








































































































































































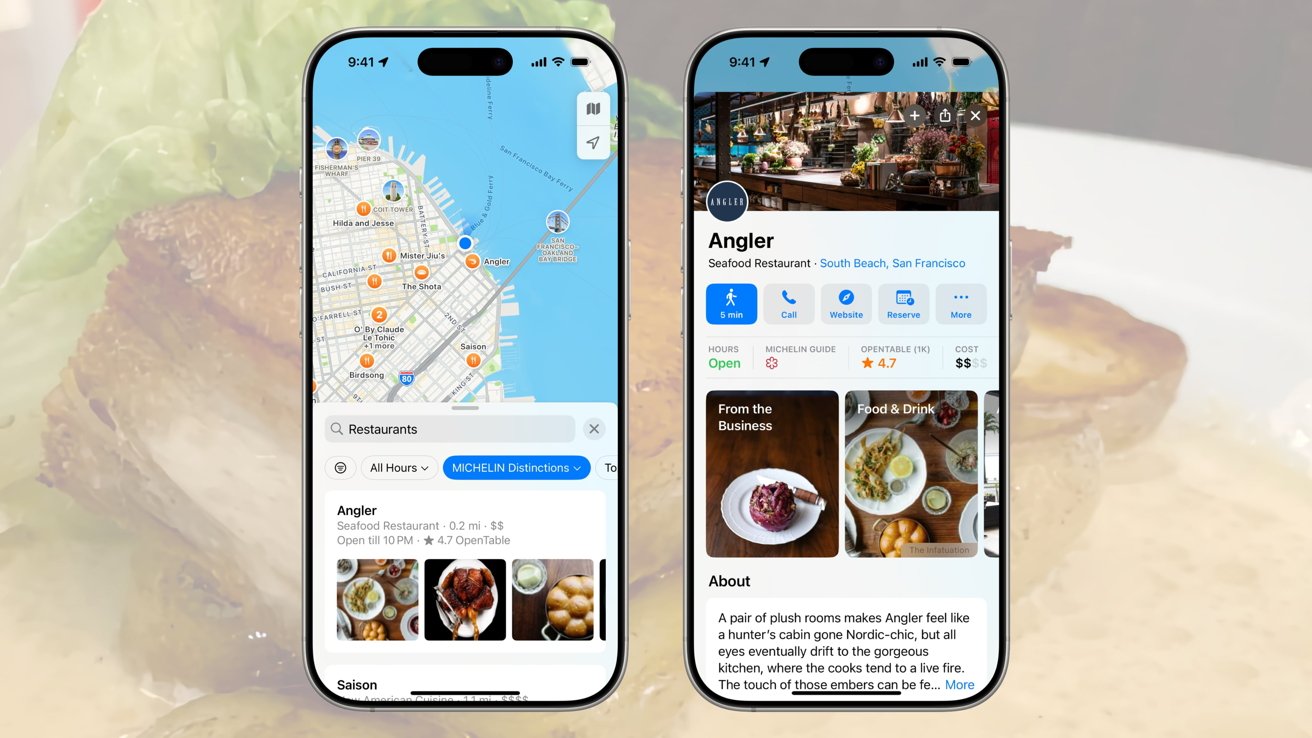
![[The AI Show Episode 147]: OpenAI Abandons For-Profit Plan, AI College Cheating Epidemic, Apple Says AI Will Replace Search Engines & HubSpot’s AI-First Scorecard](https://www.marketingaiinstitute.com/hubfs/ep%20147%20cover.png)





























































































































































































![Legends Reborn tier list of best heroes for each class [May 2025]](https://media.pocketgamer.com/artwork/na-33360-1656320479/pg-magnum-quest-fi-1.jpeg?#)
































































_KristofferTripplaar_Alamy_.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_Gang_Liu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
.webp?#)
















































































-xl.jpg)


























![Vision Pro May Soon Let You Scroll With Your Eyes [Report]](https://www.iclarified.com/images/news/97324/97324/97324-640.jpg)
![Apple's 20th Anniversary iPhone May Feature Bezel-Free Display, AI Memory, Silicon Anode Battery [Report]](https://www.iclarified.com/images/news/97323/97323/97323-640.jpg)






























































































