
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)



















































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
























































nintendodirect_nintendoswitch2–4.2.2025(2).jpeg?#)

































_Wavebreakmedia_Ltd_FUS1507-1_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)













































































































![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)




















































































































Build the Smartest AI Bot You’ve Ever Seen — A 7B Model + Web Search, Right on Your Laptop
Summary: RAG Web is a Python-based application that combines web search and natural language processing to answer user queries. It uses DuckDuckGo for retrieving web search results and a Hugging Face Zephyr-7B-beta model for generating answers based on the retrieved context. Web Search RAG Architecture In this PO user query is sent as an input for the external web search. For this implementation it is DuckDuckGo service to avoid API and security limitations for the more efficient search services like Google. Search Result (as Context) is sent with the original user query as an input for the language transfer model (HuggingFaceH4/zephyr-7b-beta) which summarise and extracts the answer and output to the user. Deployment Instructions 1. Clone / Copy the Project git clone https://github.com/alexander-uspenskiy/rag_web cd rag_web 2. Create and Activate Virtual Environment python3 -m venv venv source venv/bin/activate 3. Install Requirements pip install -r requirements.txt 4. Run the Script python rag_web.py How the Script Works This is a lightweight Retrieval-Augmented Generation (RAG) implementation using: • A 7B language model (Zephyr) from Hugging Face • DuckDuckGo for real-time web search (no API key needed) Code Breakdown 1. Imports and Setup from transformers import pipeline from duckduckgo_search import DDGS import textwrap import re transformers: From Hugging Face, used to load and interact with the LLM. DDGS: DuckDuckGo’s Python interface for search queries. textwrap: Used for formatting the output neatly. re: Regular expressions to clean the model’s output. 2. Web Search Function def search_web(query, num_results=3): with DDGS() as ddgs: results = ddgs.text(query, max_results=num_results) return [r['body'] for r in results] Purpose: Takes a user query and performs a web search. How it works: Uses the DDGS().text(...) method to fetch search results. Returns: A list of snippet texts (just the bodies, without links/titles). 3. Context Generation def get_context(query): snippets = search_web(query) context = " ".join(snippets) return textwrap.fill(context, width=120) Combines all snippet results into one big context paragraph. Applies word wrapping to improve readability (optional for model input but nice for debugging/logging). 4. Model Initialization qa_pipeline = pipeline( "text-generation", model="HuggingFaceH4/zephyr-7b-beta", tokenizer="HuggingFaceH4/zephyr-7b-beta", device_map="auto" ) Loads Zephyr-7B, a chat-tuned model from Hugging Face. device_map="auto" lets Hugging Face offload model parts across available hardware (e.g., MPS or CUDA). 5. Question Answering Function def answer_question(query): a) Get Context context = get_context(query) Performs search and prepares the retrieved content. b) Prepare Prompt prompt = f"""[CONTEXT] {context} [QUESTION] {query} [ANSWER] """ This RAG-style prompt provides the model: [CONTEXT] = retrieved text from the web [QUESTION] = user’s query [ANSWER] = expected model output c) Generate Answer response = qa_pipeline(prompt, max_new_tokens=128, do_sample=True) The model generates text following the [ANSWER] tag. do_sample=True allows some creativity/randomness. d) Post-processing answer_raw = response[0]['generated_text'].split('[ANSWER]')[-1].strip() answer = re.sub(r"]+>", "", answer_raw) Strips the prompt from the output. Removes any stray XML/HTML-style tags (, , etc.) the model might emit. 6. User Interaction Loop if __name__ == "__main__": Opens a CLI loop. Reads user input from the terminal. Runs the full search + answer pipeline. Displays the answer and continues unless the user types exit or quit. Architecture Summary [User Query] ↓ DuckDuckGo Search API ↓ [Web Snippets] ↓ [CONTEXT] + [QUESTION] Prompt ↓ Zephyr 7B (Hugging Face) ↓ [Generated Answer] ↓ Display in Terminal Why Zephyr-7B? Zephyr is a family of instruction-tuned, open-weight language models developed by Hugging Face. It's designed to be helpful, honest, and harmless — and small enough to run on consumer hardware. Key Characteristics Feature Description Model Size 7 Billion parameters Architecture Based on Mistral-7B (dense transformer, multi-query attention) Tuning Fine-tuned using DPO (Direct Preference Optimization) Context Length Supports up to 8,192 tokens Hardware Runs locally on M1/M2 Macs, GPUs, or even CPU with quantization Use Case Optimized for dialogue, instructions, and chat use Why I Picked Zephyr for This Script Open weights — no API keys, no rate limits Runs on laptop — 7B is small enough for consumer devices Instruction-tuned — great at handling prompts containing context and questions Frie

Summary:
RAG Web is a Python-based application that combines web search and natural language processing to answer user queries. It uses DuckDuckGo for retrieving web search results and a Hugging Face Zephyr-7B-beta model for generating answers based on the retrieved context.
