







































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)








































.jpg?#)


.jpg?#)
































































































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![Alleged iPhone 17-19 Roadmap Leaked: Foldables and Spring Launches Ahead [Kuo]](https://www.iclarified.com/images/news/97214/97214/97214-640.jpg)

![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
































































































May the Nodes Be with You
Knowledge graphs are powerful tools to visualize and explore your data, and can help uncover new insights and patterns in how your data is related. They are easy to search and navigate, but getting your data into the graph database in the right format can be challenging. And the resulting graph is only as good as the data--- or as they say, garbage in, garbage out. So it's important to define a good schema, or ontology, that describes the entities and relationships you want to extract from your data. With unstructured text, you can use an LLM to extract entities and relationships, and then generate a Cypher query using the model (guide). This can take a lot of the work out of generating the Cypher queries but it comes with the risk of hallucinations, and the security and privacy concerns of sending your data to a 3rd party. When working with structured data though, you can just write a function to map over the data and build the Cypher query programmatically, without the risk of hallucinations, or sharing your data with a 3rd party. With just a few lines of JavaScript, you can map over API responses and bulk insert data into a knowledge graph to use for exploring data visually, or building a RAG pipeline. In this guide, we'll be using the Star Wars API to fetch data about an episode, and all of the planets, star ships, vehicles and species mentioned in it. Then, we'll map over that data to build a Cypher query, and run it to build a new graph. Topics Covered: Using the Star Wars API Merging data from multiple endpoints with JavaScript Mapping the results to a Cypher query Running the query via Neo4j's REST API Let's get to it! Using the Star Wars API The original Star Wars API (swapi.co) was a free API with data on Star Wars characters, planets, ships, etc. It is no longer maintained, but a few newer API providers offer a similar service. For this guide, I'll be using swapi.info. Just like the original API, swapi.info works without a login and is completely free to use. Take a look at the JSON structure for a record from the /films endpoint. There's a title, and a few other data points, and then arrays for characters, planets, starships, vehicles, and species. Each one of those array entries link to another endpoint, and record, with more details. We can use this data to build a knowledge graph by mapping over it and building a Cypher query to insert the data into Neo4j. Local Neo4j and Appsmith For this guide, I'll be using Neo4j as the graph database, and Appsmith to run the API calls and write the JavaScript. Check out this tutorial on how to deploy both in Docker, or you can use the cloud versions of Appsmith and Neo4j/AuraDB. Alright, let's graph the planets and species in the first 3 movies and see how they are related. Notice how in the JSON above, each related record is just a link, and doesn't include the title or name of the entity. This means we'll have to loop through all the related records to lookup the name or title before the graph can be built. Normally I would use the REST API query in Appsmith, but in this case the looping can be handled nicely with fetch(), and a dynamic URL. Merging data from multiple endpoints with JavaScript In Appsmith, create a new JSObject named SWAPI and paste in the following: export default { filmData: [], async loadFilms() { const base = 'https://swapi.info/api'; const fetchJson = async url => { const res = await fetch(url); if (!res.ok) throw new Error(`Failed to fetch ${url}`); return res.json(); }; const rawFilms = await Promise.all( [1, 2, 3].map(id => fetchJson(`${base}/films/${id}`)) ); const planetUrls = [...new Set(rawFilms.flatMap(f => f.planets))]; const speciesUrls = [...new Set(rawFilms.flatMap(f => f.species))]; const [planetObjs, speciesObjs] = await Promise.all([ Promise.all(planetUrls.map(fetchJson)), Promise.all(speciesUrls.map(fetchJson)) ]); const planetMap = new Map(planetObjs.map(p => [p.url, p.name])); const speciesMap = new Map(speciesObjs.map(s => [s.url, s.name])); this.filmData = rawFilms.map(f => ({ episode_id: f.episode_id, title: f.title, planets: f.planets.map(url => planetMap.get(url)), species: f.species.map(url => speciesMap.get(url)) })); return this.filmData; } } This loops over each related endpoint and returns a new films object with the actual names/titles of the related entities, instead of the URL. Ok, now that we have all the names, we can loop over all the child arrays and generate a Cypher query. Mapping the results to a Cypher query The most important step in building a knowledge graph is planning out an ontology, or schema for the entities and relationships you want to represent. For this example, I'll be representing the first 3 films (episodes 4-6), and a portion of the planets and species, to limit the gra

