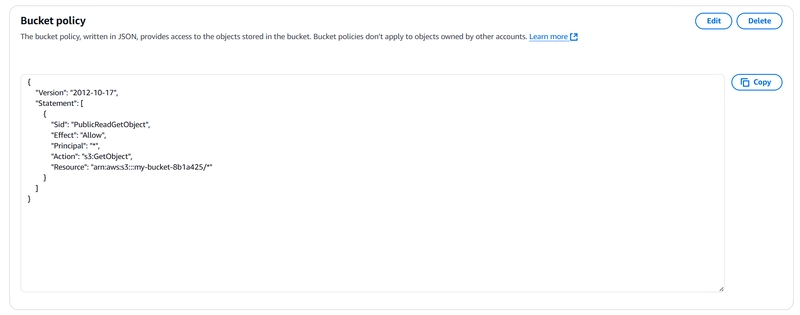
.jpg)









































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

















































































































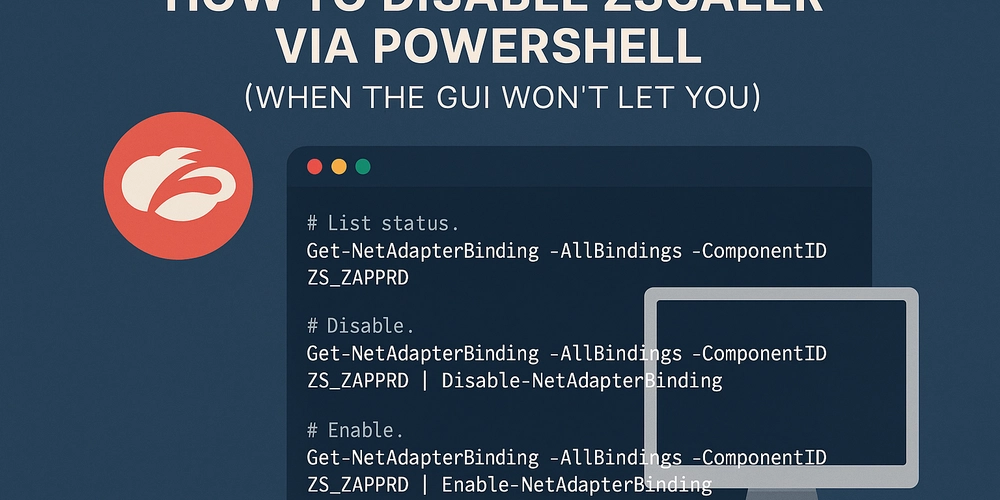


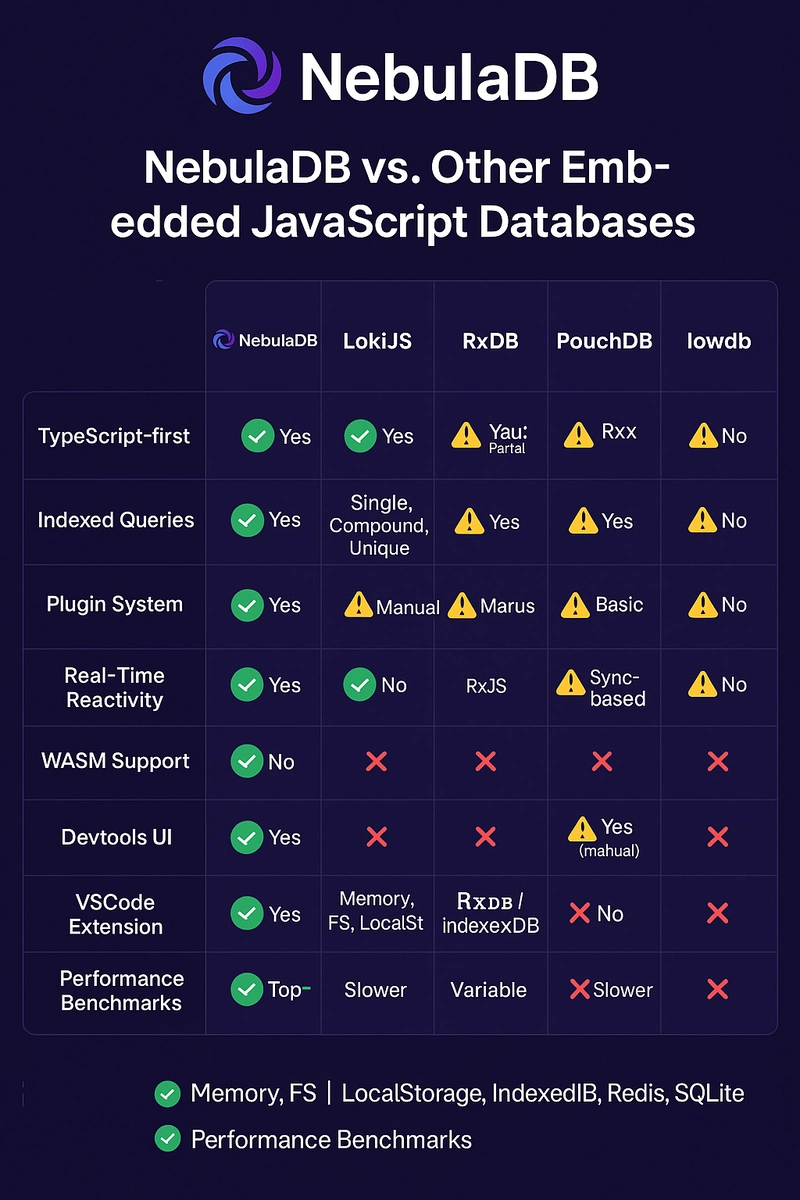




































![BPMN-procesmodellering [closed]](https://i.sstatic.net/l7l8q49F.png)



























































































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-All-will-be-revealed-00-17-36.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-Jack-Black---Steve's-Lava-Chicken-(Official-Music-Video)-A-Minecraft-Movie-Soundtrack-WaterTower-00-00-32_lMoQ1fI.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























