










































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Architecture for TypeScript backend with multiple entry points or apps [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
![Is This Programming Paradigm New? [closed]](https://miro.medium.com/v2/resize:fit:1200/format:webp/1*nKR2930riHA4VC7dLwIuxA.gif)

























































































-Classic-Nintendo-GameCube-games-are-coming-to-Nintendo-Switch-2!-00-00-13.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)











































































































































![M4 MacBook Air Drops to New All-Time Low of $912 [Deal]](https://www.iclarified.com/images/news/97108/97108/97108-640.jpg)
![New iPhone 17 Dummy Models Surface in Black and White [Images]](https://www.iclarified.com/images/news/97106/97106/97106-640.jpg)






























































































































How We Streamlined Infrastructure & CI/CD with Terraform, Jenkins & EKS
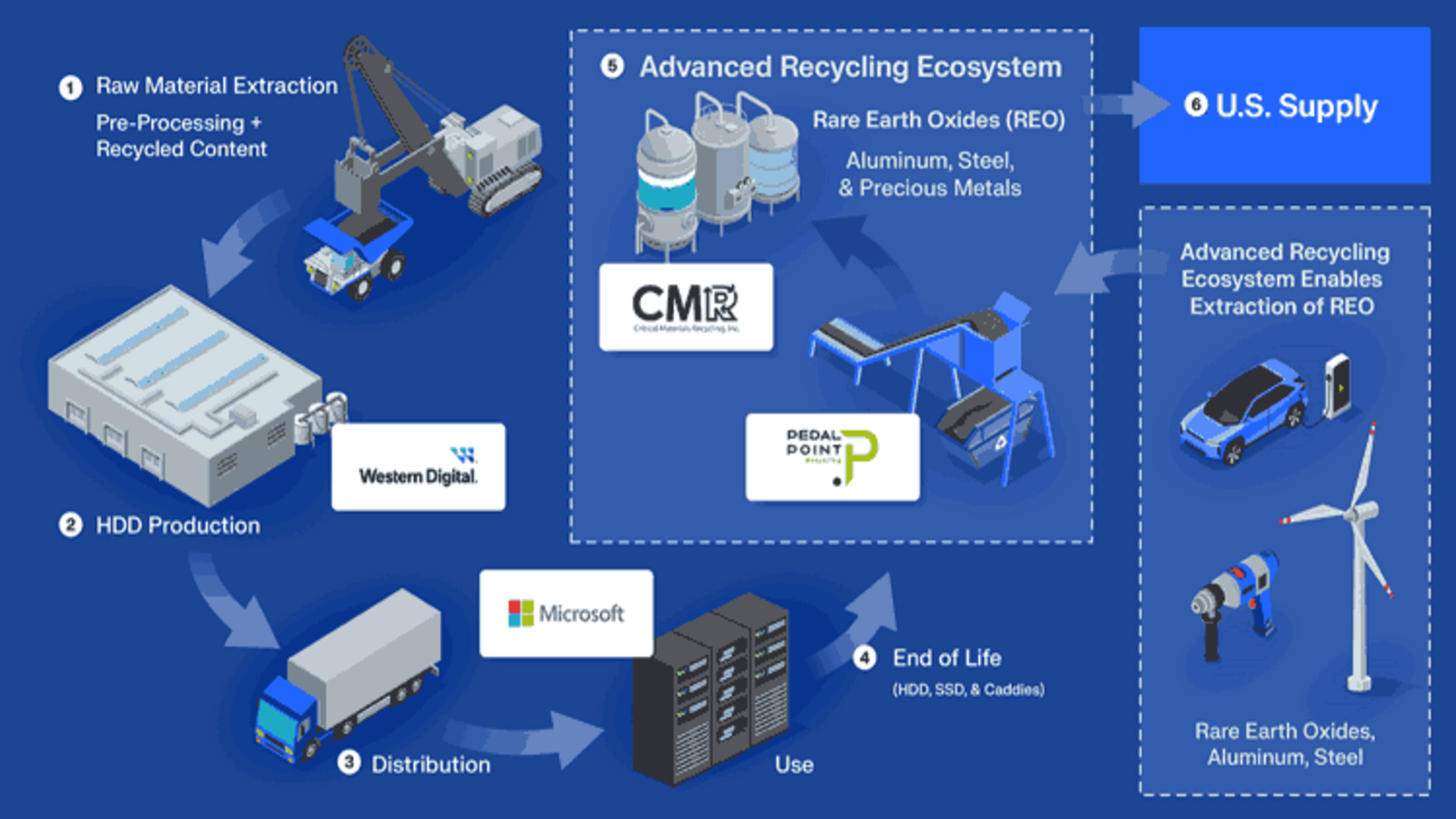
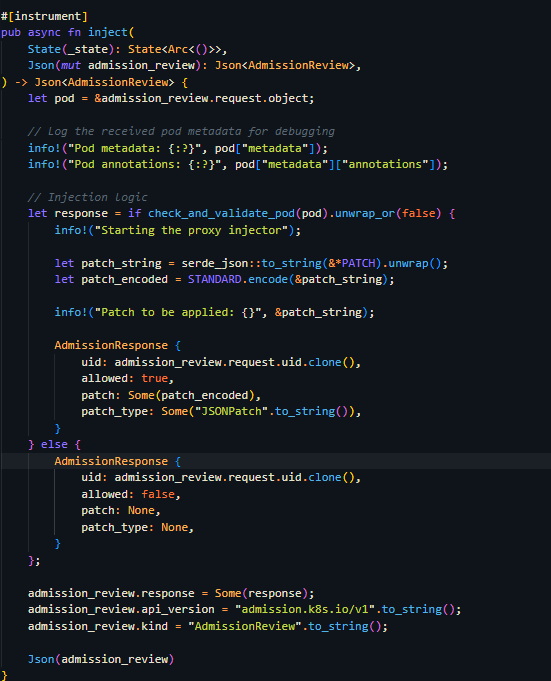
Over the past few months, my team and I have been focused on one thing: speeding up infrastructure provisioning and making our deployments rock-solid. We work with multiple clients, and every deployment used to feel like a gamble. To eliminate inconsistency and reduce turnaround time, we built a structured DevOps setup using Terraform, Jenkins, Docker, Helm, and AWS EKS. Here's how we approached it, what worked for us, and how you can replicate the same. Infrastructure Strategy: Terraform as the Backbone Before this, infrastructure changes were slow and unpredictable. Embracing Infrastructure as Code (IaC) with Terraform changed everything. We maintain a centralized, modular repository where every client has their own directory, and core services like EKS, logging, and monitoring are organized under a shared structure: root/ ├── eks/ │ ├── cluster/ │ ├── logging/ │ ├── monitoring/ ├── client1/ │ ├── mysql/ │ ├── redis/ │ ├── kafka/ └── clientN/ This