory system Graph-based reasoning with persistent memory. Redis Fast but ephemeral unless configured. SQLite Great for simple local storage of message history. Visual idea: Add a graphic here of LEGO bricks labeled: LLM (Mistral), Embedding (BGE), Vector DB (Qdrant), Memory (LangGraph/Redis) ⚠️ Avoid analysis paralysis. Just pick one from each category and move on. Perfection comes later, not during setup. 4. memory matters: don’t be a goldfish why most ai agents forget everything and how not to suck at memory Ever asked your agent something and it responded like it’s never met you before? Welcome to the goldfish problem. Most agents have the memory of a TikTok-scrolling raccoon. They can respond intelligently once, then forget the whole convo five seconds later. Not ideal if you’re building anything remotely useful. short-term vs. long-term memory AI agents need both to function properly: The short-term memory is like your browser tab session kill it, and everything resets. Long-term memory is like bookmarks + cookies persistent and searchable.

Guide for devs who want to do more than chat with chatbots
1. introduction
We’ve gone from “talking to bots” to “building entire armies of agents” in less time than it takes Google to sunset a product. Everyone’s trying to slap a face on an LLM and call it a co-pilot, but let’s be real most AI agents today are overhyped wrappers with fancy prompt engineering.
But something wild is happening in open source: the tools are getting good. The AI agent ecosystem is no longer just LangChain tutorials and broken JSON outputs. We’re talking autonomous loops, real memory, tools that take actions, and open models that aren’t gatekept by billion-dollar APIs.
This guide is for developers who:
- want to build AI agents that do things, not just talk
- prefer GitHub stars over Gartner charts
- think memes belong in technical docs (you’re right)
We’re going to unpack the most useful open-source tools, the stacks that actually work, what sucks, and how to stitch it all together with just enough code to feel powerful not overwhelmed.
2. the anatomy of an ai agent
how agents actually “think” without hallucinating their way into your system logs
So… what exactly is an AI agent?
It’s not just ChatGPT with a calendar plugin. A real AI agent is like a scrappy little intern that can:
- perceive the world (through user input or sensors)
- decide what to do (planning or reasoning)
- remember stuff (short/long-term memory)
- take action (run code, use APIs, control devices)
- and loop that whole process again and again.
Here’s a simple loop that most modern agent systems follow:
perceive → think → decide → act → repeat
You can think of it like a game loop but instead of drawing pixels or shooting bullets, it’s fetching data, analyzing it, and triggering actions. And yes, it can still crash for dumb reasons like forgetting a variable name.
key components of an AI agent:
You could wrap this in a LangChain agent, a CrewAI setup, or even build your own DAG-based loop using LangGraph. But under the hood, this is the skeleton every serious agent shares.
Tip for devs: Start with something dumb like “Read this page, summarize, and email it” then evolve from there.
3. your starter toolkit: the core stack
build your AI agent with tools that don’t ghost you behind an API paywall
So, you’ve got the loop: perceive → think → decide → act.
Now let’s give your agent the actual tools to do its job. Think of this like building a modded Minecraft character default Steve just won’t cut it.
Below are the open-source components you’ll want in your base stack:
1. language models (the brain)
This is where most people start the LLM that does the “thinking.”
Top open-source picks:
- Mistral 7B Fast, strong on reasoning, supports function calling.
- LLaMA 3 Meta’s latest; great accuracy but resource-heavy.
- OpenChat Fine-tuned for chat agents with great function-calling logic.
If you want to run them locally, use:
2. embeddings (for memory & search)
Your agent needs to understand context, retrieve documents, and relate ideas. That’s where embeddings come in.
Go-to open models:
- BGE Works great with RAG setups.
- E5 Balanced between performance and size.
- GTE Good accuracy in multilingual use cases.
These turn your docs, user chats, or memories into numbers your agent can “remember.”
3. vector databases (where memory lives)
You’ll store those embeddings somewhere searchable.
Top options:
- Qdrant — Rust-powered, fast, with filtering & hybrid search.
- Weaviate — Comes with hybrid search and GraphQL support.
- LanceDB — Built for local workflows, fast and lightweight.
Bonus: Many of these work with chromadb if you're just prototyping.
4. memory/state manager (short-term brain)
Memory is tricky your agent needs to remember past interactions and use them properly.
Solid picks:
- LangGraph’s memory system Graph-based reasoning with persistent memory.
- Redis Fast but ephemeral unless configured.
- SQLite Great for simple local storage of message history.
