











































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)

























































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)











































.jpeg?#)
.jpg?#)
























































































_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![Apple Shares New 'Mac to School' Ads: Pointed, Mirrored, Dropped In [Video]](https://www.iclarified.com/images/news/97295/97295/97295-640.jpg)
![Apple Drops New Trailer for 'F1' Starring Brad Pitt [Video]](https://www.iclarified.com/images/news/97296/97296/97296-640.jpg)
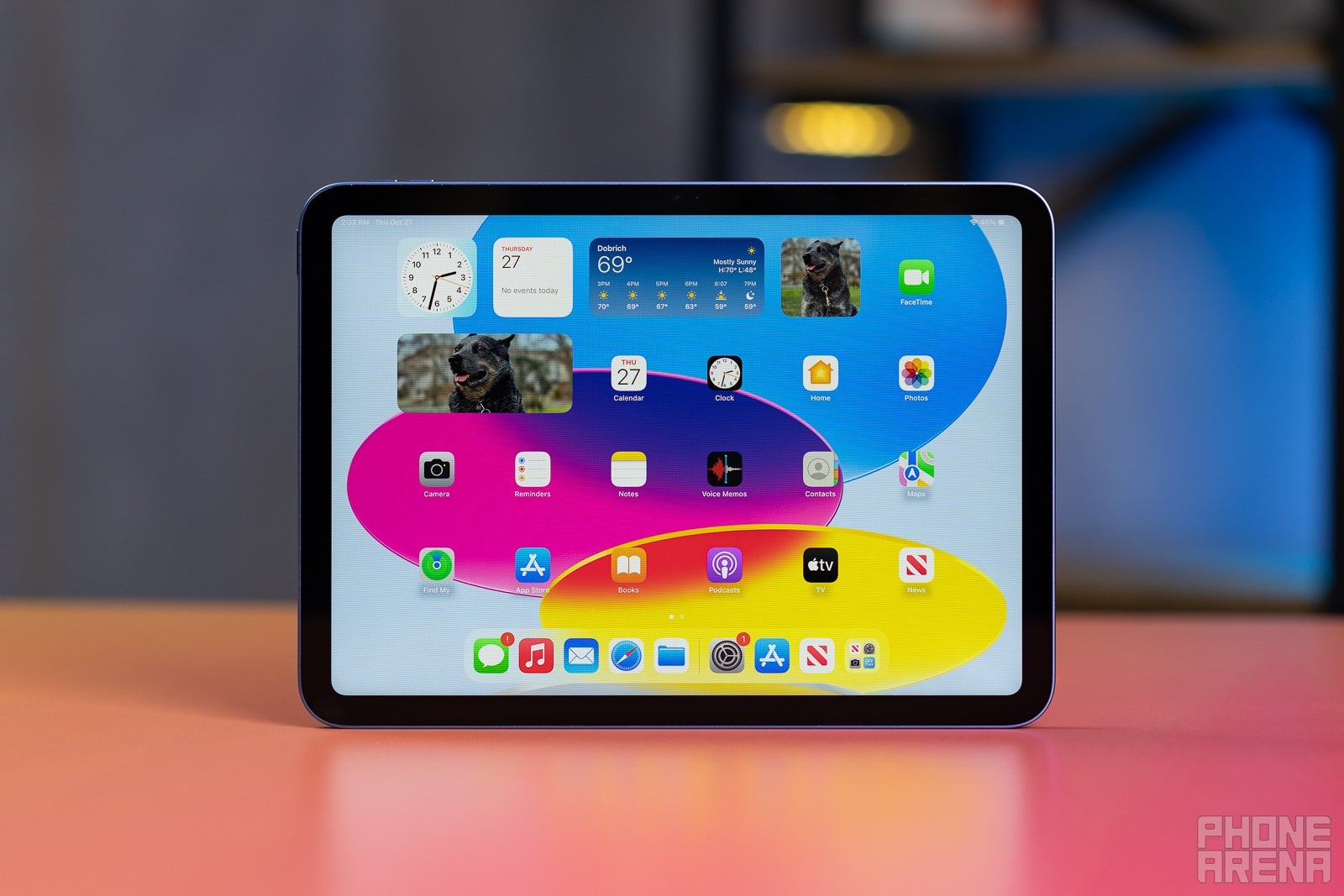
![Apple iPhone Exports From India Surge 116% [Report]](https://www.iclarified.com/images/news/97292/97292/97292-640.jpg)
![Apple Shares 'Last Scene' Short Film Shot on iPhone 16 Pro [Video]](https://www.iclarified.com/images/news/97289/97289/97289-640.jpg)



























































































Quarkus 3 application on AWS Lambda- Part 2 Reducing Lambda cold starts with Lambda SnapStart
Introduction In the part 1 of our series about how to develop, run and optimize Quarkus web application on AWS Lambda, we demonstrated how to write a sample application which uses the Quarkus framework, AWS Lambda, Amazon API Gateway and Amazon DynamoDB. We also made the first Lambda performance (cold and warm start time) measurements and observed quite a big cold start time. In the next parts of the series we'll introduce Lambda SnapStart and measure how it reduces the Lambda cold start time. Sample application with the activated AWS Lambda SnapStart without using priming We'll re-use the same sample application introduced in the part 1 of our series. As we saw in part 1, without any optimizations, Lamdba performance measurements showed quite high values, especially for the cold start times. Lambda SnapStart is one of the optimization approaches to reduce the cold start times. Lambda SnapStart can provide a start time of a lambda function of less than one second. SnapStart simplifies the development of responsive and scalable applications without provisioning resources or implementing complex performance optimizations. The largest portion of startup latency (often referred to as cold start time) is the time Lambda spends initializing the function, which includes loading the function code, starting the runtime and initialising the function code. With SnapStart, Lambda initializes our function when we publish a function version. Lambda takes a Firecracker microVM snapshot of the memory and disk state of the initialised execution environment, encrypts the snapshot and intelligently caches it to optimize retrieval latency. To ensure reliability, Lambda manages multiple copies of each snapshot. Lambda automatically patches snapshots and their copies with the latest runtime and security updates. When we call the function version for the first time and as the calls increase, Lambda continues new execution environments from the cached snapshot instead of initialising them from scratch, which improves startup latency. More