






































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)















































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























































































_Steven_Jones_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)





































































































![Google Mocks Rumored 'iPhone 17 Air' Design in New Pixel Ad [Video]](https://www.iclarified.com/images/news/97224/97224/97224-640.jpg)

![Apple Shares Official Teaser for 'Highest 2 Lowest' Starring Denzel Washington [Video]](https://www.iclarified.com/images/news/97221/97221/97221-640.jpg)












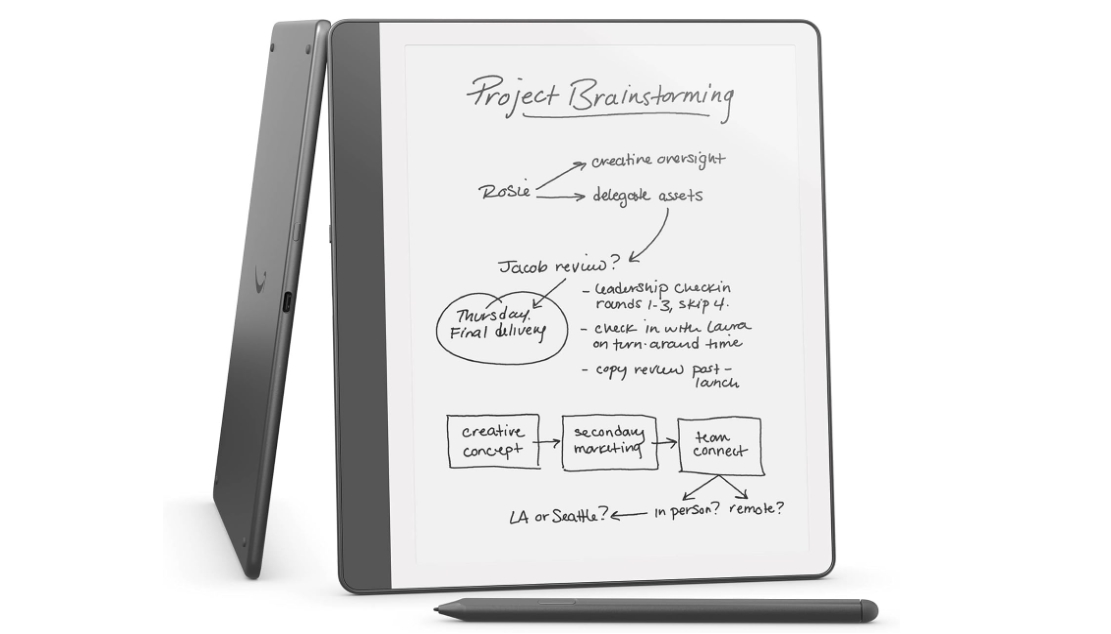















































































Comprehensive Hardware Requirements Report for Qwen3 (Part II)
Executive Summary Qwen 3 is a state-of-the-art large language model (LLM) designed for advanced reasoning, code generation, and multi-modal tasks. With dense and Mixture-of-Experts (MoE) architectures, it offers flexibility for deployment across diverse hardware tiers. This report outlines hardware requirements for deploying Qwen 3 variants, including minimum specifications, recommended configurations, scaling strategies, and cost analysis to guide enterprises in selecting optimal infrastructure. Model Architecture and Variants Qwen 3 Architecture Parameter Count: Up to 32B (dense) or MoE variants with scalable activation. Architecture Type: Dense or MoE (varies by variant). Context Length: 128K tokens. Transformer Structure: Multiple layers (exact count unspecified). Attention Mechanism: Multi-Head Attention (MHA) or equivalent. Quantization Support: FP16, 8-bit, and 4-bit quantization for reduced memory usage. Available Model Variants Model Version Parameters Architecture Use Cases Qwen 3 (Dense) 32B Dense High-end reasoning, code generation Qwen 3 (MoE) 100B+ total MoE Enterprise-scale applications Qwen 3-Turbo 14B Dense Balanced performance and cost Qwen 3-Lite 7B Dense Edge deployments, lightweight tasks Qwen 3-Mini 1.5B Dense Mobile/desktop applications Minimum Hardware Requirements Full Model (Qwen 3 Dense, 32B) GPU: 2x NVIDIA A100 80GB or 1x H100 80GB (FP16). VRAM: ~65GB (FP16), ~32GB (4-bit quantized). CPU: High-performance server-grade processor (e.g., AMD EPYC, Intel Xeon). RAM: Minimum 128GB DDR5 (2x VRAM capacity recommended). Storage: 1TB+ NVMe SSD for model weights. Qwen 3 (MoE) GPU: Multi-GPU setup (4x H100/A100 or 8x RTX 4090). VRAM: 150GB+ (unquantized), 75GB+ (4-bit). CPU: Dual-socket server CPUs (e.g., AMD EPYC 