Visual idea: Add a graphic here of LEGO bricks labeled:
- LLM (Mistral),
- Embedding (BGE),
- Vector DB (Qdrant),
- Memory (LangGraph/Redis)
⚠️ Avoid analysis paralysis. Just pick one from each category and move on. Perfection comes later, not during setup.
4. memory matters: don’t be a goldfish
why most ai agents forget everything and how not to suck at memory
Ever asked your agent something and it responded like it’s never met you before?
Welcome to the goldfish problem.
Most agents have the memory of a TikTok-scrolling raccoon. They can respond intelligently once, then forget the whole convo five seconds later. Not ideal if you’re building anything remotely useful.
short-term vs. long-term memory
AI agents need both to function properly:
The short-term memory is like your browser tab session kill it, and everything resets.
Long-term memory is like bookmarks + cookies persistent and searchable.
how memory works in real stacks
Let’s break it down in real terms:
- User says something
- It gets embedded into vectors
- Vectors go into Qdrant/Weaviate
- On the next prompt, the agent does semantic search to “remember” relevant stuff
- It uses that memory in the prompt (context window)
- Rinse & repeat
That’s why vector quality and embedding quality matter.
memory frameworks worth exploring
- LangGraph DAG-based memory flow for complex agents.
- MemGPT Designed for multi-modal agents and memory lifecycles.
- ReAct pattern Reason + act + memory loop used in many custom agents.
real-world use case
Let’s say you’re building a research assistant like Cursor.dev or an IDE agent.
You’d want:
- short-term memory to track the current coding session
- long-term memory to remember the project goals, user commands, or preferred code styles
Failing to add memory = the agent becomes a very smart goldfish in a tuxedo.
5. actions speak louder than tokens
Your agent isn’t smart until it can click buttons, call APIs, and run scripts like a real dev
At some point, your AI agent needs to do something not just ramble like a philosophy major on cold brew.
That “doing” part? It’s tool use.
Think:
- Sending emails
- Hitting APIs
- Querying databases
- Running shell commands
- Updating a Notion board because you’re that guy
Without tool use, your agent is basically a glorified autocomplete.
meet the action frameworks
Here’s what’s powering modern tool-using agents:

tool usage in the wild
Example:
Let’s say your agent is helping manage a Shopify store. It might:
- Use OpenAI or Mistral for understanding a customer’s message
- Pull up recent order data from a PostgreSQL database
- Trigger a Zapier webhook to update inventory
- Write and send a follow-up email using SendGrid API
That’s not just prompting. That’s automation with a brain.

Tools vs agents
Remember: tools ≠ agents.
Tools are the hands. Agents are the brain.
You need both to build something useful. And if your agent starts calling the wrong tools? That’s on your planning logic, not the LLM.
6. orchestrators: the brain behind the agents
because a bunch of tools without coordination is just chaos in a hoodie
Let’s say your AI agent has:
- A good brain (LLM),
- Some sharp tools (APIs, scripts),
- Memory (short and long-term),
- And maybe even a nice voice interface.
Cool.
But who’s deciding what happens when?
That’s where orchestrators come in the strategic planners of your AI army. Without one, your agent is like a DevOps pipeline with 17 steps and zero triggers.
Top orchestrators worth using
Here are the open source orchestration frameworks that don’t suck:

Orchestration patterns
Most orchestrators follow one of these patterns:
- Finite state machine → Great for predefined flows (e.g., onboarding agents, transaction steps)
- Decision graphs (DAGs) → Like LangGraph define reasoning paths and loop conditions
- Reactive loop → Event triggers > response > plan > act > feedback (used by ReAct, AutoGen)
- Planner + executor split → One agent plans, another acts (used in BabyAGI, GPT Engineer clones)
Real world example
Imagine you’re building a travel assistant agent.
You’d need to:
- Parse the user’s request
- Query flight APIs
- Book hotels
- Handle exceptions like “my passport expired yesterday”
An orchestrator like LangGraph would let you:
- Branch logic if a passport is expired
- Loop actions until confirmation is received
- Store memory of past bookings or user preferences
That’s not just workflow that’s logic orchestration with memory and tool calls in sync.
Pro tip: If your agent ever tries to “book a flight” before confirming the destination, your orchestration layer needs a timeout and a therapist.
7. front-end and UX for agents
because talking to a terminal is fun… until your user rage-quits
So your AI agent can plan, remember, call APIs, and act like it runs a startup.
But how does it actually talk to people?
If you’re still using a barebones CLI with readline(), congrats — you’re the only user.
Let’s change that.
Text interfaces: the MVP default
Start simple a chat UI is usually enough.