information can be found in the article Reducing Java cold starts on AWS Lambda functions with SnapStart. I have published the whole series about Lambda SnapStart for Java applications. To activate Lambda SnapStart, we have to do the following in template.yaml for the Lambda function: Globals: Function: Handler: io.quarkus.amazon.lambda.runtime.QuarkusStreamHandler::handleRequest CodeUri: target/function.zip Runtime: java21 SnapStart: ApplyOn: PublishedVersions .... This can be done in the globals section of the Lambda functions, in which case SnapStart applies to all Lambda functions defined in the AWS SAM template, or you can add the 2 lines SnapStart: ApplyOn: PublishedVersions to activate SnapStart only for the individual Lambda function. To perform the performance measurement without priming techniques, as we will introduce in methods 3 and 4, please either comment out or remove @startup annotation in the following 2 Java classes AmazonDynamoDBPrimingResource and AmazonAPIGatewayPrimingResource . Measurements of cold and warm start times of our application with Lambda SnapStart In the following, we will measure the performance of our GetProductByIdFunction Lambda function, which we will trigger by invoking curl -H "X-API-Key: a6ZbcDefQW12BN56WEV318" https://{$API_GATEWAY_URL}/prod/products/1. Two aspects are important to us in terms of performance: cold and warm start times. It is known that Java applications in particular have a very high cold start time. The article Understanding the Lambda execution environment lifecycle provides a good overview of this topic. The results of the experiment are based on reproducing more than 100 cold starts and about 100,000 warm starts with the Lambda function GetProductByIdFunction (we ask for the already existing product with ID=1 ) for the duration of about 1 hour. We give Lambda function 1024 MB memory, which is a good trade-off between performance and cost. We also use (default) x86 Lambda architecture. For the load tests I used the load test tool hey, but you can use whatever tool you want, like Serverless-artillery or Postman. We will measure with tiered compilation (which is default in Java 21, we don't need to set anything separately) and compilation option XX:+TieredCompilation -XX:TieredStopAtLevel=1. To use the last option, you have to set it in template.yaml in JAVA_OPTIONS environment variable as follows: Globals: Function: Handler: io.quarkus.amazon.lambda.runtime.QuarkusStreamHandler::handleRequest ... Environment: Variables: JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=1" Please also note the effect of the AWS SnapStart Snapshot tiered cache. This means that in the case of SnapStart activation, we get the largest cold starts during the first measurements. Due to the tiered cache, the subseq

Introduction
In the part 1 of our series about how to develop, run and optimize Quarkus web application on AWS Lambda, we demonstrated how to write a sample application which uses the Quarkus framework, AWS Lambda, Amazon API Gateway and Amazon DynamoDB. We also made the first Lambda performance (cold and warm start time) measurements and observed quite a big cold start time. In the next parts of the series we'll introduce Lambda SnapStart and measure how it reduces the Lambda cold start time.
