








































































































































































![[The AI Show Episode 147]: OpenAI Abandons For-Profit Plan, AI College Cheating Epidemic, Apple Says AI Will Replace Search Engines & HubSpot’s AI-First Scorecard](https://www.marketingaiinstitute.com/hubfs/ep%20147%20cover.png)

























![How to Enable Remote Access on Windows 10 [Allow RDP]](https://bigdataanalyticsnews.com/wp-content/uploads/2025/05/remote-access-windows.jpg)





































































































































































































































_Dzmitry_Skazau_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


-Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



.webp?#)









































































-xl.jpg)





























![Sony WH-1000XM6 Unveiled With Smarter Noise Canceling and Studio-Tuned Sound [Video]](https://www.iclarified.com/images/news/97341/97341/97341-640.jpg)


![Watch Aston Martin and Top Gear Show Off Apple CarPlay Ultra [Video]](https://www.iclarified.com/images/news/97336/97336/97336-640.jpg)








































![Apple Slaps Warnings on Apps Using External Purchases in the EU [Updated]](https://images.macrumors.com/t/Zy0e-JLM0fNyngEYaXu5rMH1lJk=/1920x/article-new/2025/05/app-store-external-payments-warning.jpg)






















































Exploring Amazon Redshift System Tables: A Guide to Key Queries
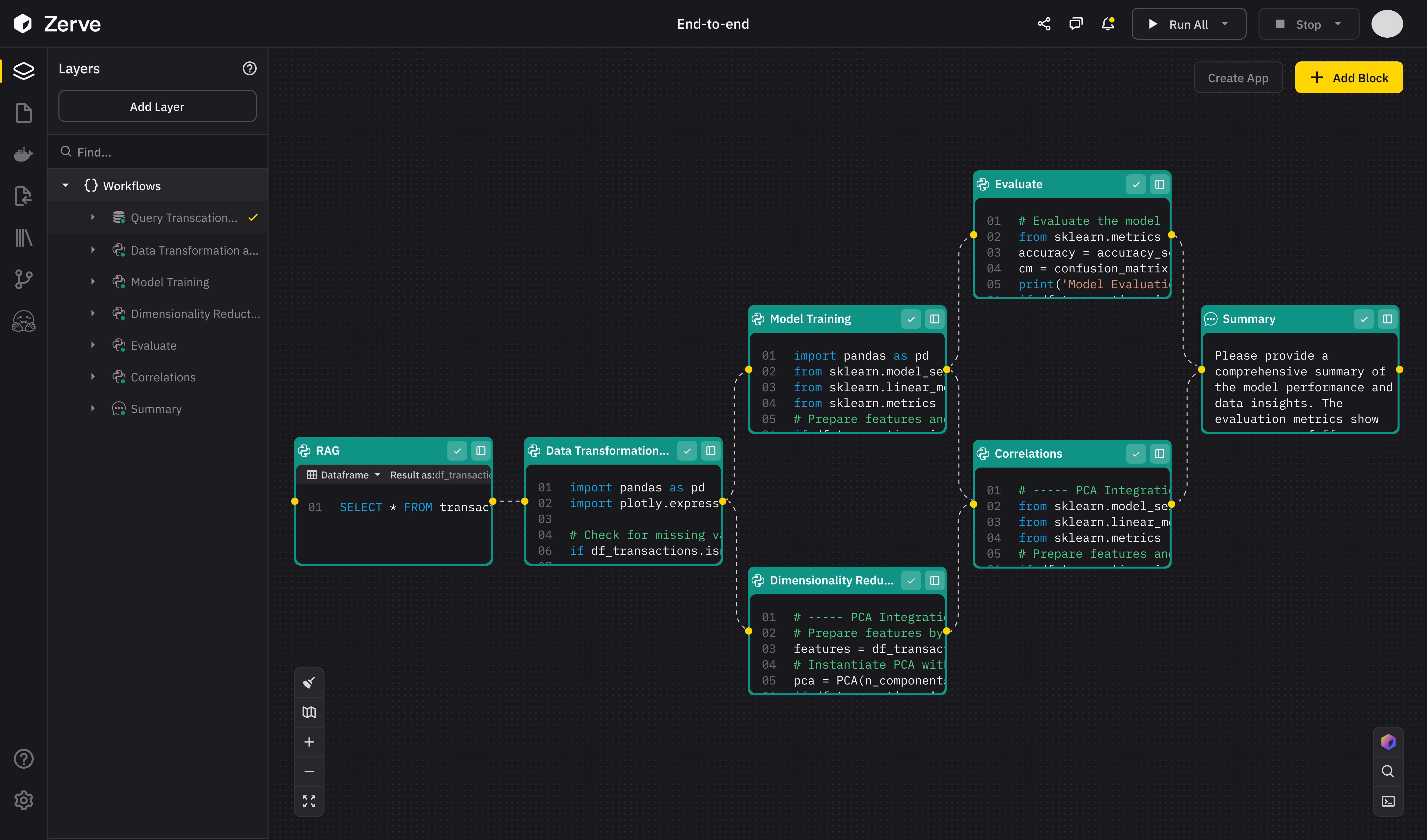
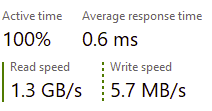
Amazon Redshift is a powerful data warehouse solution, and its system tables (stl_*, svl_*, and svv_*) provide a treasure trove of metadata and performance insights. Whether you're troubleshooting query performance, auditing user activity, or optimizing workload management, these system tables are your go-to tools. In this blog, we’ll dive into eight essential Redshift system table queries, explaining what they do, why they’re useful, and when to use them. Let’s get started! 1. Inspecting Table Metadata Query: SELECT * FROM svv_table_info WHERE "table" = ''; What It Does: This query retrieves detailed metadata about a specific table, in this case, , from the svv_table_info system view. Why It’s Useful: Provides insights into table properties like size (in MB), row count, distribution style, and sort keys. Helps identify storage issues, such as high disk usage or data skew. Essential for optimizing table design (e.g., choosing better sort or distribution keys). When to Use: When auditing table storage or diagnosing performance issues. To verify table configurations before running large queries. Key Output Columns: database, schema, table, size, pct_used, diststyle, sortkey. 