








































































































































































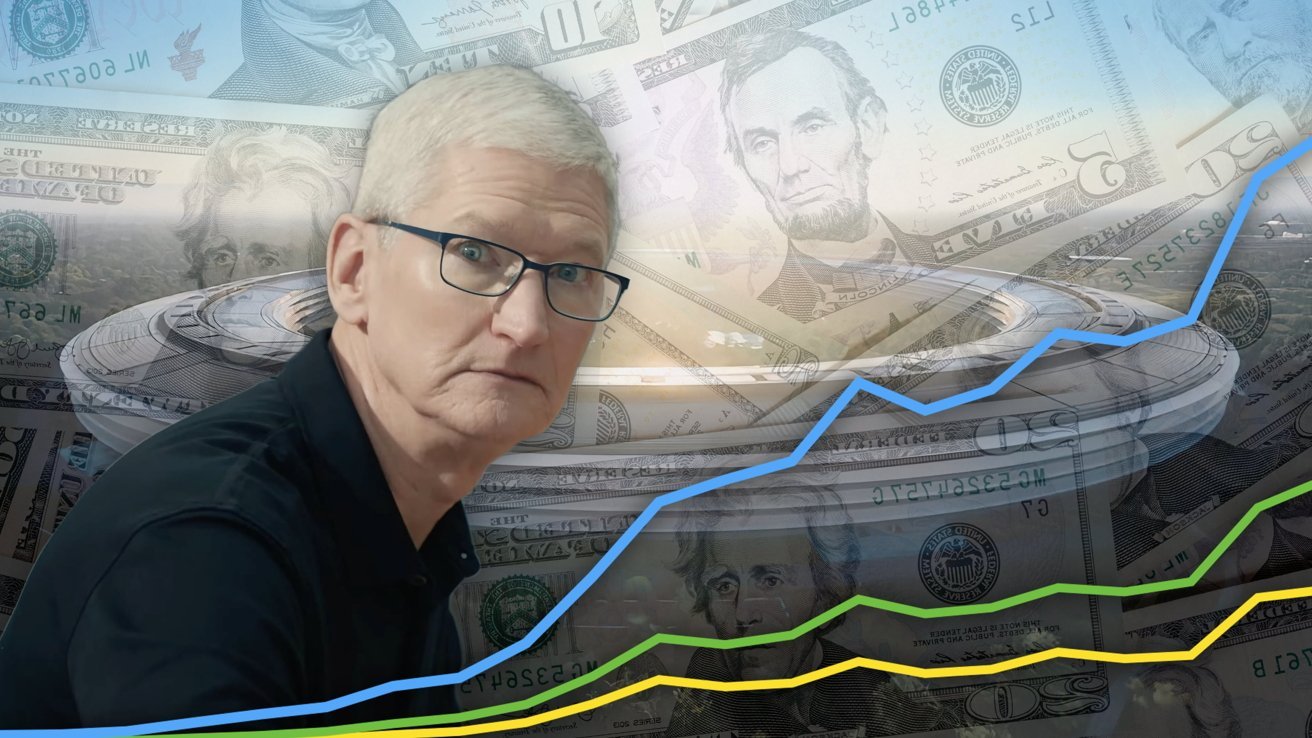
![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




















































































































































































































































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)













































































































![What iPhone 17 model are you most excited to see? [Poll]](https://9to5mac.com/wp-content/uploads/sites/6/2025/04/iphone-17-pro-sky-blue.jpg?quality=82&strip=all&w=290&h=145&crop=1)
















![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)





















































































































Explained: How Does L1 Regularization Perform Feature Selection?
Understanding automatic feature-selection performed by L1 (LASSO) Regularization The post Explained: How Does L1 Regularization Perform Feature Selection? appeared first on Towards Data Science.

Feature selection can be a manual or rather explicit process when performed with filter or wrapper methods. In these methods, features are added or removed iteratively based on the value of a fixed measure, which quantifies the relevance of the feature in the making the prediction. The measures could be information gain, variance or the chi-squared statistic, and the algorithm would make a decision to accept/reject the feature considering a fixed threshold on the measure. Note, these methods are not a part of the model training stage and are performed prior to it.
Embedded methods perform feature selection implicitly, without using any pre-defined selection criteria and deriving it from the training data itself. This intrinsic feature selection process is a part of the model training stage. The model learns to select features and make relevant predictions at the same time. In later sections, we will describe the role of regularization in performing this intrinsic feature selection.
Regularization and Model Complexity
Regularization is the process of penalizing the complexity of the model to avoid overfitting and achieve generalization over the task.
Here, the complexity of the model is analogous to its power to adapt to the patterns in the training data. Assuming a simple polynomial model in ‘x’ with degree ‘d’, as we increase the degree ‘d’ of the polynomial, the model achieves greater flexibility to capture patterns in the observed data.
Overfitting and Underfitting
If we are trying to fit a polynomial model with d = 2 on a set of training samples which were derived from a cubic polynomial with some noise, the model will not be able to capture the distribution of the samples to a sufficient extent. The model simply lacks the flexibility or complexity to model the data generated from a degree 3 (or higher order) polynomials. Such a model is said to under-fit on the training data.
Working on the same example, assume we now have a model with d = 6. Now with increased complexity, it should be easy for the model to estimate the original cubic polynomial that was used to generate the data (like setting the coefficients of all terms with exponent > 3 to 0). If the training process is not terminated at the right time, the model will continue to utilize its additional flexibility to reduce the error within further and start capturing in the noisy samples too. This will reduce the training error significantly, but the model now overfits the training data. The noise will change in real-world settings (or in the test phase) and any knowledge based on predicting them will disrupt, leading to high test error.
How to determine the optimal model complexity?
In practical settings, we have little-to-no understanding of the data-generation process or the true distribution of the data. Finding the optimal model with the right complexity, such that no under-fitting or overfitting occurs is a challenge.
One technique could be to start with a sufficiently powerful model and then reduce its complexity by means of feature selection. Lesser the features, lesser is the complexity of the model.
As discussed in the previous section, feature selection can be explicit (filter, wrapper methods) or implicit. Redundant features that have insignificant relevance in the determining the value of the response variable should be eliminated to avoid the model learning uncorrelated patterns in them. Regularization, also performs a similar task. So, how are regularization and feature selection connected to attain a common goal of optimal model complexity?
L1 Regularization As A Feature Selector
Continuing with our polynomial model, we represent it as a function f, with inputs x, parameters θ and degree d,