Sample application with the activated AWS Lambda SnapStart without using priming
We'll re-use the same sample application introduced in the part 1 of our series.
As we saw in part 1, without any optimizations, Lamdba performance measurements showed quite high values, especially for the cold start times. Lambda SnapStart is one of the optimization approaches to reduce the cold start times.
Lambda SnapStart can provide a start time of a lambda function of less than one second. SnapStart simplifies the development of responsive and scalable applications without provisioning resources or implementing complex performance optimizations.
The largest portion of startup latency (often referred to as cold start time) is the time Lambda spends initializing the function, which includes loading the function code, starting the runtime and initialising the function code. With SnapStart, Lambda initializes our function when we publish a function version. Lambda takes a Firecracker microVM snapshot of the memory and disk state of the initialised execution environment, encrypts the snapshot and intelligently caches it to optimize retrieval latency.
To ensure reliability, Lambda manages multiple copies of each snapshot. Lambda automatically patches snapshots and their copies with the latest runtime and security updates. When we call the function version for the first time and as the calls increase, Lambda continues new execution environments from the cached snapshot instead of initialising them from scratch, which improves startup latency. More information can be found in the article Reducing Java cold starts on AWS Lambda functions with SnapStart. I have published the whole series about Lambda SnapStart for Java applications.
To activate Lambda SnapStart, we have to do the following in template.yaml for the Lambda function:
Globals:
Function:
Handler: io.quarkus.amazon.lambda.runtime.QuarkusStreamHandler::handleRequest
CodeUri: target/function.zip
Runtime: java21
SnapStart:
ApplyOn: PublishedVersions
....
This can be done in the globals section of the Lambda functions, in which case SnapStart applies to all Lambda functions defined in the AWS SAM template, or you can add the 2 lines
SnapStart:
ApplyOn: PublishedVersions
to activate SnapStart only for the individual Lambda function. To perform the performance measurement without priming techniques, as we will introduce in methods 3 and 4, please either comment out or remove @startup annotation in the following 2 Java classes AmazonDynamoDBPrimingResource and AmazonAPIGatewayPrimingResource .
Measurements of cold and warm start times of our application with Lambda SnapStart
In the following, we will measure the performance of our GetProductByIdFunction Lambda function, which we will trigger by invoking curl -H "X-API-Key: a6ZbcDefQW12BN56WEV318" https://{$API_GATEWAY_URL}/prod/products/1. Two aspects are important to us in terms of performance: cold and warm start times. It is known that Java applications in particular have a very high cold start time. The article Understanding the Lambda execution environment lifecycle provides a good overview of this topic.