9654). RAM: 512GB DDR5 (to avoid bottlenecks). Storage: 2TB+ NVMe SSD. Qwen 3-Turbo (14B) GPU: 1x A100 40GB or 2x RTX 4090. VRAM: 28GB (FP16), ~14GB (4-bit). CPU: High-end desktop/server CPU (e.g., Intel Core i9, AMD Ryzen Threadripper). RAM: 64GB DDR5. Storage: 500GB NVMe SSD. Qwen 3-Lite (7B) GPU: 1x RTX 3090/4090 (24GB VRAM). VRAM: 14GB (FP16), ~7GB (4-bit). CPU: Modern multi-core (12+ cores). RAM: 32GB DDR5. Storage: 30GB NVMe SSD. Qwen 3-Mini (1.5B) GPU: RTX 3060 (12GB VRAM) or Apple M1/M2 with 16GB unified memory. VRAM: 3.9GB (FP16), ~2GB (4-bit). CPU: 8+ cores. RAM: 16GB. Storage: 10GB SSD. Recommended Hardware Specifications Enterprise-Level Deployment (Qwen 3 MoE) GPU: 8x NVIDIA H200/Blackwell or 16x A100 80GB. CPU: Dual AMD EPYC 9654 or Intel Xeon Platinum 8480+. RAM: 1TB+ DDR5 ECC. Storage: 4TB+ NVMe RAID + 20TB dataset storage. Networking: 200Gbps InfiniBand. Software: CUDA 12.2+, PyTorch 2.1+. High-Performance Deployment (32B Dense) GPU: 2x H100 80GB or 4x RTX 4090. CPU: AMD Threadripper PRO or Intel Xeon W. RAM: 512GB DDR5. Storage: 2TB NVMe SSD. Mid-Range Deployment (14B-7B) GPU: 1x RTX 4090 or A100 40GB. CPU: Ryzen 9 7950X or Core i9-13900K. RAM: 128GB DDR5. Storage: 1TB NVMe SSD. Entry-Level Deployment (1.5B-7B) GPU: RTX 4070/4080/4090. CPU: Ryzen 7/9 or Core i7/i9. RAM: 64GB DDR5. Storage: 500GB NVMe SSD. Scaling Considerations Vertical Scaling GPU Memory: Upgrade to H100/Blackwell for larger models. Multi-GPU: Use NVLink for distributed computing. RAM: System RAM should exceed total VRAM by 2-4x. Horizontal Scaling Multi-Node: Networked GPU servers with Kubernetes orchestration. Load Balancing: Tools like NVIDIA Triton or Ray Serve. Use Case Optimization Inference: Prioritize low-latency GPUs (H100) and quantization. Fine-Tuning: Cloud-based solutions for sporadic needs. Cost Analysis Hardware Acquisition Costs Deployment Type Estimated Cost (USD) Enterprise (MoE) $300,000 - $500,000 High-Performance (32B) $90,000 - $130,000 Mid-Range (14B) $7,000 - $12,000 Entry-Level (7B) $2,500 - $4,500 Operational Costs Power: $500 - $50,000 annually (varies by scale). Maintenance: 10-20% of hardware cost yearly. Cloud vs. On-Premises Deployment Cloud: AWS SageMaker, Azure VMs, or GCP Vertex AI. On-Premises: Cost-effective for high-volume usage. Break-Even: 18-24 months for enterprise deployments. Optimization Techniques Quantization: 4-bit reduces VRAM by 8x . Frameworks: vLLM, TensorRT-LLM, or SGLang. Deployment: Flash Attention, Paged Attention. Real-World Benchmarks H100 (32B): 2,500 tokens/sec (4-bit quantized). RTX 4090 (7B): 300 tokens/sec. Conclusion and Recommendations Start Small: Use Qwen 3-Lite/Mini for prototyping. Quantization: Essent