For a polynomial model, each power of the input x_i can be considered as a feature, forming a vector of the form,

We also define an objective function, which on minimizing leads us to the optimal parameters θ* and includes a regularization term penalizing the complexity of the model.

To determine the minima of this function, we need to analyze all of its critical points i.e. points where the derivation is zero or undefined.
The partial derivative w.r.t. one the parameters, θj, can be written as,

where the function sgn is defined as,

Note: The derivative of the absolute function is different from the sgn function defined above. The original derivative is undefined at x = 0. We augment the definition to remove the inflection point at x = 0 and to make the function differentiable across its entire domain. Moreover, such augmented functions are also used by ML frameworks when the underlying computation involves the absolute function. Check this thread on the PyTorch forum.
By computing the partial derivative of the objective function w.r.t. a single parameter θj, and setting it to zero, we can build an equation that relates the optimal value of θj with the predictions, targets, and features.


Let us examine the equation above. If we assume that the inputs and targets were centered about the mean (i.e. the data had been standardized in the preprocessing step), the term on the LHS effectively represents the covariance between the jth feature and the difference between the predicted and target values.
Statistical covariance between two variables quantifies how much one variable influences the value of the second variable (and vice-versa)
The sign function on the RHS forces the covariance on the LHS to assume only three values (as the sign function only returns -1, 0 and 1). If the jth feature is redundant and does not influence the predictions, the covariance will be nearly zero, bringing the corresponding parameter θj* to zero. This results in the feature being eliminated from the model.
Imagine the sign function as a canyon carved by a river. You can walk in the canyon (i.e. the river bed) but to get out of it, you have these huge barriers or steep slopes. L1 regularization induces a similar ‘thresholding’ effect for the gradient of the loss function. The gradient must be powerful enough to break the barriers or become zero, which eventually brings the parameter to zero.
For a more grounded example, consider a dataset that contains samples derived from a straight line (parameterized by two coefficients) with some added noise. The optimal model should have no more than two parameters, else it will adapt to the noise present in the data (with the added freedom/power to the polynomial). Changing the parameters of the higher powers in the polynomial model does not affect the difference between the targets and the model’s predictions, thus reducing their covariance with the feature.
During the training process, a constant step gets added/subtracted from the gradient of the loss function. If the gradient of the loss function (MSE) is smaller than the constant step, the parameter will eventually reach to a value of 0. Observe the equation below, depicting how parameters are updated with gradient descent,


If the blue part above is smaller than λα, which itself is a very small number, Δθj is the nearly a constant step λα. The sign of this step (red part) depends on sgn(θj), whose output depends on θj. If θj is positive i.e. greater than ε, sgn(θj) equals 1, hence making Δθj approx. equal to –λα pushing it towards zero.
To suppress the constant step (red part) that makes the parameter zero, the gradient of the loss function (blue part) has to be larger than the step size. For a larger loss function gradient, the value of the feature must affect the output of the model significantly.
This is how a feature is eliminated, or more precisely, its corresponding parameter, whose value does not correlate with the output of the model, is zero-ed by L1 regularization during the training.
Further Reading And Conclusion
- To get more insights on the topic, I have posted a question on r/MachineLearning subreddit and the resulting thread contains different explanations that you may want to read.
- Madiyar Aitbayev also has an interesting blog covering the same question, but with a geometrical explanation.
- Brian Keng’s blog explains regularization from a probabilistic perspective.
- This thread on CrossValidated explains why L1 norm encourages sparse models. A detailed blog by Mukul Ranjan explains why L1 norm encourages the parameters to become zero and not the L2 norm.
“L1 regularization performs feature selection” is a simple statement that most ML learners agree with, without diving deep into how it works internally. This blog is an attempt to bring my understanding and mental-model to the readers in order to answer the question in an intuitive manner. For suggestions and doubts, you can find my email at my website. Keep learning and have a nice day ahead!
The post Explained: How Does L1 Regularization Perform Feature Selection? appeared first on Towards Data Science.


