![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)









































































































































































































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































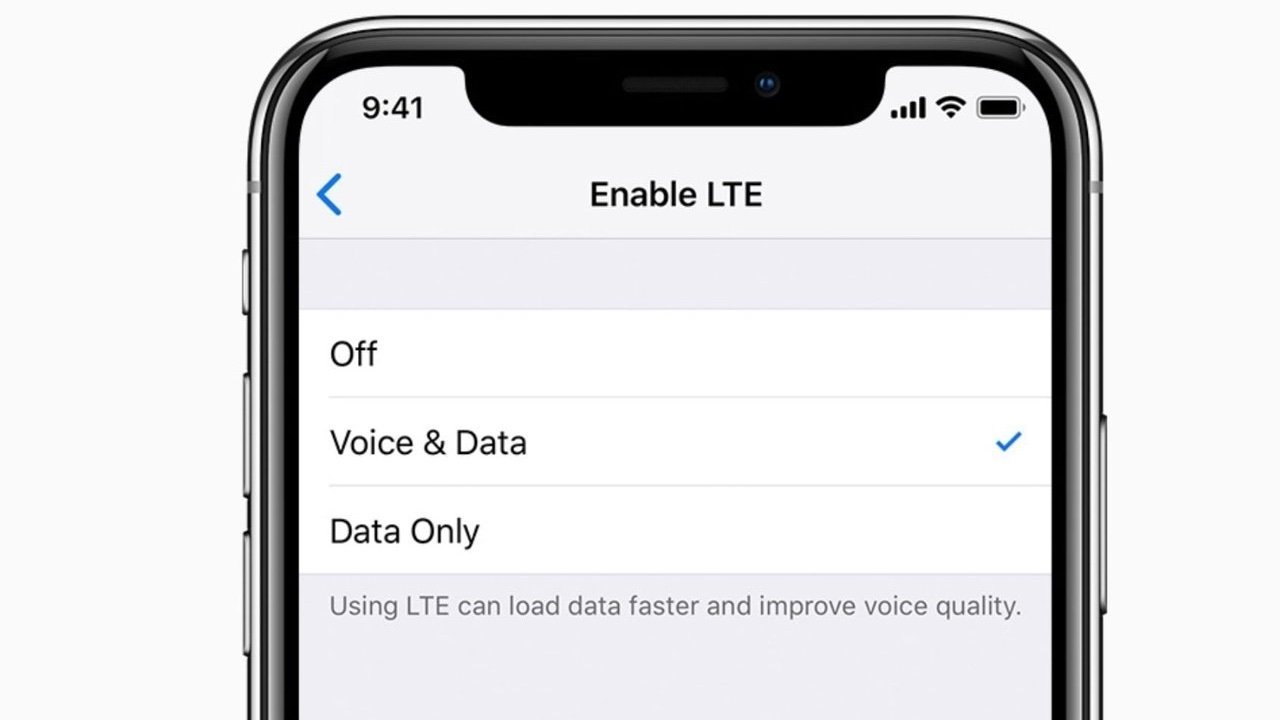



























![Apple Ships 55 Million iPhones, Claims Second Place in Q1 2025 Smartphone Market [Report]](https://www.iclarified.com/images/news/97185/97185/97185-640.jpg)


































































































Chapter 2: Designing Data-Intensive Applications - Data models - Part 2 : Query Languages
In the first part of this chapter, we discussed relational databases and NoSQL systems. Now, let’s look at something fundamental to how we interact with data: query languages. This introduces the differences between declarative and imperative approaches, their applications in web development, and even how distributed systems like MapReduce fit into this picture. Declarative vs. Imperative Querying When relational databases were introduced, they didn’t just offer a new way of storing data—they introduced a simpler way of querying it. SQL became the standard, and it’s a declarative query language, unlike earlier systems like IMS and CODASYL, which used imperative code. What’s the Difference? Here’s an example of imperative code in JavaScript to find all sharks in a dataset: function getSharks() { var sharks = []; for (var i = 0; i p { background-color: blue; } This selector simply declares the pattern of elements to style. In contrast, here’s an imperative JavaScript version: var liElements = document.getElementsByTagName("li"); for (var i = 0; i