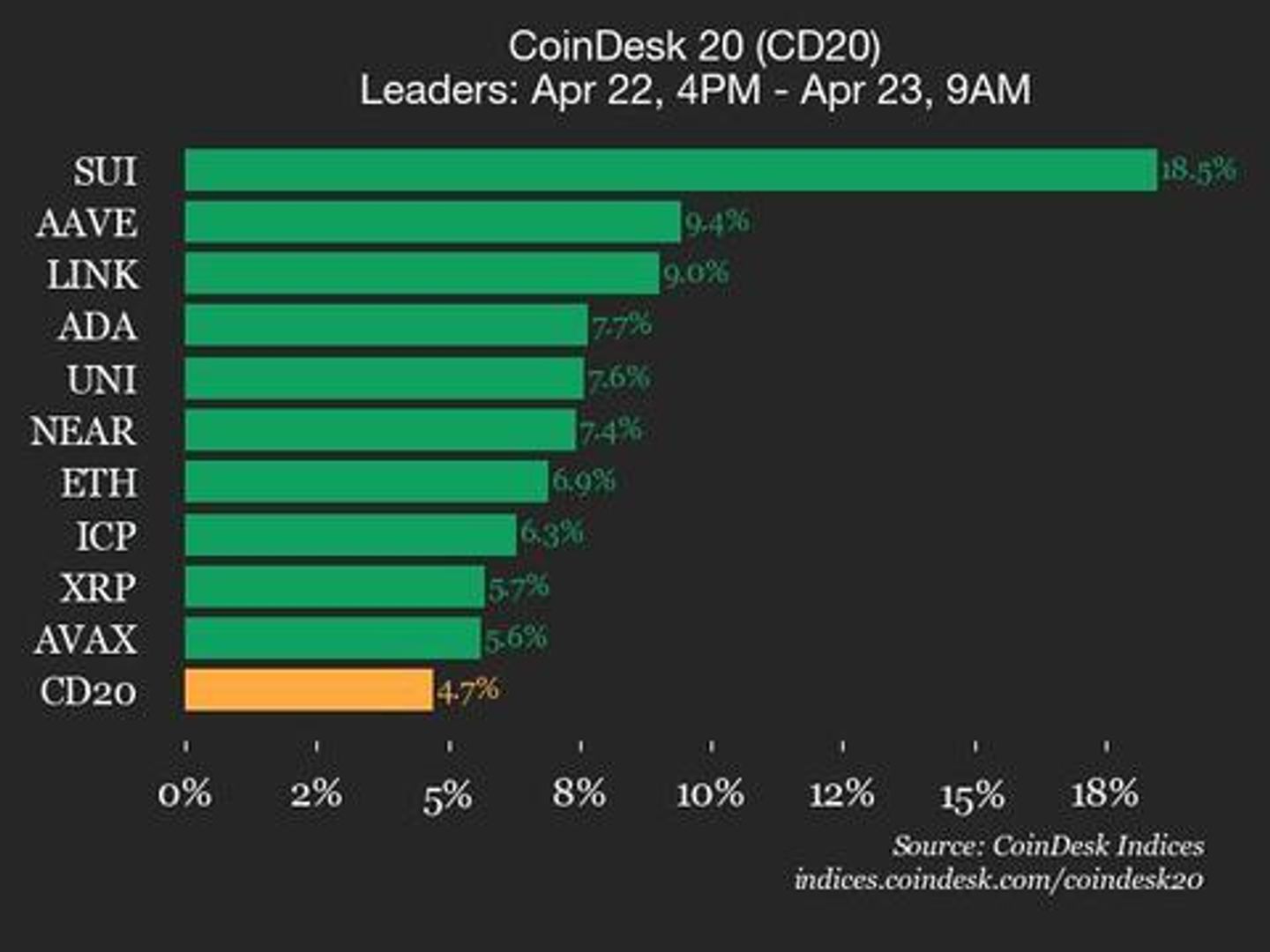
Web Search RAG Architecture
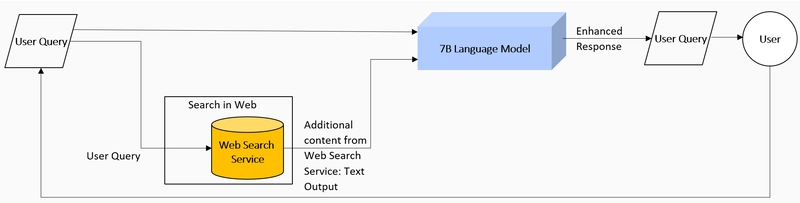
In this PO user query is sent as an input for the external web search. For this implementation it is DuckDuckGo service to avoid API and security limitations for the more efficient search services like Google. Search Result (as Context) is sent with the original user query as an input for the language transfer model (HuggingFaceH4/zephyr-7b-beta) which summarise and extracts the answer and output to the user.
