










































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)










































































































.jpg?#)

































_ArtemisDiana_Alamy.jpg?#)


 (1).webp?#)





































































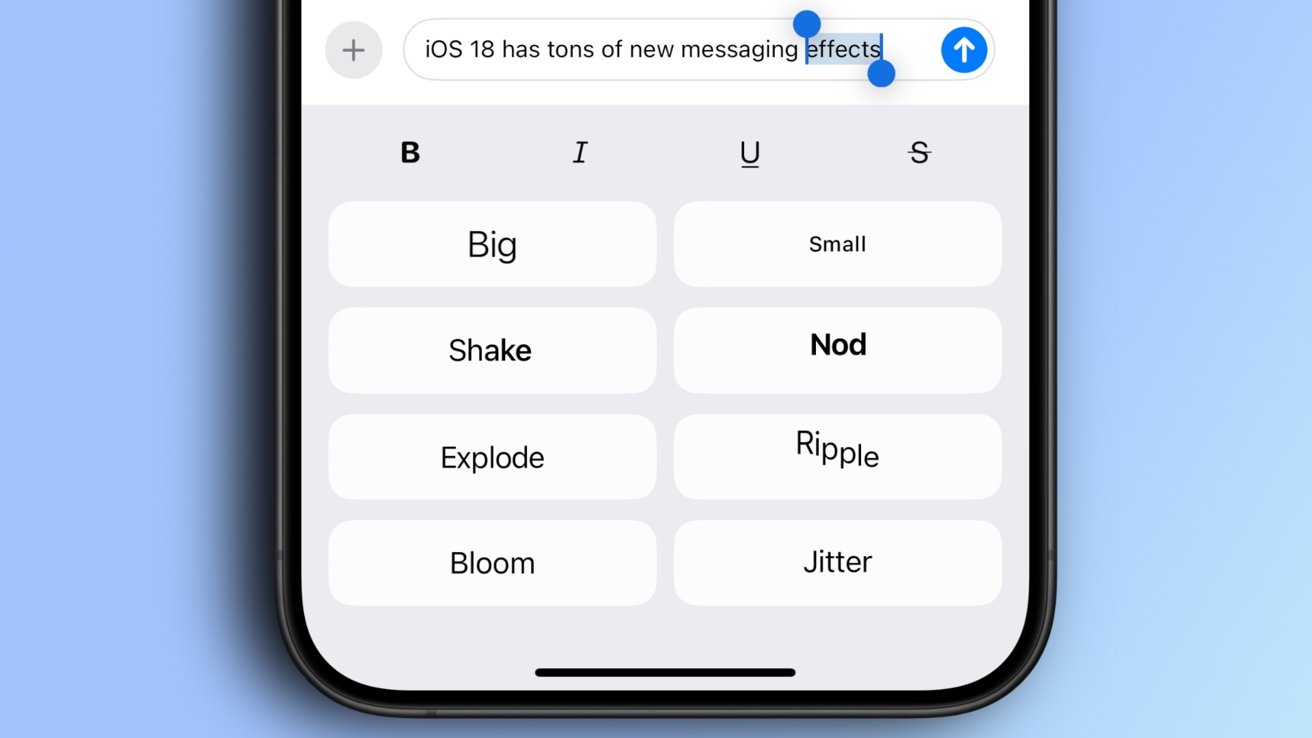
-xl.jpg)











![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)




























































































