Executive Summary
Qwen 3 is a state-of-the-art large language model (LLM) designed for advanced reasoning, code generation, and multi-modal tasks. With dense and Mixture-of-Experts (MoE) architectures, it offers flexibility for deployment across diverse hardware tiers. This report outlines hardware requirements for deploying Qwen 3 variants, including minimum specifications, recommended configurations, scaling strategies, and cost analysis to guide enterprises in selecting optimal infrastructure.
Model Architecture and Variants
Qwen 3 Architecture
- Parameter Count: Up to 32B (dense) or MoE variants with scalable activation.
- Architecture Type: Dense or MoE (varies by variant).
- Context Length: 128K tokens.
- Transformer Structure: Multiple layers (exact count unspecified).
- Attention Mechanism: Multi-Head Attention (MHA) or equivalent.
- Quantization Support: FP16, 8-bit, and 4-bit quantization for reduced memory usage.
Available Model Variants
| Model Version | Parameters | Architecture | Use Cases |
|---|---|---|---|
| Qwen 3 (Dense) | 32B | Dense | High-end reasoning, code generation |
| Qwen 3 (MoE) | 100B+ total | MoE | Enterprise-scale applications |
| Qwen 3-Turbo | 14B | Dense | Balanced performance and cost |
| Qwen 3-Lite | 7B | Dense | Edge deployments, lightweight tasks |
| Qwen 3-Mini | 1.5B | Dense | Mobile/desktop applications |
Minimum Hardware Requirements
Full Model (Qwen 3 Dense, 32B)
- GPU: 2x NVIDIA A100 80GB or 1x H100 80GB (FP16).
- VRAM: ~65GB (FP16), ~32GB (4-bit quantized).
- CPU: High-performance server-grade processor (e.g., AMD EPYC, Intel Xeon).
- RAM: Minimum 128GB DDR5 (2x VRAM capacity recommended).
- Storage: 1TB+ NVMe SSD for model weights.
Qwen 3 (MoE)
- GPU: Multi-GPU setup (4x H100/A100 or 8x RTX 4090).
- VRAM: 150GB+ (unquantized), 75GB+ (4-bit).
- CPU: Dual-socket server CPUs (e.g., AMD EPYC 9654).
- RAM: 512GB DDR5 (to avoid bottlenecks).
- Storage: 2TB+ NVMe SSD.
Qwen 3-Turbo (14B)
- GPU: 1x A100 40GB or 2x RTX 4090.
- VRAM: 28GB (FP16), ~14GB (4-bit).
- CPU: High-end desktop/server CPU (e.g., Intel Core i9, AMD Ryzen Threadripper).
- RAM: 64GB DDR5.
- Storage: 500GB NVMe SSD.
Qwen 3-Lite (7B)
- GPU: 1x RTX 3090/4090 (24GB VRAM).
- VRAM: 14GB (FP16), ~7GB (4-bit).
- CPU: Modern multi-core (12+ cores).
- RAM: 32GB DDR5.
- Storage: 30GB NVMe SSD.
Qwen 3-Mini (1.5B)
- GPU: RTX 3060 (12GB VRAM) or Apple M1/M2 with 16GB unified memory.
- VRAM: 3.9GB (FP16), ~2GB (4-bit).
- CPU: 8+ cores.
- RAM: 16GB.
- Storage: 10GB SSD.
Recommended Hardware Specifications
Enterprise-Level Deployment (Qwen 3 MoE)
- GPU: 8x NVIDIA H200/Blackwell or 16x A100 80GB.
- CPU: Dual AMD EPYC 9654 or Intel Xeon Platinum 8480+.
- RAM: 1TB+ DDR5 ECC.
- Storage: 4TB+ NVMe RAID + 20TB dataset storage.
- Networking: 200Gbps InfiniBand.
- Software: CUDA 12.2+, PyTorch 2.1+.
High-Performance Deployment (32B Dense)
- GPU: 2x H100 80GB or 4x RTX 4090.
- CPU: AMD Threadripper PRO or Intel Xeon W.
- RAM: 512GB DDR5.
- Storage: 2TB NVMe SSD.
Mid-Range Deployment (14B-7B)
- GPU: 1x RTX 4090 or A100 40GB.
- CPU: Ryzen 9 7950X or Core i9-13900K.
- RAM: 128GB DDR5.
- Storage: 1TB NVMe SSD.
Entry-Level Deployment (1.5B-7B)
- GPU: RTX 4070/4080/4090.
- CPU: Ryzen 7/9 or Core i7/i9.
- RAM: 64GB DDR5.
- Storage: 500GB NVMe SSD.
Scaling Considerations
Vertical Scaling
- GPU Memory: Upgrade to H100/Blackwell for larger models.
- Multi-GPU: Use NVLink for distributed computing.
- RAM: System RAM should exceed total VRAM by 2-4x.
Horizontal Scaling
- Multi-Node: Networked GPU servers with Kubernetes orchestration.
- Load Balancing: Tools like NVIDIA Triton or Ray Serve.
Use Case Optimization
- Inference: Prioritize low-latency GPUs (H100) and quantization.
- Fine-Tuning: Cloud-based solutions for sporadic needs.
Cost Analysis
Hardware Acquisition Costs
| Deployment Type | Estimated Cost (USD) |
|---|---|
| Enterprise (MoE) | $300,000 - $500,000 |
| High-Performance (32B) | $90,000 - $130,000 |
| Mid-Range (14B) | $7,000 - $12,000 |
| Entry-Level (7B) | $2,500 - $4,500 |
Operational Costs
- Power: $500 - $50,000 annually (varies by scale).
- Maintenance: 10-20% of hardware cost yearly.
Cloud vs. On-Premises Deployment
- Cloud: AWS SageMaker, Azure VMs, or GCP Vertex AI.
- On-Premises: Cost-effective for high-volume usage.
- Break-Even: 18-24 months for enterprise deployments.
Optimization Techniques
- Quantization: 4-bit reduces VRAM by 8x .
- Frameworks: vLLM, TensorRT-LLM, or SGLang.
- Deployment: Flash Attention, Paged Attention.
Real-World Benchmarks
- H100 (32B): 2,500 tokens/sec (4-bit quantized).
- RTX 4090 (7B): 300 tokens/sec.
Conclusion and Recommendations
- Start Small: Use Qwen 3-Lite/Mini for prototyping.
- Quantization: Essential for reducing VRAM demands.
- Hybrid Approach: Cloud for development, on-premises for production.
- Optimize: Leverage vLLM or TensorRT-LLM for performance gains.
For enterprises, the full Qwen 3 MoE demands significant investment but offers unmatched scalability. Smaller organizations can deploy distilled variants on consumer hardware, balancing cost and capability.