The results of the experiment are based on reproducing more than 100 cold starts and about 100,000 warm starts with the Lambda function GetProductByIdFunction (we ask for the already existing product with ID=1 ) for the duration of about 1 hour. We give Lambda function 1024 MB memory, which is a good trade-off between performance and cost. We also use (default) x86 Lambda architecture. For the load tests I used the load test tool hey, but you can use whatever tool you want, like Serverless-artillery or Postman.
We will measure with tiered compilation (which is default in Java 21, we don't need to set anything separately) and compilation option XX:+TieredCompilation -XX:TieredStopAtLevel=1. To use the last option, you have to set it in template.yaml in JAVA_OPTIONS environment variable as follows:
Globals:
Function:
Handler: io.quarkus.amazon.lambda.runtime.QuarkusStreamHandler::handleRequest
...
Environment:
Variables:
JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=1"
Please also note the effect of the AWS SnapStart Snapshot tiered cache. This means that in the case of SnapStart activation, we get the largest cold starts during the first measurements. Due to the tiered cache, the subsequent cold starts will have lower values. For more details about the technical implementation of AWS SnapStart and its tiered cache, I refer you to the presentation by Mike Danilov: "AWS Lambda Under the Hood". Therefore, I will present the Lambda performance measurements with SnapStart being activated for all approx. 100 cold start times (labelled as all in the table), but also for the last approx. 70 (labelled as last 70 in the table), so that the effect of Snapshot Tiered Cache becomes visible to you. Depending on how often the respective Lambda function is updated and thus some layers of the cache are invalidated, a Lambda function can experience thousands or tens of thousands of cold starts during its life cycle, so that the first longer lasting cold starts no longer carry much weight.
To show the impact of the SnapStart, we'll also present the Lambda performance measurements without SnapStart being activated from the part 1 .
Cold (c) and warm (w) start time with tiered compilation in ms:
| Scenario Number | c p50 | c p75 | c p90 | c p99 | c p99.9 | c max | w p50 | w p75 | w p90 | w p99 | w p99.9 | w max |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No SnapStart enabled | 3344 | 3422 | 3494 | 3633 | 3904 | 3907 | 5.92 | 6.83 | 8.00 | 19.46 | 50.44 | 1233 |
| SnapStart enabled but no priming applied, all | 1643 | 1703 | 1953 | 2007 | 2084 | 2084 | 5.68 | 6.35 | 7.39 | 16.39 | 49.23 | 1386 |
| SnapStart enabled but no priming applied, last 70 | 1604 | 1664 | 1728 | 1798 | 1798 | 1798 | 5.64 | 6.30 | 7.33 | 15.87 | 47.30 | 1286 |
Cold (c) and warm (w) start time with -XX:+TieredCompilation -XX:TieredStopAtLevel=1 compilation in ms:
| Scenario Number | c p50 | c p75 | c p90 | c p99 | c p99.9 | c max | w p50 | w p75 | w p90 | w p99 | w p99.9 | w max |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No SnapStart enabled | 3357 | 3456 | 3554 | 4039 | 4060 | 4060 | 6.01 | 6.83 | 8.13 | 19.77 | 53.74 | 1314 |
| SnapStart enabled but no priming applied, all | 1593 | 1625 | 1722 | 1834 | 1930 | 1930 | 5.55 | 6.21 | 7.16 | 16.08 | 50.44 | 1401 |
| SnapStart enabled but no priming applied, last 70 | 1574 | 1621 | 1685 | 1801 | 1801 | 1801 | 5.55 | 6.20 | 7.16 | 15.14 | 49.23 | 1401 |
Conclusion
In this part of the series, we introduced Lambda SnapStart and measured how its enabling reduces the Lambda cold start time by more than 50%. We also clearly observed the impact of the AWS SnapStart Snapshot tiered cache in our measurements.
In the part of our article series, we'll introduce how to apply Lambda SnapStart priming techniques by starting with DynamoDB request priming with the goal to even further improve the performance of our Lambda functions.


