





































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)










































































































































































































































































_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































![Craft adds Readwise integration for working with book notes and highlights [50% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/craft3.jpg.png?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)































































































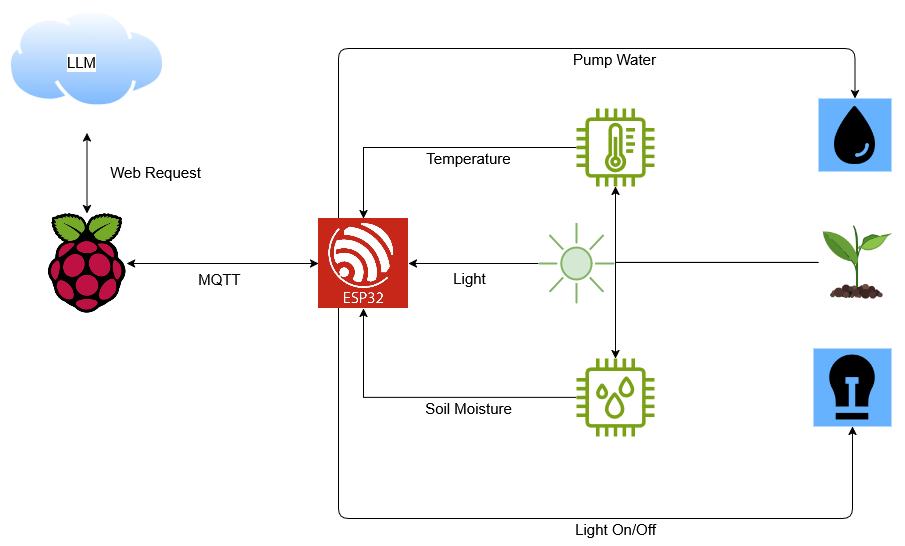
Beyond the Hype: What Truly Makes an AI a Great Coding Partner?
Beyond the Hype: What Truly Makes an AI a Great Coding Partner? What Makes an AI Good at Coding? Ever tried to explain a coding problem to a non-technical friend? You start enthusiastically, but within minutes their eyes glaze over, and they're mentally planning their grocery list while nodding politely. That's basically what using the wrong AI coding assistant feels like. So what separates the AI tools that "get it" from those that just smile and nod? Let's break it down. Beyond Benchmarks: Real-World Coding Capabilities If you've spent any time researching AI models, you've probably seen impressive benchmark scores and capability comparisons. "Model X achieved 92.7% on HumanEval!" "Model Y sets new records on MBPP!" That's great and all, but benchmarks are like those coding interview questions about reversing a binary tree – rarely reflective of day-to-day work. What matters is how these tools perform on your actual coding tasks. Here's what I've found actually matters: Code Understanding vs. Code Generation High-quality AI code generation isn't just about producing syntactically correct code — it's about creating robust, adaptable solutions. The difference reveals itself when you ask the AI to: Explain why a specific pattern was used Identify potential edge cases in the code Adapt the solution to slightly different requirements A good AI coding assistant doesn't just spit out solutions – it comprehends the underlying logic and can reason about it. This is where the larger, reasoning-focused models tend to shine. They don't just know what code to write; they understand why it works. Documentation and Explanation Abilities Let's be honest – we spend as much time explaining code (in comments, docs, and PR reviews) as we do writing it. AI tools diverge dramatically in their ability to: Generate clear documentation Explain complex code in simple terms Adapt their explanations to different knowledge levels I once asked a junior developer and a senior architect to explain the same microservice architecture. The junior gave me a technically correct but overwhelming data dump. The senior started with, "Imagine a restaurant kitchen with specialized chefs..." The best AI coding assistants have this same ability to meet you at your level and explain things conceptually before diving into implementation details. Refactoring and Debugging Intelligence in brownfield code Basic code generation is common and is fairly trivial now; The true measure of an AI or developer is their ability to handle tasks like AI refactoring, deep debugging, and troubleshooting evolving brownfield codebases. The best AI assistants are like that senior developer who can glance at an error message and immediately say, "Ah, check your authentication middleware – you're probably missing a token refresh." Lesser tools will offer generic advice like "check your syntax" or "make sure your variables are defined" – technically correct but not particularly helpful. This debugging intelligence comes from a combination of pattern recognition across millions of code examples and deeper reasoning about program logic and execution flow. It's also where specialized coding tools sometimes outperform general-purpose models, despite the latter having more overall "intelligence." Security and Performance Sensitivity Beyond just working code, a great AI agent must also understand security and performance trade-offs. Without structured reasoning or context-aware rules, even top AI agents can introduce critical mistakes. For instance, while using Cursor (without any additional rules or instructions) with Claude 3.7, the AI agent modified backend code to use the Supabase service_role key instead of the intended anon key for client-side operations — a major security flaw because it effectively broke Postgres RLS (Row-Level Security) protections. The service_role key has elevated privileges meant only for secure server-side environments. A similar issue also occurred with GPT-4o during a comprehensive refactoring involving storage buckets and Postgres access in Supabase. These incidents highlight why context management, explicit instruction, and enforcing operational rules are absolutely crucial when using AI coding assistants at scale. Architectural Complexity Good AI coding assistants shine when dealing with architectural complexity. It's one thing to help write a utility function; it's another to reason about dependency injection in a service-oriented architecture, or how event-driven systems coordinate between microservices. The best models don't just generate code — they help you make smart design decisions across layers. A quick note on coding benchmarks While we're talking about evaluating AI coding capabilities, it's worth mentioning some benchmarks that try to quantify these skills. Commonly referenced ones include: SWE-bench: Focu