Disaster Recovery on AWS - Part 1: Multi-Site Active/Active (EC2, ECS, Fargate)
Introduction What is the highest financial loss a company could face due to the absence of a Disaster Recovery (DR) setup? For enterprises, this could amount to millions, depending on their Recovery Time Objective (RTO) and Recovery Point Objective (RPO). Disaster Recovery is not just an IT concern—it is a business necessity. Organizations must prioritize DR to ensure business continuity and mitigate risks associated with data loss, cyber-attacks, and natural disasters. A lack of a DR strategy can lead to severe financial and reputational damage. What is Disaster Recovery? Disaster Recovery (DR) is a strategic framework and set of processes designed to restore IT systems, applications, and data in the event of disruptions. DR ensures business continuity by minimizing downtime and data loss, leveraging backup strategies, failover mechanisms, and automated recovery processes. What is RTO (Recovery Time Objective)? RTO defines the maximum acceptable downtime for an application or system after a failure before it significantly impacts business operations. A lower RTO indicates a faster recovery time and typically requires more robust infrastructure and automation. What is RPO (Recovery Point Objective)? RPO refers to the maximum tolerable amount of data loss measured in time. It defines how frequently data backups should be performed to ensure minimal loss in case of a disaster. A lower RPO requires more frequent backups and robust data replication strategies. Why is Disaster Recovery Necessary Beyond Availability Zones? Each AWS region consists of multiple Availability Zones (AZs). While deploying applications across multiple AZs enhances high availability, it does not qualify as Disaster Recovery. A DR strategy extends beyond AZs to ensure resilience across multiple geographic regions. DR is a critical component of IT General Controls (ITGCs), supporting the reliability of financial applications and compliance with regulatory standards. ITGCs encompass data backup, recovery, system availability, and change management. Audit departments and external firms assess these controls to ensure an organization's DR preparedness. Disaster Recovery Strategies Types of DR Strategies A well-architected DR strategy can be classified into different models based on business requirements: Backup & Restore: Cost-effective, but recovery time can be slow. Pilot Light: A minimal setup is always running, with additional resources scaled up during a disaster. Warm Standby: A scaled-down version of the environment runs continuously, allowing for quick recovery. Multi-Site Active/Active: Applications are deployed across multiple regions, distributing traffic dynamically to maintain availability and resilience. Architecture: Multi-Site Active/Active (EC2, ECS, Fargate) Architecture Flow: • Route 53: Global traffic routing across AWS regions. • Application Load Balancer (ALB): Distributes traffic to multiple regions. • Region 1 & Region 2: Active deployment of EC2, ECS, and Fargate to handle workloads. • Traffic Distribution: The percentage of traffic routed to each region can be defined based on business needs. (Arunkumar will attach Architecture Diagram here) Key Takeaways • DR is not optional – It is a fundamental requirement to ensure business continuity. • Faster Recovery: A well-defined RTO and RPO minimize downtime and data loss. • Cost Efficiency: A robust DR strategy helps reduce long-term operational costs by ensuring preparedness. • Automated Rollback & Testing: Regularly test and validate backups to ensure effective failover during disasters. Call to Action (CTA) Assess your DR strategy today. Ensure your backups, failover systems, and rollback processes are tested, automated, and ready for the unexpected. Define and review your RTO and RPO to align with business objectives. Conclusion Disaster Recovery is more than an IT requirement—it is a business-critical function. Organizations must proactively implement DR measures to avoid financial losses, maintain compliance, and ensure uninterrupted operations. Action Points: Implement robust backup and recovery procedures. Develop and maintain Business Continuity Plans. Regularly test and optimize DR plans to meet evolving business needs. A well-prepared DR strategy can mean the difference between business resilience and catastrophic failure. Start planning today to safeguard your enterprise’s future.
