






















































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)










































































































































































































































































_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































![Craft adds Readwise integration for working with book notes and highlights [50% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/craft3.jpg.png?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)































































































How to Design a Write-Heavy System: A Beginner-Friendly Guide You’ll Want to Bookmark
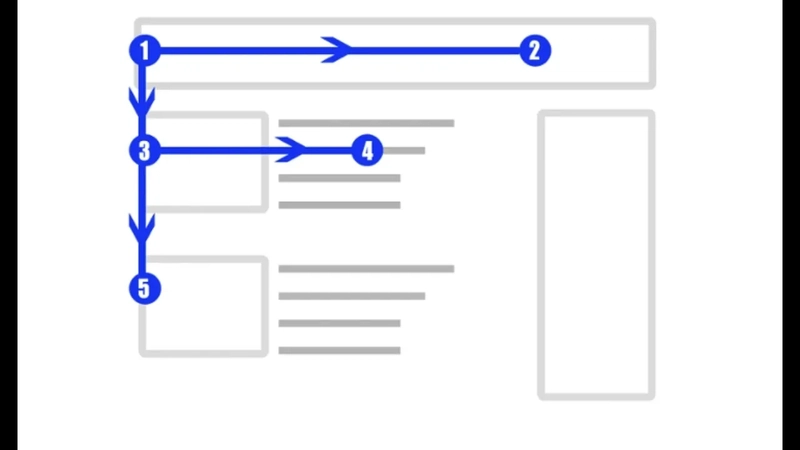
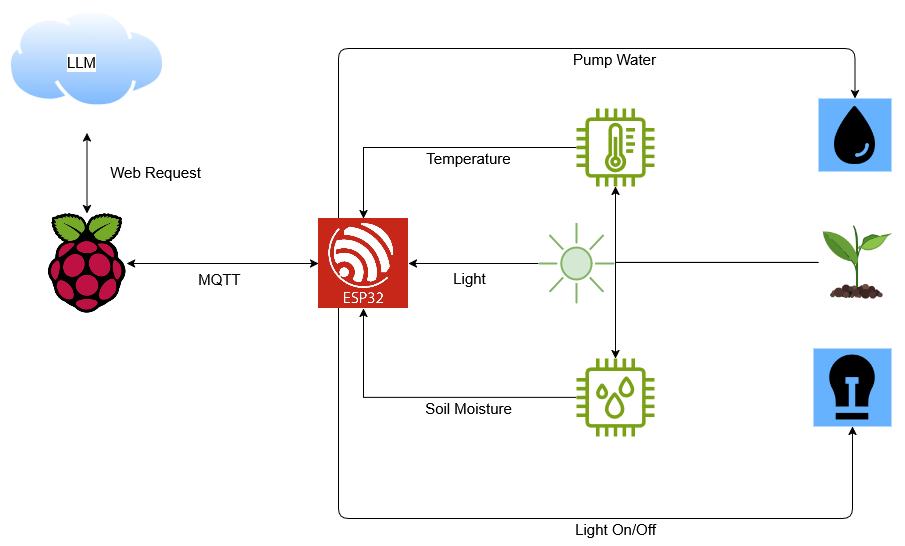
When designing a system that handles a lot of incoming data—like transactions, logs, messages or orders—your priority is not reading that data, but writing it fast and efficiently. These systems are called write-heavy systems. This guide breaks down the process in a way that anyone can understand, with an analogy that sticks. Whether you're a beginner building your first backend or a seasoned engineer setting up a scalable pipeline, this is your go-to checklist. Imagine Your System is an Ice Cream Shop In our analogy: Customers = users Orders = write operations (inserts/updates) Menu views = read operations (queries) In a write-heavy system, people are mostly placing orders—not just browsing the menu. Let's walk through how to set up a system that can take those orders quickly and reliably. Step 1: Understand What You're Handling Before choosing databases or tech stacks, ask yourself: What kind of data is being written? (e.g., chat messages, transactions, logs) How frequently is data written? Do you need to store it forever or just for a short time? This helps you define the structure and volume of your database. Step 2: Use Bins, Not Drawers Imagine throwing order slips into a big bin, rather than neatly organising them right away. Choose databases that handle high write throughput: ✅ PostgreSQL with partitioning ✅ MongoDB for flexible schemas ✅ Cassandra or DynamoDB for large-scale writes ✅ ClickHouse or InfluxDB for time-series or logs Avoid too much normalisation or constraints—they slow down writes. Step 3: Add a Queue at the Counter If users come in waves, you don't want to turn them away. Use message queues like: Kafka RabbitMQ Amazon SQS These act like waiting lines, temporarily holding data before it hits the database. Queues absorb spikes and make sure nothing gets lost. Step 4: Delay the Clean-Up Don't try to organise everything while you're slammed with orders. Instead: Write now Clean up later (during off-peak times) Use batch jobs or stream processing (e.g., Apache Spark, AWS Lambda) to: Summarise Archive Transform This keeps the system responsive during busy hours. Step 5: Add More Counters (Scale Horizontally) If one counter isn't enough, open more. That means: Sharding your database (split data across servers) Replicating writes to multiple nodes Using load balancers Scaling horizontally helps maintain performance as load increases. Step 6: Prefer Logs Over Rewrites Instead of updating the same data repeatedly, log every change. Benefits: Faster writes Easy rollback or reprocessing Clear audit trail Log-based architectures (event sourcing, write-ahead logs) are great for write-heavy use cases. Step 7: Always Save a Timestamp Add a created_at or written_at field to every piece of data. It helps you: Order events Debug issues Run analytics later Timestamps are simple but powerful. Bonus: What to Avoid in Write-Heavy Systems ❌ Heavy indexing on every field (slows down inserts) ❌ Complex joins on write paths ❌ Overuse of transactions ❌ Writing and reading from the same table at the same time without planning TL;DR – Your Write-Heavy System Design Checklist Step Action 1️⃣ Understand your data types and write frequency 2️⃣ Choose a write-optimized database 3️⃣ Add message queues to absorb spikes 4️⃣ Delay processing with batch jobs 5️⃣ Scale horizontally (shards, replicas) 6️⃣ Log all writes instead of overwriting 7️⃣ Add timestamps to every write Building a system that handles tons of data? Save this post NOW and share it with your team—because your next app deserves to scale from Day 1.