In the first part of this chapter, we discussed relational databases and NoSQL systems. Now, let’s look at something fundamental to how we interact with data: query languages. This introduces the differences between declarative and imperative approaches, their applications in web development, and even how distributed systems like MapReduce fit into this picture.
Declarative vs. Imperative Querying
When relational databases were introduced, they didn’t just offer a new way of storing data—they introduced a simpler way of querying it. SQL became the standard, and it’s a declarative query language, unlike earlier systems like IMS and CODASYL, which used imperative code.
What’s the Difference?
Here’s an example of imperative code in JavaScript to find all sharks in a dataset:
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}
Step by step, you’re telling the computer how to do it: loop through the data, check a condition, and store the result.
Now look at the declarative version:
SELECT * FROM animals WHERE family = 'Sharks';
You just specify what you want—“Give me all animals where the family is Sharks”—and let the database figure out how to get it.
Why Declarative Wins
- Simplicity: Declarative languages let you focus on the result, not the process.
- Optimization: The database can optimize how it executes the query (e.g., using indexes or parallel processing).
- Parallel Execution: Declarative code doesn’t rely on strict execution order, making it easier to run across multiple cores or machines.
Declarative Queries on the Web
This difference isn’t just for databases—it’s everywhere, including web development. Let’s take a simple example:
class="selected">
Sharks
Great White Shark
Tiger Shark
Hammerhead Shark
Whales
Blue Whale
Humpback Whale
Fin Whale
You want to highlight the element of the selected with a blue background. In CSS (declarative), you’d write:
li.selected > p {
background-color: blue;
}
This selector simply declares the pattern of elements to style.
In contrast, here’s an imperative JavaScript version:
var liElements = document.getElementsByTagName("li");
for (var i = 0; i < liElements.length; i++) {
if (liElements[i].className === "selected") {
var children = liElements[i].childNodes;
for (var j = 0; j < children.length; j++) {
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
child.setAttribute("style", "background-color: blue");
}
}
}
}
Why Declarative is Better
- Cleaner Code: The CSS snippet is shorter and easier to understand.
-
Dynamic Updates: If the
selectedclass changes dynamically, CSS handles it automatically, but the JavaScript version would require extra work.
MapReduce Querying
So far, we’ve talked about declarative vs. imperative approaches in databases and web development. Let’s now look at distributed systems, starting with MapReduce.
MapReduce is a programming model popularized by Google for processing large datasets across many machines. It’s not fully declarative or imperative—it’s somewhere in between.
Example Use Case
Say you’re a marine biologist tracking animal sightings. You want a report showing the number of sharks observed per month.
In PostgreSQL, you’d write:
SELECT date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;
In MongoDB’s MapReduce, it looks like this:
db.observations.mapReduce(
function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
function reduce(key, values) {
return Array.sum(values);
},
{
query: { family: "Sharks" },
out: "monthlySharkReport"
}
);
Here’s what’s happening:
-
Map Function: Processes each document, emitting key-value pairs like
"2025-05"andnumAnimals. - Reduce Function: Groups data by keys (e.g., months) and performs calculations (e.g., summing up observations).
Pros and Cons
- Flexibility: The Map and Reduce functions can include custom logic.
- Complexity: Writing two coordinated functions is harder than a single declarative query.
Aggregation Pipelines
Recognizing the complexity of MapReduce, MongoDB introduced the aggregation pipeline in version 2.2. This is a declarative query language with a JSON-based syntax.
Here’s how our shark observation query would look:
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
}
}
]);
The aggregation pipeline is simpler and easier to use than MapReduce while still being powerful.
Takeaways
- Declarative Query Languages: Abstract away the "how," making them easier to write and optimize.
- Imperative Code: Useful in some cases but often verbose and harder to maintain.
- MapReduce: A hybrid approach, powerful but more complex than declarative alternatives.
- Aggregation Pipelines: Offer a declarative, user-friendly alternative to MapReduce for distributed querying.
Declarative querying isn’t just about writing less code—it’s about making systems smarter, more efficient, and easier to maintain. In the next chapter, we’ll continue exploring the tools and patterns that make modern data systems tick.
Conclusion
Understanding the distinction between declarative and imperative query languages is crucial for designing scalable and maintainable systems. Declarative approaches, like SQL and aggregation pipelines, allow for cleaner, more optimized queries that abstract away complexity—making them ideal for modern, data-intensive applications. Meanwhile, imperative models still have their place when fine-grained control or custom logic is needed, especially in distributed systems. Striking the right balance is key to building robust architectures.