Deployment Instructions
1. Clone / Copy the Project
git clone https://github.com/alexander-uspenskiy/rag_web
cd rag_web
2. Create and Activate Virtual Environment
python3 -m venv venv
source venv/bin/activate
3. Install Requirements
pip install -r requirements.txt
4. Run the Script
python rag_web.py
How the Script Works
This is a lightweight Retrieval-Augmented Generation (RAG) implementation using:
• A 7B language model (Zephyr) from Hugging Face
• DuckDuckGo for real-time web search (no API key needed)
Code Breakdown
1. Imports and Setup
from transformers import pipeline
from duckduckgo_search import DDGS
import textwrap
import re
- transformers: From Hugging Face, used to load and interact with the LLM.
- DDGS: DuckDuckGo’s Python interface for search queries.
- textwrap: Used for formatting the output neatly.
- re: Regular expressions to clean the model’s output.
2. Web Search Function
def search_web(query, num_results=3):
with DDGS() as ddgs:
results = ddgs.text(query, max_results=num_results)
return [r['body'] for r in results]
- Purpose: Takes a user query and performs a web search.
- How it works: Uses the DDGS().text(...) method to fetch search results.
- Returns: A list of snippet texts (just the bodies, without links/titles).
3. Context Generation
def get_context(query):
snippets = search_web(query)
context = " ".join(snippets)
return textwrap.fill(context, width=120)
- Combines all snippet results into one big context paragraph.
- Applies word wrapping to improve readability (optional for model input but nice for debugging/logging).
4. Model Initialization
qa_pipeline = pipeline(
"text-generation",
model="HuggingFaceH4/zephyr-7b-beta",
tokenizer="HuggingFaceH4/zephyr-7b-beta",
device_map="auto"
)
- Loads Zephyr-7B, a chat-tuned model from Hugging Face.
- device_map="auto" lets Hugging Face offload model parts across available hardware (e.g., MPS or CUDA).
5. Question Answering Function
def answer_question(query):
a) Get Context
context = get_context(query)
- Performs search and prepares the retrieved content.
b) Prepare Prompt
prompt = f"""[CONTEXT]
{context}
[QUESTION]
{query}
[ANSWER]
"""
This RAG-style prompt provides the model:
- [CONTEXT] = retrieved text from the web
- [QUESTION] = user’s query
- [ANSWER] = expected model output
c) Generate Answer
response = qa_pipeline(prompt, max_new_tokens=128, do_sample=True)
- The model generates text following the [ANSWER] tag.
- do_sample=True allows some creativity/randomness.
d) Post-processing
answer_raw = response[0]['generated_text'].split('[ANSWER]')[-1].strip()
answer = re.sub(r"<[^>]+>", "", answer_raw)
- Strips the prompt from the output.
- Removes any stray XML/HTML-style tags (, , etc.) the model might emit.
6. User Interaction Loop
if __name__ == "__main__":
- Opens a CLI loop.
- Reads user input from the terminal.
- Runs the full search + answer pipeline.
- Displays the answer and continues unless the user types exit or quit.
Architecture Summary
[User Query]
↓
DuckDuckGo Search API
↓
[Web Snippets]
↓
[CONTEXT] + [QUESTION] Prompt
↓
Zephyr 7B (Hugging Face)
↓
[Generated Answer]
↓
Display in Terminal
Why Zephyr-7B?
Zephyr is a family of instruction-tuned, open-weight language models developed by Hugging Face. It's designed to be helpful, honest, and harmless — and small enough to run on consumer hardware.