Introduction
What is the highest financial loss a company could face due to the absence of a Disaster Recovery (DR) setup? For enterprises, this could amount to millions, depending on their Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Disaster Recovery is not just an IT concern—it is a business necessity. Organizations must prioritize DR to ensure business continuity and mitigate risks associated with data loss, cyber-attacks, and natural disasters. A lack of a DR strategy can lead to severe financial and reputational damage.
What is Disaster Recovery?
Disaster Recovery (DR) is a strategic framework and set of processes designed to restore IT systems, applications, and data in the event of disruptions. DR ensures business continuity by minimizing downtime and data loss, leveraging backup strategies, failover mechanisms, and automated recovery processes.
What is RTO (Recovery Time Objective)?
RTO defines the maximum acceptable downtime for an application or system after a failure before it significantly impacts business operations. A lower RTO indicates a faster recovery time and typically requires more robust infrastructure and automation.
What is RPO (Recovery Point Objective)?
RPO refers to the maximum tolerable amount of data loss measured in time. It defines how frequently data backups should be performed to ensure minimal loss in case of a disaster. A lower RPO requires more frequent backups and robust data replication strategies.
Why is Disaster Recovery Necessary Beyond Availability Zones?
Each AWS region consists of multiple Availability Zones (AZs). While deploying applications across multiple AZs enhances high availability, it does not qualify as Disaster Recovery. A DR strategy extends beyond AZs to ensure resilience across multiple geographic regions. DR is a critical component of IT General Controls (ITGCs), supporting the reliability of financial applications and compliance with regulatory standards. ITGCs encompass data backup, recovery, system availability, and change management. Audit departments and external firms assess these controls to ensure an organization's DR preparedness.
Disaster Recovery Strategies
Types of DR Strategies
A well-architected DR strategy can be classified into different models based on business requirements:
- Backup & Restore: Cost-effective, but recovery time can be slow.
- Pilot Light: A minimal setup is always running, with additional resources scaled up during a disaster.
- Warm Standby: A scaled-down version of the environment runs continuously, allowing for quick recovery.
- Multi-Site Active/Active: Applications are deployed across multiple regions, distributing traffic dynamically to maintain availability and resilience.
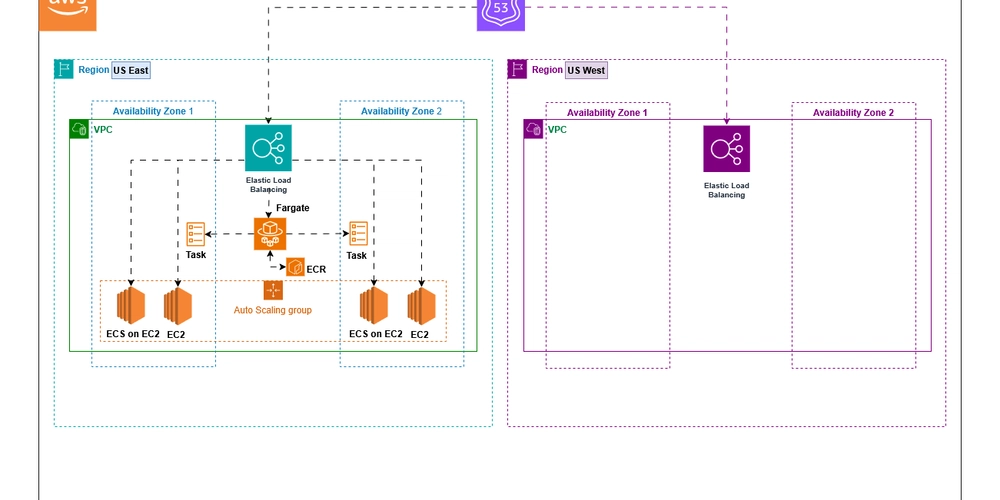
Architecture: Multi-Site Active/Active (EC2, ECS, Fargate)
Architecture Flow:
• Route 53: Global traffic routing across AWS regions.
• Application Load Balancer (ALB): Distributes traffic to multiple regions.
• Region 1 & Region 2: Active deployment of EC2, ECS, and Fargate to handle workloads.
• Traffic Distribution: The percentage of traffic routed to each region can be defined based on business needs.
(Arunkumar will attach Architecture Diagram here)
Key Takeaways
• DR is not optional – It is a fundamental requirement to ensure business continuity.
• Faster Recovery: A well-defined RTO and RPO minimize downtime and data loss.
• Cost Efficiency: A robust DR strategy helps reduce long-term operational costs by ensuring preparedness.
• Automated Rollback & Testing: Regularly test and validate backups to ensure effective failover during disasters.
Call to Action (CTA)
Assess your DR strategy today. Ensure your backups, failover systems, and rollback processes are tested, automated, and ready for the unexpected. Define and review your RTO and RPO to align with business objectives.
Conclusion
Disaster Recovery is more than an IT requirement—it is a business-critical function. Organizations must proactively implement DR measures to avoid financial losses, maintain compliance, and ensure uninterrupted operations.
Action Points:
- Implement robust backup and recovery procedures.
- Develop and maintain Business Continuity Plans.
- Regularly test and optimize DR plans to meet evolving business needs. A well-prepared DR strategy can mean the difference between business resilience and catastrophic failure. Start planning today to safeguard your enterprise’s future.