Knowledge graphs are powerful tools to visualize and explore your data, and can help uncover new insights and patterns in how your data is related. They are easy to search and navigate, but getting your data into the graph database in the right format can be challenging. And the resulting graph is only as good as the data--- or as they say, garbage in, garbage out. So it's important to define a good schema, or ontology, that describes the entities and relationships you want to extract from your data.
With unstructured text, you can use an LLM to extract entities and relationships, and then generate a Cypher query using the model (guide). This can take a lot of the work out of generating the Cypher queries but it comes with the risk of hallucinations, and the security and privacy concerns of sending your data to a 3rd party.
When working with structured data though, you can just write a function to map over the data and build the Cypher query programmatically, without the risk of hallucinations, or sharing your data with a 3rd party. With just a few lines of JavaScript, you can map over API responses and bulk insert data into a knowledge graph to use for exploring data visually, or building a RAG pipeline.
In this guide, we'll be using the Star Wars API to fetch data about an episode, and all of the planets, star ships, vehicles and species mentioned in it. Then, we'll map over that data to build a Cypher query, and run it to build a new graph.
Topics Covered:
Using the Star Wars API
Merging data from multiple endpoints with JavaScript
Mapping the results to a Cypher query
Running the query via Neo4j's REST API
Let's get to it!
Using the Star Wars API
The original Star Wars API (swapi.co) was a free API with data on Star Wars characters, planets, ships, etc. It is no longer maintained, but a few newer API providers offer a similar service. For this guide, I'll be using swapi.info. Just like the original API, swapi.info works without a login and is completely free to use.
Take a look at the JSON structure for a record from the /films endpoint.
There's a title, and a few other data points, and then arrays for characters, planets, starships, vehicles, and species. Each one of those array entries link to another endpoint, and record, with more details. We can use this data to build a knowledge graph by mapping over it and building a Cypher query to insert the data into Neo4j.
Local Neo4j and Appsmith
For this guide, I'll be using Neo4j as the graph database, and Appsmith to run the API calls and write the JavaScript. Check out this tutorial on how to deploy both in Docker, or you can use the cloud versions of Appsmith and Neo4j/AuraDB.
Alright, let's graph the planets and species in the first 3 movies and see how they are related. Notice how in the JSON above, each related record is just a link, and doesn't include the title or name of the entity. This means we'll have to loop through all the related records to lookup the name or title before the graph can be built.
Normally I would use the REST API query in Appsmith, but in this case the looping can be handled nicely with fetch(), and a dynamic URL.
Merging data from multiple endpoints with JavaScript
In Appsmith, create a new JSObject named SWAPI and paste in the following:
export default {
filmData: [],
async loadFilms() {
const base = 'https://swapi.info/api';
const fetchJson = async url => {
const res = await fetch(url);
if (!res.ok) throw new Error(`Failed to fetch ${url}`);
return res.json();
};
const rawFilms = await Promise.all(
[1, 2, 3].map(id => fetchJson(`${base}/films/${id}`))
);
const planetUrls = [...new Set(rawFilms.flatMap(f => f.planets))];
const speciesUrls = [...new Set(rawFilms.flatMap(f => f.species))];
const [planetObjs, speciesObjs] = await Promise.all([
Promise.all(planetUrls.map(fetchJson)),
Promise.all(speciesUrls.map(fetchJson))
]);
const planetMap = new Map(planetObjs.map(p => [p.url, p.name]));
const speciesMap = new Map(speciesObjs.map(s => [s.url, s.name]));
this.filmData = rawFilms.map(f => ({
episode_id: f.episode_id,
title: f.title,
planets: f.planets.map(url => planetMap.get(url)),
species: f.species.map(url => speciesMap.get(url))
}));
return this.filmData;
}
}
This loops over each related endpoint and returns a new films object with the actual names/titles of the related entities, instead of the URL.