Use these tools:
- React + shadcn/ui Fast and pretty frontend components
- Vercel AI SDK Drop-in streaming chat with React
- Langchain Chat UI Prebuilt, but customizable
If you’re running it locally, try LM Studio or Ollama + chat UI for instant frontend hooks.
Voice interfaces: your agent but with actual vibes
If you want your agent to sound less like a PDF reader and more like Jarvis-lite, it’s time to give it a voice.
Start by hooking up speech-to-text (STT) using something like OpenAI’s Whisper if you’re going open source, or Deepgram if you want a super-accurate plug-and-play API.
Next, for text-to-speech (TTS), tools like Play.ht give you lifelike voices with custom accents and tone controls, while OpenVoice lets you clone voices like you’re building your own mini Morgan Freeman.
To stitch this into a conversational loop, Vocode is one of the best frameworks around for creating voice-based agents that talk and listen like a sci-fi assistant. If you’re a control freak (respect), roll your own using WebRTC and JavaScript.
Voice-enabled agents shine in customer support setups, in-car assistants, or honestly just as the MVP at any cyberpunk hackathon. Bonus: nothing makes a demo hit harder than an AI that talks back without sounding like a GPS from 2008.
Game-style and 3D agents: yes, it’s a thing
Want your agent to live in a world instead of a chat bubble? Try:
- Godot + LLM backend
- Unity agent wrappers
- WebGL or three.js for browser-based simulations
People are building virtual AI companions, teaching agents in simulated rooms, and yes making Clippy but cool.
dev-style interface ideas
Don’t forget that your UX is also your debugger.
Some agent devs now include:
- Realtime logs and memory state display
- “Why did you do that?” explanation buttons
- “Rewind” or “Fork session” features
Good UX = easier debugging when your agent thinks Paris is in Italy.
Dev note: Even if it’s just you using it build a UI. Talking to your agent in a Discord bot or terminal gets old fast.
8. hosting and deployment
because your agent isn’t real until it crashes in prod
You’ve built your agent. It thinks, talks, remembers, acts, and even cracks a joke. But now you need to put it somewhere it can live, breathe, and occasionally panic at 3 a.m. like all good software.
Let’s walk through the ways to host your AI agent, from bare metal to cloud magic.
Run it locally (dev-first option)
For fast prototyping or personal use, local is king. Here’s how most devs do it:
- Use Ollama to run LLMs like Mistral, LLaMA, or OpenChat on your machine. It’s one command to load and run.
- Wrap your logic in a FastAPI or Flask backend to expose endpoints.
- Toss in LangServe if you’re using LangChain and want auto-generated APIs.
With that setup, you’ve got a self-contained agent server.
You can run it on localhost or toss it onto a spare cloud VM.
Bonus: You avoid model rate limits, paywalls, and outages caused by “oops, our API key got banned.”
Go full cloud mode (because we like CI/CD chaos)
When you’re ready for public exposure (your agent, not you), these are solid cloud options:
- Fly.io Deploy Docker containers close to users, great for edge agents.
- Vercel If you’ve got a frontend-heavy agent, this works beautifully with React + serverless endpoints.
- Modal Great for dynamic LLM workloads with scale-on-demand, especially for inference-heavy agents.
- Replicate For running models directly via API with zero infrastructure.
Hook any of these up with GitHub Actions for deployments, and your agent’s alive, versioned, and continuously evolving (hopefully not in a Skynet direction).
Infra tips from the trenches
- Keep logs. No, seriously. Agents fail in hilarious ways.
- Add request tracing especially when chaining tools and memory.
- Deploy a simple dashboard to see active sessions, memory state, and last actions taken. It’ll save you hours.
- Start small. Run it as a container, expose a port, add logging, then scale up.
Real talk: you don’t need Kubernetes for a side project with one user. Use a .env file, a Dockerfile, and your brain.
9. pitfalls & gotchas: don’t get caught slipping
because your agent is only one hallucination away from emailing someone’s bank account
Let’s be honest: building AI agents is fun, until it isn’t.
Right when you think you’ve nailed it, your agent:
- forgets what it was doing mid-task,
- tries to call the wrong tool,
- or responds with a JSON object that looks like it went through a blender.
Here are some common pitfalls that will sneak up on you if you’re not careful and how to dodge them like a boss.
latency hell
You chained six tools together, added RAG, called an external API, and threw in a TTS reply.
Congrats, your response time is now longer than a coffee break.
Fix it:
- Preload common memory chunks.
- Use async calls.
- Cache everything that makes sense (models, results, tool outputs).
Memory overload
Agents that remember everything become unusable. You’ll end up feeding them a prompt window longer than your README.
Fix it:
- Trim memory context before each step.
- Use relevance filtering when querying vector DBs.