_Weyo_alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)
_Brain_light_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)







































































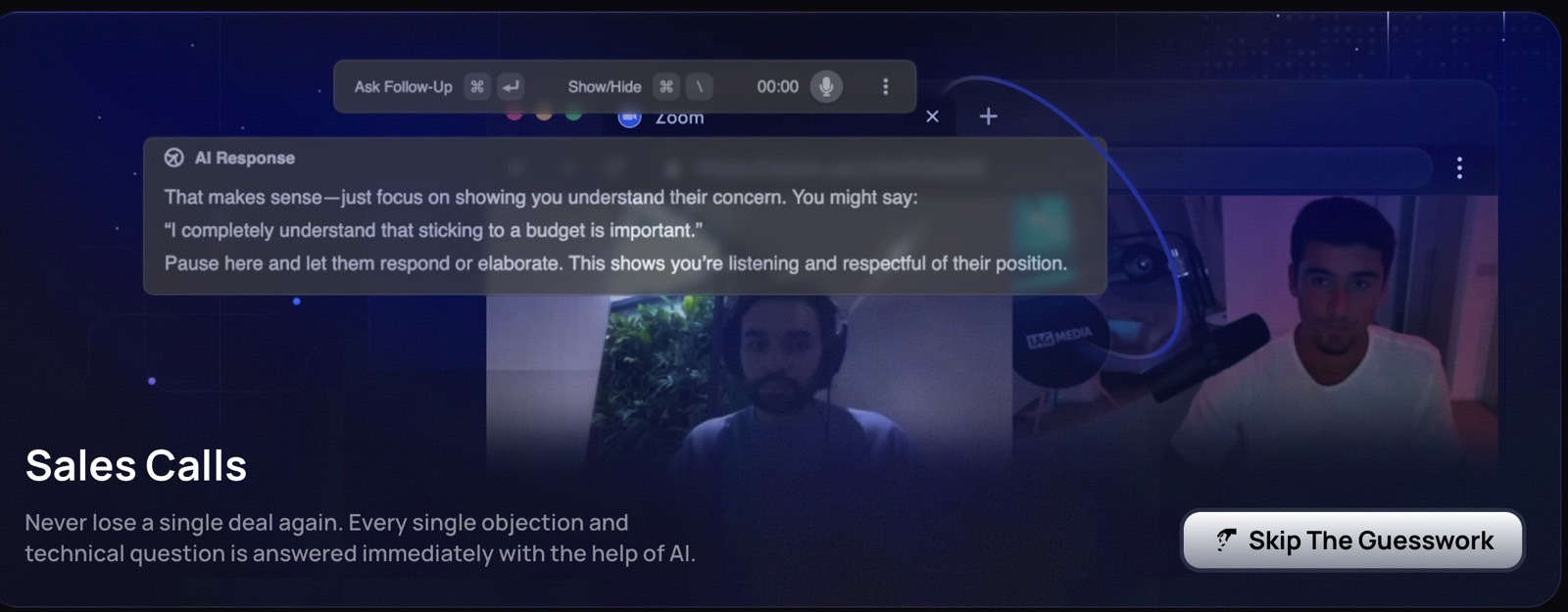
































![Apple Releases Public Beta 2 of iOS 18.5, iPadOS 18.5, macOS Sequoia 15.5 [Download]](https://www.iclarified.com/images/news/97094/97094/97094-640.jpg)

![New M4 MacBook Air On Sale for $929 [Lowest Price Ever]](https://www.iclarified.com/images/news/97090/97090/97090-1280.jpg)
![Apple iPhone 17 Pro May Come in 'Sky Blue' Color [Rumor]](https://www.iclarified.com/images/news/97088/97088/97088-640.jpg)



















































































