When designing a system that handles a lot of incoming data—like transactions, logs, messages or orders—your priority is not reading that data, but writing it fast and efficiently. These systems are called write-heavy systems.
This guide breaks down the process in a way that anyone can understand, with an analogy that sticks. Whether you're a beginner building your first backend or a seasoned engineer setting up a scalable pipeline, this is your go-to checklist.
Imagine Your System is an Ice Cream Shop
In our analogy:
Customers = users
Orders = write operations (inserts/updates)
Menu views = read operations (queries)
In a write-heavy system, people are mostly placing orders—not just browsing the menu.
Let's walk through how to set up a system that can take those orders quickly and reliably.
Step 1: Understand What You're Handling
Before choosing databases or tech stacks, ask yourself:
What kind of data is being written? (e.g., chat messages, transactions, logs)
How frequently is data written?
Do you need to store it forever or just for a short time?
This helps you define the structure and volume of your database.
Step 2: Use Bins, Not Drawers
Imagine throwing order slips into a big bin, rather than neatly organising them right away.
Choose databases that handle high write throughput:
✅ PostgreSQL with partitioning
✅ MongoDB for flexible schemas
✅ Cassandra or DynamoDB for large-scale writes
✅ ClickHouse or InfluxDB for time-series or logs
Avoid too much normalisation or constraints—they slow down writes.
Step 3: Add a Queue at the Counter
If users come in waves, you don't want to turn them away.
Use message queues like:
Kafka
RabbitMQ
Amazon SQS
These act like waiting lines, temporarily holding data before it hits the database. Queues absorb spikes and make sure nothing gets lost.
Step 4: Delay the Clean-Up
Don't try to organise everything while you're slammed with orders.
Instead:
Write now
Clean up later (during off-peak times)
Use batch jobs or stream processing (e.g., Apache Spark, AWS Lambda) to:
Summarise
Archive
Transform
This keeps the system responsive during busy hours.
Step 5: Add More Counters (Scale Horizontally)
If one counter isn't enough, open more.
That means:
Sharding your database (split data across servers)
Replicating writes to multiple nodes
Using load balancers
Scaling horizontally helps maintain performance as load increases.
Step 6: Prefer Logs Over Rewrites
Instead of updating the same data repeatedly, log every change.
Benefits:
Faster writes
Easy rollback or reprocessing
Clear audit trail
Log-based architectures (event sourcing, write-ahead logs) are great for write-heavy use cases.
Step 7: Always Save a Timestamp
Add a created_at or written_at field to every piece of data.
It helps you:
Order events
Debug issues
Run analytics later
Timestamps are simple but powerful.
Bonus: What to Avoid in Write-Heavy Systems
❌ Heavy indexing on every field (slows down inserts)
❌ Complex joins on write paths
❌ Overuse of transactions
❌ Writing and reading from the same table at the same time without planning
TL;DR – Your Write-Heavy System Design Checklist
Step Action
1️⃣ Understand your data types and write frequency
2️⃣ Choose a write-optimized database
3️⃣ Add message queues to absorb spikes
4️⃣ Delay processing with batch jobs
5️⃣ Scale horizontally (shards, replicas)
6️⃣ Log all writes instead of overwriting
7️⃣ Add timestamps to every write
Building a system that handles tons of data?
Save this post NOW and share it with your team—because your next app deserves to scale from Day 1.