- Consider memory expiration for short-term junk.
Tool confusion
Sometimes the agent “forgets” how a tool works or just calls the wrong one entirely.
Fix it:
- Use structured tool calling (OpenAI tool schema or LangChain tools).
- Add self-checks and validations for tool outputs.
- Don’t let your agent pick from 20 tools at once it’s not a genius, it’s a guesser.
Bad vector search = bad memory
Embedding garbage in, garbage out. If your vector DB returns irrelevant docs, your agent will hallucinate facts like “Finland is in South America.”
Fix it:
- Pick high-quality embeddings (like BGE or E5).
- Use hybrid search (text + vector) when possible.
- Always test your queries with actual inputs.
When things just explode
Sometimes your agent just… breaks. Stack overflows, recursive loops, API rate limits, you name it.
Fix it:
- Add circuit breakers or retry logic.
- Log everything (input, output, tool call, model error).
- Let your orchestrator handle fallback plans or alternate paths.
Building agents is more chaotic than building a CRUD app and that’s the fun. Just don’t deploy without a helmet.
10. the future: what’s next in open source agent stacks
because we’re not stopping at clippy 2.0 the next wave is wild
If the current open source agent stack is the early internet of AI agents, then what’s next is the dot-com boom… with fewer sock puppets and more agents that actually do stuff.
Let’s explore where things are heading.
Sovereign LLMs and offline agents
One big trend: fully offline, self-hosted agents.
Dev teams and privacy nerds are moving away from closed APIs toward open-source models like LLaMA 3 or Mistral running on Ollama, LM Studio, or bare Dockerized setups.
You’ll see agents that:
- don’t need OpenAI keys
- run completely on local GPUs or edge devices
- handle sensitive workflows (think local dev assistants, medical triage bots, etc.)
Expect open weights + tight security to become the new normal.
Auto-evolving agents
Tools like BabyAGI and EvoAgent are experimenting with agents that evolve themselves.
These agents:
- learn from failed tasks
- create sub-agents to solve new problems
- write their own improvement plans
It’s still early and wildly unstable but the idea of self-improving software is no longer sci-fi.
Planning agents that think before they speak
The era of prompt-only reasoning is ending. More devs are building agents with:
- explicit planning stages
- DAGs or trees of thoughts
- Modular task decomposers
Expect tools like LangGraph, OpenDevin, and AutoGen to grow more powerful as we get serious about real-world autonomy.
Multi-agent collaboration
Why use one agent when you can use a team?
Frameworks like CrewAI and AutoGen let you spawn role-based agents one for planning, one for execution, one for QA — all working together.
Imagine a dev team of AI coworkers that:
- Assign and track tasks
- Review each other’s output
- Call tools or APIs based on specialty
Yes, it’s like managing junior devs. Except they don’t sleep or argue over dark mode vs. light mode.
Embodied and 3D agents
From NPCs powered by LLMs in Unity or Godot, to robots using LLMs + sensors, we’re heading toward agents that live inside environments, not just chat boxes.
Expect open source tools to merge AI brains with physics, vision, and interaction and yeah, it’s going to be weird in the best way.
11. conclusion
you don’t need a VC-backed lab to build a killer AI agent just curiosity and a GitHub tab open
If you’ve made it this far, congrats you now understand more about AI agents than half the VC pitch decks out there.
Let’s recap what you’ve built (or are about to build):
- A thinking loop (perceive → reason → act)
- A working stack of open-source tools: language models, memory, tool use, orchestrators
- A front-end that doesn’t suck
- A deployment that’s more than localhost:3000
- A roadmap to dodge disasters and laugh when your agent says Paris is in Australia
This stuff isn’t science fiction anymore. The open-source AI stack has matured and it’s more accessible, hackable, and powerful than ever.
So don’t wait for AGI to show up with a résumé. Start small:
- Make an agent that reads and summarizes emails.
- Or one that books your calendar.
- Or builds and tears down cloud infrastructure on command.
It’ll be dumb at first. You’ll debug for hours. It’ll hallucinate something horrifying.
But then one day… it’ll work. And it’ll feel like magic.
Want to keep going?
Here are a few good next steps:
- Clone and experiment with OpenDevin or CrewAI
- Follow the awesome agents list: github.com/e2b-dev/awesome-ai-agents
- Watch projects like LangGraph, MemGPT, and AutoGen
- Try building your own agent with Ollama, Qdrant, and a basic FastAPI backend
Enjoyed this story?
If you liked it, please leave a comment sharing what topic you’d like to see next!
Feel free to like, share it with your friends, and subscribe to get updates when new posts go live.