Key Characteristics
| Feature | Description |
|---|---|
| Model Size | 7 Billion parameters |
| Architecture | Based on Mistral-7B (dense transformer, multi-query attention) |
| Tuning | Fine-tuned using DPO (Direct Preference Optimization) |
| Context Length | Supports up to 8,192 tokens |
| Hardware | Runs locally on M1/M2 Macs, GPUs, or even CPU with quantization |
| Use Case | Optimized for dialogue, instructions, and chat use |
Why I Picked Zephyr for This Script
- Open weights — no API keys, no rate limits
- Runs on laptop — 7B is small enough for consumer devices
- Instruction-tuned — great at handling prompts containing context and questions
- Friendly outputs — fine-tuned to be helpful and safe
-
Easy integration — via Hugging Face
transformerspipeline
Compared to Other Models
| Model | Pros | Cons |
|---|---|---|
| Zephyr-7B | Open, chat-tuned, lightweight | Slightly less fluent than GPT-4 |
| GPT-3.5/4 | Top-tier reasoning | Closed, pay-per-use, no local use |
| Mistral-7B | High-speed base model | Needs fine-tuning for QA/chat |
| LLaMA2 7B | Open and popular | Less optimized for chat out-of-box |
Final Thoughts on model
Zephyr-7B hits the sweet spot between performance, privacy, and portability. It gives you GPT-style interaction with full local control — and when combined with web search, it becomes a surprisingly capable assistant.
If you're building a local AI assistant or just want to experiment with RAG pipelines without burning through API tokens, Zephyr-7B is a strong starting point.
Usage example
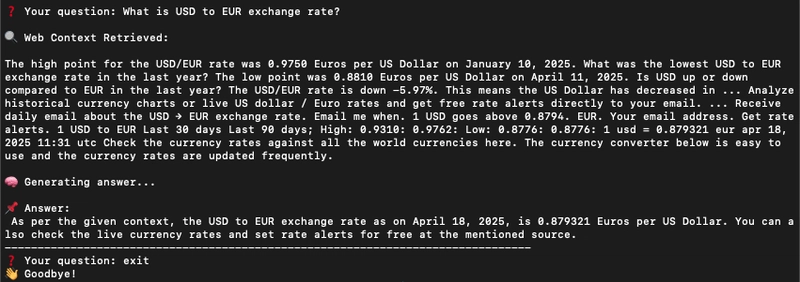
You can see the RAG searches for the real-time data to add to the context and send to the model so model can generate an answer:
Performance Optimization
While the baseline implementation is functional and responsive, several optimizations can improve performance:
-
Model Quantization: Use 4-bit or 8-bit quantized versions of the model with
bitsandbytesto reduce memory usage and inference time. - Streaming Inference: Implement token streaming for faster perceived response times.
- Caching Search Results: Avoid redundant queries by caching recent DuckDuckGo results locally.
-
Async Execution: Use
asyncioto parallelize web search and token generation. - Prompt Truncation: Dynamically trim context to fit within model’s token limits, prioritizing relevance.
Future Enhancements for Enterprise RAG
To scale this into an enterprise-grade RAG system, consider the following enhancements:
- Vector Search Integration: Add to a web search a hybrid search system using vector embeddings (e.g., FAISS, Weaviate, Pinecone).
- Knowledge Base Sync: Sync data from private sources like Confluence, Notion, SharePoint, or document stores.
- Multi-turn Memory: Add a conversation memory layer using a session buffer or vector memory for context retention.
- User Feedback Loop: Incorporate thumbs-up/down voting to improve results and fine-tune retrieval relevance.
- Security & Auditability: Wrap API access and logging in enterprise security layers (SSO, encryption, RBAC).
- Scalability: Run inference via model serving tools like vLLM, TGI, or TorchServe with GPU acceleration and autoscaling.
Summary
This article explores how to build a lightweight Retrieval-Augmented Generation (RAG) assistant using a 7B parameter open-source language model (Zephyr-7B) and real-time web search via DuckDuckGo.
The solution runs locally, requires no external APIs, and leverages Hugging Face's transformers library to deliver intelligent, contextual responses to user queries.
Zephyr-7B was chosen for its balance of performance and portability. It is instruction-tuned, easy to run on consumer hardware, and excels in structured question-answering tasks. When paired with live search results, it creates a powerful, self-contained research assistant.
This project is ideal for developers looking to experiment with local LLMs, build RAG prototypes, or create privacy-respecting AI tools without relying on paid cloud APIs.
The full implementation, code walkthrough, and architecture are detailed below.
Use a GitHub repository to get a POC code: [https://github.com/alexander-uspenskiy/rag_web(https://github.com/alexander-uspenskiy/rag_web)
Happy Coding!