modular layout allows us to replicate environments for new clients quickly. Spin-up time for new projects is down to minutes. For critical components like EKS and databases, we still run terraform apply manually to retain control and prevent cascading failures during changes. Our CI/CD Stack: Jenkins, Docker, Helm & EKS After stabilizing infrastructure, we focused on creating a robust CI/CD pipeline that ensures fast, repeatable, and safe deployments. Our toolchain includes: Jenkins (on EC2) – Orchestrates the entire pipeline. Docker – Containerizes the application for consistent environments. Helm – Manages Kubernetes deployments efficiently. SonarQube – Runs automated code quality checks. AWS SNS & SES – Handles notifications on build and deployment statuses. CI/CD Workflow Overview Here's a look at how a typical deployment works: Developer initiates a build. Jenkins pulls the latest code from GitLab. A secrets scan is run to prevent accidental exposure of credentials. Jenkins installs dependencies (Node, Maven, etc.). Code is scanned via SonarQube for quality and security issues. A Docker image is built and pushed to our registry. Helm templates are validated for correctness. Application is deployed to UAT in AWS EKS. If anything fails, Helm automatically triggers a rollback. Notifications are sent via AWS SES to keep the team informed. Upon approval, the image is promoted and deployed to production. Why This Works for Us Speed: Spinning up infrastructure and deploying code takes significantly less time. Reliability: Helm’s rollback mechanism ensures stability even if deployments fail. Scalability: Adding new clients or services doesn’t require reinventing the wheel. This setup has allowed us to standardize delivery, minimize errors, and spend less time firefighting and more time building. Share Your Experience This setup reflects our specific needs and experience. Every team is different. I’d like to know: How are you managing infrastructure for multiple environments? What tools are central to your CI/CD pipeline? Have you hit any scaling or reliability issues? Let’s exchange ideas. Drop a comment or message — and follow if you're interested in more practical DevOps stories.

