














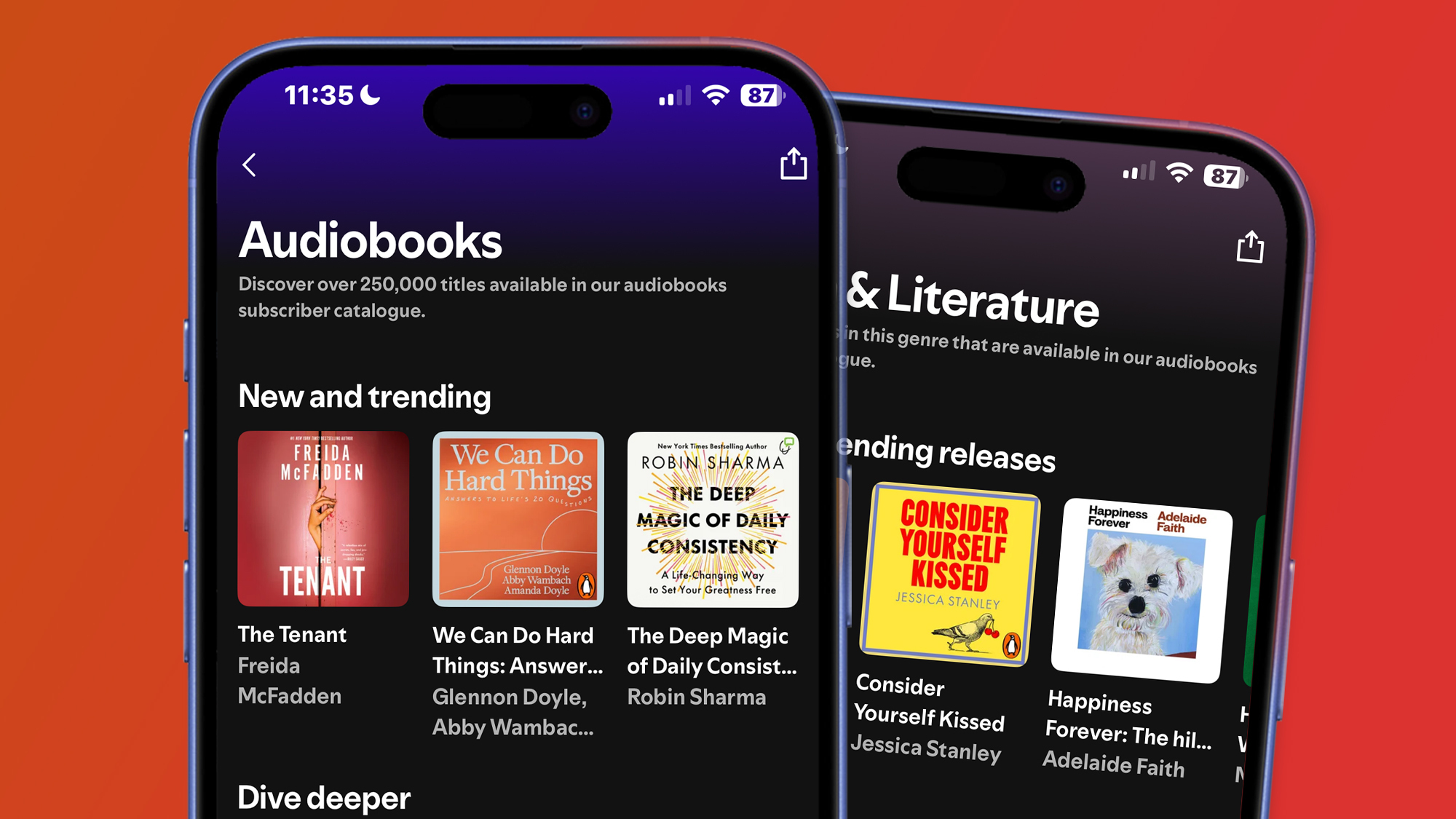























































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)




























































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)


















































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



















_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![Apple iPhone Exports From India Surge 116% [Report]](https://www.iclarified.com/images/news/97292/97292/97292-640.jpg)
![Apple Shares 'Last Scene' Short Film Shot on iPhone 16 Pro [Video]](https://www.iclarified.com/images/news/97289/97289/97289-640.jpg)
![Apple M4 MacBook Air Hits New All-Time Low of $824 [Deal]](https://www.iclarified.com/images/news/97288/97288/97288-640.jpg)
![An Apple Product Renaissance Is on the Way [Gurman]](https://www.iclarified.com/images/news/97286/97286/97286-640.jpg)










































![Gurman: First Foldable iPhone 'Should Be on the Market by 2027' [Updated]](https://images.macrumors.com/t/7O_4ilWjMpNSXf1pIBM37P_dKgU=/2500x/article-new/2025/03/Foldable-iPhone-2023-Feature-Homescreen.jpg)


















































Fine-Tune SLMs in Colab for Free : A 4-Bit Approach with Meta Llama 3.2
Fine-tuning large language models (LLMs) sounds complex — until you meet Unsloth. Whether you’re a complete beginner or an experienced ML tinkerer, this guide walks you through the simplest and most efficient way to fine-tune LLaMA models on free GPUs using Google Colab. Best of all? No fancy hardware or deep ML theory required. This article breaks down every keyword, library, and function, defining each term precisely but in the simplest language possible. In this article, you’ll learn how to: Install and configure Unsloth in Colab Load models in quantized (4-bit) mode to save memory Understand core concepts (parameters, weights, biases, quantization, etc.) Apply PEFT and LoRA adapters to fine-tune only a small part of the model Prepare Q&A data for training with Hugging Face Datasets and chat templates Use SFTTrainer for supervised fine-tuning Switch to inference mode for faster generation Save and reload your fine-tuned model Getting Comfortable With some Core Concepts **Disclaimer: I promise this will be the friendliest GenAI glossary — your cheat sheet, wittier than autocorrect and way less judgmental!

Fine-tuning large language models (LLMs) sounds complex — until you meet Unsloth. Whether you’re a complete beginner or an experienced ML tinkerer, this guide walks you through the simplest and most efficient way to fine-tune LLaMA models on free GPUs using Google Colab. Best of all? No fancy hardware or deep ML theory required.
This article breaks down every keyword, library, and function, defining each term precisely but in the simplest language possible.
In this article, you’ll learn how to:
- Install and configure Unsloth in Colab
- Load models in quantized (4-bit) mode to save memory
- Understand core concepts (parameters, weights, biases, quantization, etc.)
- Apply PEFT and LoRA adapters to fine-tune only a small part of the model
- Prepare Q&A data for training with Hugging Face Datasets and chat templates
- Use SFTTrainer for supervised fine-tuning
- Switch to inference mode for faster generation
- Save and reload your fine-tuned model
Getting Comfortable With some Core Concepts

**Disclaimer: I promise this will be the friendliest GenAI glossary — your cheat sheet, wittier than autocorrect and way less judgmental!