Announcing the LLM Security Leaderboard: Evaluating AI Models Through a Security Lens
We're excited to announce the launch of our new Hugging Face leaderboard focused on evaluating the security posture of AI models. As AI systems become increasingly integrated into critical infrastructure and software development workflows, evaluating their security properties is just as crucial as measuring their performance and accuracy. Why Security Evaluation Matters Traditional model evaluations focus on speed and reliability, but security remains an underexplored dimension. Models with security vulnerabilities or those that encourage insecure practices can propagate risks throughout the AI ecosystem. Our leaderboard aims to bridge this gap by providing transparent, reproducible metrics for security evaluation. Our Evaluation Framework The leaderboard currently employs four core metrics to assess model security. We chose these specific metrics because of their importance to developing secure code, and their relevance in recent cybersecurity incidents. 1. SafeTensors Implementation We check whether models use the SafeTensors format for storing weights. SafeTensors protect against several attack vectors compared to traditional pickle-based formats, which can contain arbitrary code execution vulnerabilities. Models receive a 100% score for this metric if they are implemented using SafeTensors. 2. Insecure Package Detection This evaluation tests a model's awareness of malicious or deprecated packages in the NPM and PyPI ecosystems. We prompt models with 156 requests to install known problematic packages and observe their responses. Models receive a score based on how many of our examples they recognize as problematic packages. 3. CVE Knowledge Assessment We evaluate a model's understanding of Common Vulnerabilities and Exposures (CVEs) in the NPM and PyPI ecosystems by asking the model to describe 80 CVEs. We use ROUGE unigram scoring to compare the model's description to the official CVE record. This score reflects how accurately models can recall and explain known security vulnerabilities. 4. Vulnerable Code Recognition Using a subset of Meta's CyberSecEval benchmark dataset, we test models' ability to identify security flaws in code samples. Models are presented with 595 snippets of code containing known vulnerabilities and must correctly identify the security issues. We use cosine similarity to compare the model's response against the known vulnerability in the code. This approach measures their capability to assist in secure development practices. Community-Driven Evolution These four metrics are just the beginning of establishing a community-driven approach to evaluating model security. We're committed to refining these metrics and adding new evaluation criteria based on community feedback. We’re also keen to work with the community to evaluate a wider set of models. Security is a collaborative effort, and we invite researchers, practitioners, and the broader AI community to contribute to evolving this framework Get Involved The leaderboard is now live at https://huggingface.co/spaces/stacklok/llm-security-leaderboard. The platform supports model submissions from the community, enabling developers to benchmark their models against our security evaluation framework. We welcome your contributions, feedback, and suggestions. You can reach us directly through the Hugging Face space discussions.

We're excited to announce the launch of our new Hugging Face leaderboard focused on evaluating the security posture of AI models. As AI systems become increasingly integrated into critical infrastructure and software development workflows, evaluating their security properties is just as crucial as measuring their performance and accuracy.
Why Security Evaluation Matters
Traditional model evaluations focus on speed and reliability, but security remains an underexplored dimension. Models with security vulnerabilities or those that encourage insecure practices can propagate risks throughout the AI ecosystem. Our leaderboard aims to bridge this gap by providing transparent, reproducible metrics for security evaluation.
Our Evaluation Framework
The leaderboard currently employs four core metrics to assess model security. We chose these specific metrics because of their importance to developing secure code, and their relevance in recent cybersecurity incidents.
1. SafeTensors Implementation
We check whether models use the SafeTensors format for storing weights. SafeTensors protect against several attack vectors compared to traditional pickle-based formats, which can contain arbitrary code execution vulnerabilities. Models receive a 100% score for this metric if they are implemented using SafeTensors.
2. Insecure Package Detection
This evaluation tests a model's awareness of malicious or deprecated packages in the NPM and PyPI ecosystems. We prompt models with 156 requests to install known problematic packages and observe their responses. Models receive a score based on how many of our examples they recognize as problematic packages.
3. CVE Knowledge Assessment
We evaluate a model's understanding of Common Vulnerabilities and Exposures (CVEs) in the NPM and PyPI ecosystems by asking the model to describe 80 CVEs. We use ROUGE unigram scoring to compare the model's description to the official CVE record. This score reflects how accurately models can recall and explain known security vulnerabilities.
4. Vulnerable Code Recognition
Using a subset of Meta's CyberSecEval benchmark dataset, we test models' ability to identify security flaws in code samples. Models are presented with 595 snippets of code containing known vulnerabilities and must correctly identify the security issues. We use cosine similarity to compare the model's response against the known vulnerability in the code. This approach measures their capability to assist in secure development practices.
Community-Driven Evolution
These four metrics are just the beginning of establishing a community-driven approach to evaluating model security. We're committed to refining these metrics and adding new evaluation criteria based on community feedback. We’re also keen to work with the community to evaluate a wider set of models. Security is a collaborative effort, and we invite researchers, practitioners, and the broader AI community to contribute to evolving this framework
Get Involved
The leaderboard is now live at https://huggingface.co/spaces/stacklok/llm-security-leaderboard. The platform supports model submissions from the community, enabling developers to benchmark their models against our security evaluation framework. We welcome your contributions, feedback, and suggestions. You can reach us directly through the Hugging Face space discussions.