2. Auditing Query History Query: SELECT * FROM stl_query WHERE userid > 1 ORDER BY starttime DESC; What It Does: Fetches details about queries executed by users (excluding system queries) from the stl_query table, sorted by start time in descending order. Why It’s Useful: Tracks what queries users are running and when. Helps debug failed or slow queries by reviewing query text and execution status. Useful for auditing user activity on the cluster. When to Use: To investigate recent query activity or troubleshoot errors. When monitoring user behavior or ensuring compliance. Key Output Columns: query, userid, starttime, endtime, querytxt, aborted. 3. Analyzing Table Scans Query: SELECT * FROM stl_scan WHERE query = 1222336; What It Does: Retrieves information about table scan operations for a specific query (ID: 1222336) from the stl_scan table. Why It’s Useful: Shows which tables were scanned and the type of scan (e.g., sequential or index-based). Helps identify performance bottlenecks caused by full table scans. Provides row and byte counts for scans, aiding in I/O analysis. When to Use: When optimizing query performance by reducing unnecessary scans. To diagnose high disk I/O for a specific query. Key Output Columns: query, segment, step, table_id, rows, bytes. 4. Deep-Diving into Query Metrics Query: SELECT * FROM svl_query_metrics WHERE query = 1222336; What It Does: Pulls granular performance metrics for a specific query (ID: 1222336) from the svl_query_metrics view, broken down by segment and step. Why It’s Useful: Offers detailed insights into CPU usage, disk I/O, memory consumption, and more. Pinpoints resource-intensive steps in a query’s execution plan. Critical for fine-tuning complex queries. When to Use: When troubleshooting slow or resource-heavy queries. To understand query execution at a low level for optimization. Key Output Columns: query, segment, step, cpu_time, rows, bytes, memory. 5. Summarizing Query Performance Query: SELECT * FROM svl_query_metrics_summary WHERE query = 1222336; What It Does: Provides a high-level summary of performance metrics for a specific query (ID: 1222336) from the svl_query_metrics_summary view. Why It’s Useful: Aggregates metrics like total execution time, rows processed, and resource usage. Offers a quick snapshot of query performance without granular details. Great for comparing query efficiency across runs. When to Use: When you need a concise overview of a query’s performance. To identify resource-intensive queries at a glance. Key Output Columns: query, exec_time, rows, bytes, cpu_time, memory. 6. Checking Query Compilation Query: SELECT * FROM svl_compile WHERE query = 1222336; What It Does: Retrieves compilation details for a specific query (ID: 1222336) from the svl_compile view. Why It’s Useful: Shows whether a query was compiled or reused from the cache. Helps diagnose performance issues related to compilation overhead. Useful for understanding query plan generation. When to Use: When investigating slow query startup times. To optimize query caching strategies. Key Output Columns: query, nodeid, compile, starttime, endtime. 7. Monitoring Workload Management Query: SELECT * FROM stl_wlm_query WHERE query = 1222336; What It Does: Fetches Workload Management (WLM) details for a specific query (ID: 1222336) from the stl_wlm_query table. Why It’s Useful: Shows queue wait times, execution times, and WLM queue assignments. Helps identify queries delayed or throttled by WLM rules. Critical for tuning WLM configurations to prioritize important queries. When to Use:

Amazon Redshift is a powerful data warehouse solution, and its system tables (stl_*, svl_*, and svv_*) provide a treasure trove of metadata and performance insights. Whether you're troubleshooting query performance, auditing user activity, or optimizing workload management, these system tables are your go-to tools. In this blog, we’ll dive into eight essential Redshift system table queries, explaining what they do, why they’re useful, and when to use them. Let’s get started!
1. Inspecting Table Metadata
Query:
SELECT * FROM svv_table_info WHERE "table" = '' ;
What It Does: This query retrieves detailed metadata about a specific table, in this case, svv_table_info system view.
Why It’s Useful:
- Provides insights into table properties like size (in MB), row count, distribution style, and sort keys.
- Helps identify storage issues, such as high disk usage or data skew.
- Essential for optimizing table design (e.g., choosing better sort or distribution keys).
When to Use:
- When auditing table storage or diagnosing performance issues.
- To verify table configurations before running large queries.
Key Output Columns: database, schema, table, size, pct_used, diststyle, sortkey.
2. Auditing Query History
Query:
SELECT * FROM stl_query WHERE userid > 1 ORDER BY starttime DESC;
What It Does: Fetches details about queries executed by users (excluding system queries) from the stl_query table, sorted by start time in descending order.
Why It’s Useful:
- Tracks what queries users are running and when.
- Helps debug failed or slow queries by reviewing query text and execution status.
- Useful for auditing user activity on the cluster.
When to Use:
- To investigate recent query activity or troubleshoot errors.
- When monitoring user behavior or ensuring compliance.
Key Output Columns: query, userid, starttime, endtime, querytxt, aborted.
3. Analyzing Table Scans
Query:
SELECT * FROM stl_scan WHERE query = 1222336;
What It Does: Retrieves information about table scan operations for a specific query (ID: 1222336) from the stl_scan table.
Why It’s Useful:
- Shows which tables were scanned and the type of scan (e.g., sequential or index-based).
- Helps identify performance bottlenecks caused by full table scans.
- Provides row and byte counts for scans, aiding in I/O analysis.
When to Use:
- When optimizing query performance by reducing unnecessary scans.
- To diagnose high disk I/O for a specific query.
Key Output Columns: query, segment, step, table_id, rows, bytes.
4. Deep-Diving into Query Metrics
Query:
SELECT * FROM svl_query_metrics WHERE query = 1222336;
What It Does: Pulls granular performance metrics for a specific query (ID: 1222336) from the svl_query_metrics view, broken down by segment and step.
Why It’s Useful:
- Offers detailed insights into CPU usage, disk I/O, memory consumption, and more.
- Pinpoints resource-intensive steps in a query’s execution plan.
- Critical for fine-tuning complex queries.
When to Use:
- When troubleshooting slow or resource-heavy queries.
- To understand query execution at a low level for optimization.
Key Output Columns: query, segment, step, cpu_time, rows, bytes, memory.
5. Summarizing Query Performance
Query:
SELECT * FROM svl_query_metrics_summary WHERE query = 1222336;
What It Does: Provides a high-level summary of performance metrics for a specific query (ID: 1222336) from the svl_query_metrics_summary view.