Ok, now that we have all the names, we can loop over all the child arrays and generate a Cypher query.
Mapping the results to a Cypher query
The most important step in building a knowledge graph is planning out an ontology, or schema for the entities and relationships you want to represent. For this example, I'll be representing the first 3 films (episodes 4-6), and a portion of the planets and species, to limit the graph size to 20 nodes.
Add a new function to the JSObject to map the filmData to a Cypher query.
generate20NodeGraphRequest(data = this.filmData) {
const films = data;
const allPlanets = [...new Set(films.flatMap(f => f.planets))];
const allSpecies = [...new Set(films.flatMap(f => f.species))];
// allocate 20 nodes: 3 films + X planets + Y species = 20
let remaining = 20 - films.length; // 17
const planets = allPlanets.slice(0, remaining);
remaining -= planets.length; // leftover for species
const species = allSpecies.slice(0, remaining);
const cypher = `
UNWIND $films AS filmObj
WITH filmObj
MERGE (f:Film {episode_id: filmObj.episode_id, title: filmObj.title})
WITH filmObj, f
CALL {
WITH filmObj, f
UNWIND filmObj.planets AS pname
WITH f, pname
WHERE pname IN $planets
MERGE (p:Planet {name: pname})
MERGE (p)-[:FEATURED_IN]->(f)
RETURN COUNT(*) AS planetCount
}
CALL {
WITH filmObj, f
UNWIND filmObj.species AS spname
WITH f, spname
WHERE spname IN $species
MERGE (s:Species {name: spname})
MERGE (s)-[:FEATURED_IN]->(f)
RETURN COUNT(*) AS speciesCount
}
RETURN f
`.trim();
return {
statements: [{
statement: cypher,
parameters: { films, planets, species }
}]
};
}
This uses the MERGE command to create-or-update the entities, and avoid duplicates. Each name or title is mapped into an array, and then turned into multiple records using UNWIND in the Cypher query.

Running the query via Neo4j's REST API
Ok, we have a Cypher query built from the Star Wars API data. Next, let's add an API to insert the data into Neo4j.
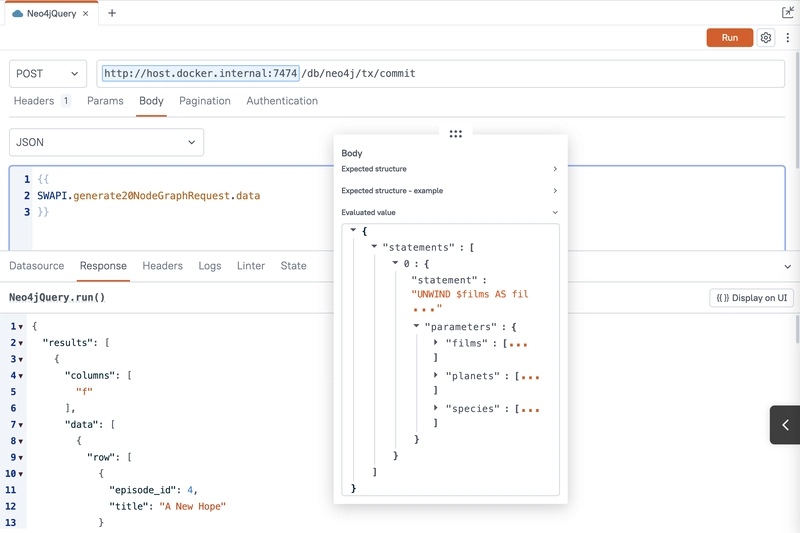
Once you have Neo4j running locally in Docker, create a new API in Appsmith to run a Cypher query.
| Name | RunCypher |
|---|---|
| Method | POST |
| URL | host.docker.internal/7474/db/neo4j/tx/commit |
| Body type | JSON |
| Body | {{ SWAPI.generate20NodeGraphRequest.data }} |
Then click the Save URL button to save the credentials to an Appsmith datasource.
Choose Basic for the Authentication type, and then enter your Neo4j user name and password, then click Save.

This will keep the credentials on the Appsmith server instead of in the app itself.
Since we're using Docker to run both Neo4j and Appsmith locally, the localhost URLs are replaced with host.docker.internal.
Run the query in Appsmith, and then open the Neo4j dashboard.
In Neo4j, select all the nodes and relationships by running the query:
MATCH p=()-[]->() RETURN p


Nice! Now we can easily see how all the planets and characters relate back to each movie. Or we can query the graph to answer questions like:
Which species appeared in all 3 films?
MATCH (s:Species)-[:FEATURED_IN]->(f:Film)
WHERE f.episode_id IN [4,5,6]
WITH s, count(DISTINCT f) AS appearances
WHERE appearances = 3
RETURN s.name AS Species


From here, you can use the Neo4j browser to explore the data, or query Neo4j via the API has part of a RAG pipeline.
Conclusion
It can be tempting to use LLMs to generate Cypher queries to insert graph data, but that comes with inherent risks of hallucination, and potential security and privacy issues. When working with structured data like JSON or SQL, you can map over the data using JavaScript to build the Cypher query programmatically, avoiding the risks of using an LLM to generate the query.
This allows you to build knowledge graphs with clearly defined relationships and a more repeatable structure than using LLMs to generate Cypher queries. With a little planning and a few lines of code, you can easily convert structured data into interactive knowledge graphs