Over the past few months, my team and I have been focused on one thing: speeding up infrastructure provisioning and making our deployments rock-solid. We work with multiple clients, and every deployment used to feel like a gamble.
To eliminate inconsistency and reduce turnaround time, we built a structured DevOps setup using Terraform, Jenkins, Docker, Helm, and AWS EKS.
Here's how we approached it, what worked for us, and how you can replicate the same.
Infrastructure Strategy: Terraform as the Backbone
Before this, infrastructure changes were slow and unpredictable. Embracing Infrastructure as Code (IaC) with Terraform changed everything.
We maintain a centralized, modular repository where every client has their own directory, and core services like EKS, logging, and monitoring are organized under a shared structure:
root/
├── eks/
│ ├── cluster/
│ ├── logging/
│ ├── monitoring/
├── client1/
│ ├── mysql/
│ ├── redis/
│ ├── kafka/
└── clientN/
This modular layout allows us to replicate environments for new clients quickly. Spin-up time for new projects is down to minutes.
For critical components like EKS and databases, we still run terraform apply manually to retain control and prevent cascading failures during changes.
Our CI/CD Stack: Jenkins, Docker, Helm & EKS
After stabilizing infrastructure, we focused on creating a robust CI/CD pipeline that ensures fast, repeatable, and safe deployments.
Our toolchain includes:
- Jenkins (on EC2) – Orchestrates the entire pipeline.
- Docker – Containerizes the application for consistent environments.
- Helm – Manages Kubernetes deployments efficiently.
- SonarQube – Runs automated code quality checks.
- AWS SNS & SES – Handles notifications on build and deployment statuses.
CI/CD Workflow Overview
Here's a look at how a typical deployment works:
- Developer initiates a build.
- Jenkins pulls the latest code from GitLab.
- A secrets scan is run to prevent accidental exposure of credentials.
- Jenkins installs dependencies (Node, Maven, etc.).
- Code is scanned via SonarQube for quality and security issues.
- A Docker image is built and pushed to our registry.
- Helm templates are validated for correctness.
- Application is deployed to UAT in AWS EKS.
- If anything fails, Helm automatically triggers a rollback.
- Notifications are sent via AWS SES to keep the team informed.
- Upon approval, the image is promoted and deployed to production.
Why This Works for Us
- Speed: Spinning up infrastructure and deploying code takes significantly less time.
- Reliability: Helm’s rollback mechanism ensures stability even if deployments fail.
- Scalability: Adding new clients or services doesn’t require reinventing the wheel.
This setup has allowed us to standardize delivery, minimize errors, and spend less time firefighting and more time building.
Share Your Experience
This setup reflects our specific needs and experience. Every team is different. I’d like to know:
- How are you managing infrastructure for multiple environments?
- What tools are central to your CI/CD pipeline?
- Have you hit any scaling or reliability issues?
Let’s exchange ideas. Drop a comment or message — and follow if you're interested in more practical DevOps stories.