Why It’s Useful:
- Aggregates metrics like total execution time, rows processed, and resource usage.
- Offers a quick snapshot of query performance without granular details.
- Great for comparing query efficiency across runs.
When to Use:
- When you need a concise overview of a query’s performance.
- To identify resource-intensive queries at a glance.
Key Output Columns: query, exec_time, rows, bytes, cpu_time, memory.
6. Checking Query Compilation
Query:
SELECT * FROM svl_compile WHERE query = 1222336;
What It Does: Retrieves compilation details for a specific query (ID: 1222336) from the svl_compile view.
Why It’s Useful:
- Shows whether a query was compiled or reused from the cache.
- Helps diagnose performance issues related to compilation overhead.
- Useful for understanding query plan generation.
When to Use:
- When investigating slow query startup times.
- To optimize query caching strategies.
Key Output Columns: query, nodeid, compile, starttime, endtime.
7. Monitoring Workload Management
Query:
SELECT * FROM stl_wlm_query WHERE query = 1222336;
What It Does: Fetches Workload Management (WLM) details for a specific query (ID: 1222336) from the stl_wlm_query table.
Why It’s Useful:
- Shows queue wait times, execution times, and WLM queue assignments.
- Helps identify queries delayed or throttled by WLM rules.
- Critical for tuning WLM configurations to prioritize important queries.
When to Use:
- When troubleshooting query delays due to WLM queues.
- To optimize WLM settings for better performance.
Key Output Columns: query, queue_start_time, exec_start_time, total_queue_time, total_exec_time.
8. Reviewing WLM Rules
Query:
SELECT * FROM stl_wlm_rule_action;
What It Does: Lists all configured WLM rule actions from the stl_wlm_rule_action table.
Why It’s Useful:
- Reveals actions like aborting queries, changing priorities, or logging based on WLM rules.
- Helps audit and troubleshoot WLM configurations.
- Ensures rules align with performance and governance goals.
When to Use:
- When reviewing WLM rule setups.
- To debug unexpected query behavior caused by WLM actions.
Key Output Columns: rule, action, value, priority.
Practical Tips for Using These Queries
-
Permissions: Ensure you have access to system tables (
stl_*,svl_*,svv_*). Superusers typically have full access, but regular users may need explicit grants. -
Query IDs: Queries like those targeting
query = 1222336require a valid query ID, which you can find instl_queryor query logs. -
Performance Caution: Queries like
SELECT * FROM stl_querywithout filters can return large datasets. UseLIMITor specific filters to avoid performance hits. -
Combining Insights: For deep query optimization, combine
svl_query_metrics,stl_scan, andstl_wlm_queryto pinpoint bottlenecks in scans, resources, or queuing.
Conclusion
Amazon Redshift’s system tables are a goldmine for database administrators and data engineers. From inspecting table metadata to troubleshooting query performance and optimizing workload management, the queries above cover critical use cases. By mastering these, you can keep your Redshift cluster running smoothly and efficiently.
Have a favorite Redshift system table query or a performance tip? Share it in the comments! For more Redshift tips, stay tuned for our next post.
Published on May 16, 2025