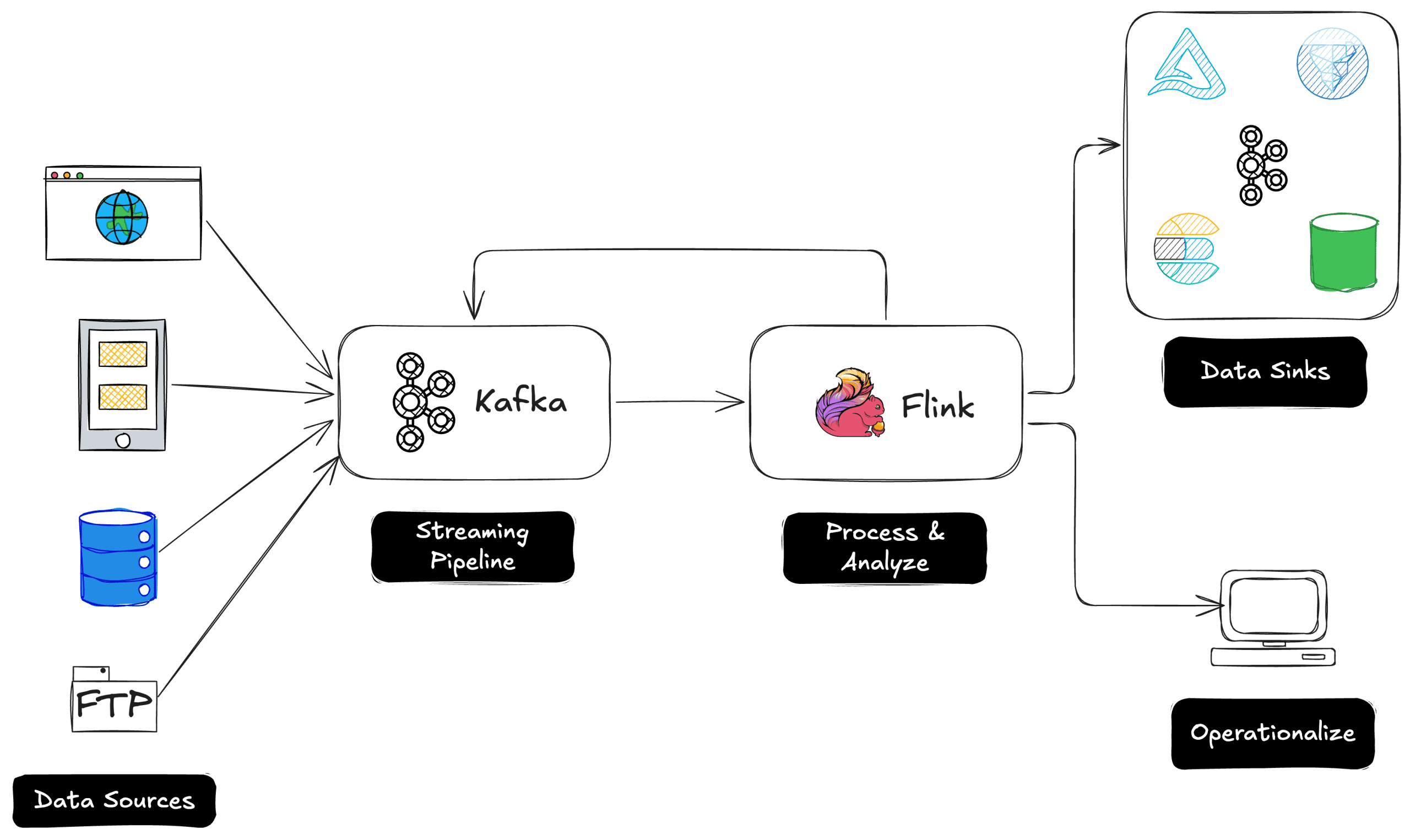
Parquet File Format – Everything You Need to Know!
New data flavors require new ways for storing it! Learn everything you need to know about the Parquet file format The post Parquet File Format – Everything You Need to Know! appeared first on Towards Data Science.

Another challenge was to somehow stick with a traditional approach to have data stored in a structured way, but without the necessity to design complex and time-consuming ETL workloads to move this data into the enterprise data warehouse. Additionally, what if half of the data professionals in your organization are proficient with, let’s say, Python (data scientists, data engineers), and the other half (data engineers, data analysts) with SQL? Would you insist that “Pythonists” learn SQL? Or, vice-versa?
Or, would you prefer a storage option that can play to the strengths of your entire data team? I have good news for you – something like this has already existed since 2013, and it’s called Apache Parquet!
Parquet file format in a nutshell
Before I show you the ins and outs of the Parquet file format, there are (at least) five main reasons why Parquet is considered a de facto standard for storing data nowadays:
- Data compression – by applying various encoding and compression algorithms, Parquet file provides reduced memory consumption
- Columnar storage – this is of paramount importance in analytic workloads, where fast data read operation is the key requirement. But, more on that later in the article…
- Language agnostic – as already mentioned previously, developers may use different programming languages to manipulate the data in the Parquet file
- Open-source format – meaning, you are not locked with a specific vendor
- Support for complex data types
Row-store vs Column-store
We’ve already mentioned that Parquet is a column-based storage format. However, to understand the benefits of using the Parquet file format, we first need to draw the line between the row-based and column-based ways of storing the data.
In traditional, row-based storage, the data is stored as a sequence of rows. Something like this:

Now, when we are talking about OLAP scenarios, some of the common questions that your users may ask are:
- How many balls did we sell?
- How many users from the USA bought a T-shirt?
- What is the total amount spent by customer Maria Adams?
- How many sales did we have on January 2nd?
To be able to answer any of these questions, the engine must scan each and every row from the beginning to the very end! So, to answer the question: how many users from the USA bought T-shirt, the engine has to do something like this:

Essentially, we just need the information from two columns: Product (T-Shirts) and Country (USA), but the engine will scan all five columns! This is not the most efficient solution – I think we can agree on that…
Column store
Let’s now examine how the column store works. As you may assume, the approach is 180 degrees different:

In this case, each column is a separate entity – meaning, each column is physically separated from other columns! Going back to our previous business question: the engine can now scan only those columns that are needed by the query (Product and country), while skipping scanning the unnecessary columns. And, in most cases, this should improve the performance of the analytical queries.
Ok, that’s nice, but the column store existed before Parquet and it still exists outside of Parquet as well. So, what is so special about the Parquet format?
Parquet is a columnar format that stores the data in row groups
Wait, what?! Wasn’t it complicated enough even before this? Don’t worry, it’s much easier than it sounds  Read More
Read More