Beyond the Hype: What Truly Makes an AI a Great Coding Partner?
What Makes an AI Good at Coding?
Ever tried to explain a coding problem to a non-technical friend? You start enthusiastically, but within minutes their eyes glaze over, and they're mentally planning their grocery list while nodding politely.
That's basically what using the wrong AI coding assistant feels like.
So what separates the AI tools that "get it" from those that just smile and nod? Let's break it down.
Beyond Benchmarks: Real-World Coding Capabilities
If you've spent any time researching AI models, you've probably seen impressive benchmark scores and capability comparisons. "Model X achieved 92.7% on HumanEval!" "Model Y sets new records on MBPP!"
That's great and all, but benchmarks are like those coding interview questions about reversing a binary tree – rarely reflective of day-to-day work. What matters is how these tools perform on your actual coding tasks.
Here's what I've found actually matters:
Code Understanding vs. Code Generation
High-quality AI code generation isn't just about producing syntactically correct code — it's about creating robust, adaptable solutions.
The difference reveals itself when you ask the AI to:
- Explain why a specific pattern was used
- Identify potential edge cases in the code
- Adapt the solution to slightly different requirements
A good AI coding assistant doesn't just spit out solutions – it comprehends the underlying logic and can reason about it. This is where the larger, reasoning-focused models tend to shine. They don't just know what code to write; they understand why it works.
Documentation and Explanation Abilities
Let's be honest – we spend as much time explaining code (in comments, docs, and PR reviews) as we do writing it.
AI tools diverge dramatically in their ability to:
- Generate clear documentation
- Explain complex code in simple terms
- Adapt their explanations to different knowledge levels
I once asked a junior developer and a senior architect to explain the same microservice architecture. The junior gave me a technically correct but overwhelming data dump. The senior started with, "Imagine a restaurant kitchen with specialized chefs..."
The best AI coding assistants have this same ability to meet you at your level and explain things conceptually before diving into implementation details.
Refactoring and Debugging Intelligence in brownfield code
Basic code generation is common and is fairly trivial now; The true measure of an AI or developer is their ability to handle tasks like AI refactoring, deep debugging, and troubleshooting evolving brownfield codebases.
The best AI assistants are like that senior developer who can glance at an error message and immediately say, "Ah, check your authentication middleware – you're probably missing a token refresh."
Lesser tools will offer generic advice like "check your syntax" or "make sure your variables are defined" – technically correct but not particularly helpful.
This debugging intelligence comes from a combination of pattern recognition across millions of code examples and deeper reasoning about program logic and execution flow. It's also where specialized coding tools sometimes outperform general-purpose models, despite the latter having more overall "intelligence."
Security and Performance Sensitivity
Beyond just working code, a great AI agent must also understand security and performance trade-offs. Without structured reasoning or context-aware rules, even top AI agents can introduce critical mistakes. For instance, while using Cursor (without any additional rules or instructions) with Claude 3.7, the AI agent modified backend code to use the Supabase service_role key instead of the intended anon key for client-side operations — a major security flaw because it effectively broke Postgres RLS (Row-Level Security) protections. The service_role key has elevated privileges meant only for secure server-side environments. A similar issue also occurred with GPT-4o during a comprehensive refactoring involving storage buckets and Postgres access in Supabase. These incidents highlight why context management, explicit instruction, and enforcing operational rules are absolutely crucial when using AI coding assistants at scale.
Architectural Complexity
Good AI coding assistants shine when dealing with architectural complexity. It's one thing to help write a utility function; it's another to reason about dependency injection in a service-oriented architecture, or how event-driven systems coordinate between microservices. The best models don't just generate code — they help you make smart design decisions across layers.
A quick note on coding benchmarks
While we're talking about evaluating AI coding capabilities, it's worth mentioning some benchmarks that try to quantify these skills.
Commonly referenced ones include:
- SWE-bench: Focuses on solving real GitHub issues across diverse codebases.
- HumanEval: Tests code generation for algorithmic problems, but often feels a bit detached from messy real-world scenarios.
If you're serious about identifying the best AI tools and models for coding, my top recommendations are::
- Aider Benchmarks: Evaluate performance on realistic refactoring, troubleshooting, and brownfield code tasks.
- ProlLM Benchmarks (ProlLM Leaderboard): A newer benchmark that tests more realistic coding tasks, multi-file reasoning, SQL creds, function calling etc.
For an aggregated view of many model capabilities across benchmarks (not just coding, but broader multi-modal, reasoning, and general language capability too), check out Artificial Analysis Aggregated Leaderboard.
Cost-Effectiveness Analysis: The Price of AI Productivity
Alright, timeout before we start throwing subscription prices around like Monopoly money.
First — what kind of AI coding help are we even talking about?
Because "AI coding assistant" today covers a wild range — from glorified autocomplete to full-blown "sit back while I architect your startup" agents.
(And sometimes even to vibe coding, where you just kind of hope the AI figures out your half-finished thoughts and writes the code anyway — it's like rubber duck debugging, but the duck sometimes tries to build a nuclear reactor.)


