










































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)





























































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)


































































































































_Piotr_Adamowicz_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)














































































-xl-xl-xl.jpg)










![Walmart’s $30 Google TV streamer is now in stores and it supports USB-C hubs [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/onn-4k-plus-store-reddit.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple to Launch AI-Powered Battery Saver Mode in iOS 19 [Report]](https://www.iclarified.com/images/news/97309/97309/97309-1280.jpg)

![Apple Officially Releases macOS Sequoia 15.5 [Download]](https://www.iclarified.com/images/news/97308/97308/97308-640.jpg)























































































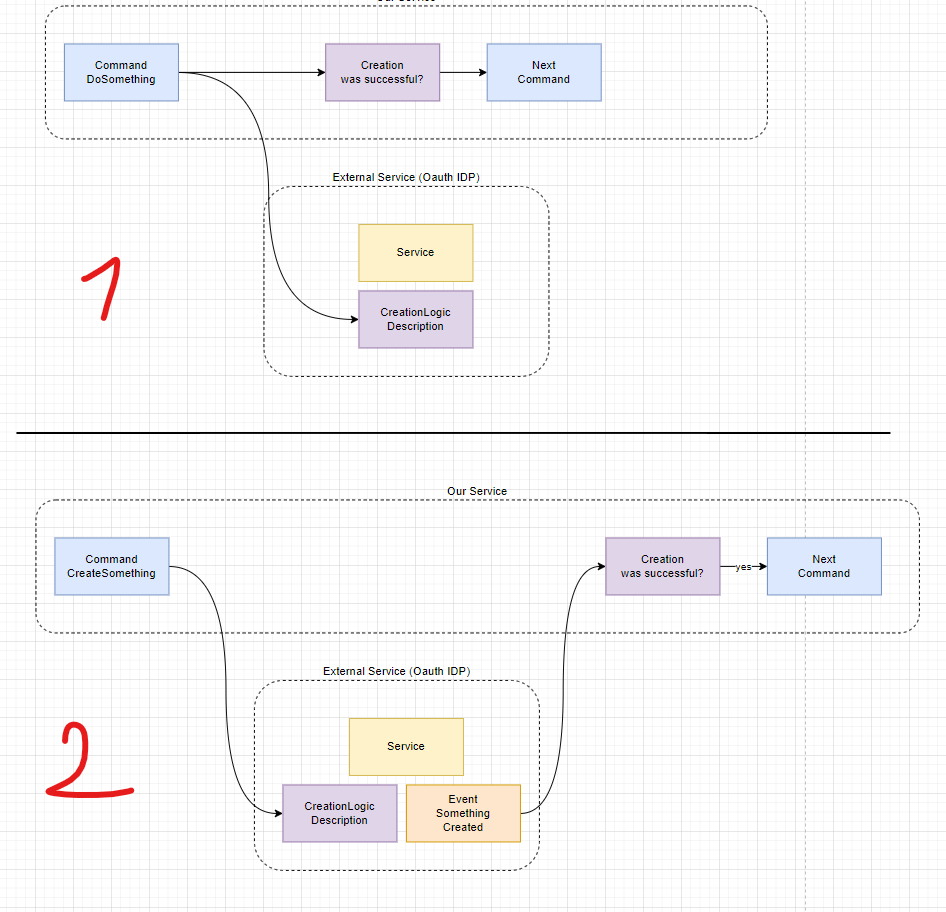
AI Math Skills Stalled: New Test Exposes Weakness, Hints Hurt!
This is a Plain English Papers summary of a research paper called AI Math Skills Stalled: New Test Exposes Weakness, Hints Hurt!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview New benchmark called FormalMATH containing 5,560 verified math problems Problems range from Olympiad to undergraduate level Uses novel human-in-the-loop automation process Current AI models achieve only 16.46% success rate Reveals surprising inverse relationship between natural language hints and proof success Plain English Explanation FormalMATH is like a massive test bank for AI systems trying to solve math problems. Think of it as training grounds where AI can practice formal mathematical reasoning - from high ... Click here to read the full summary of this paper

This is a Plain English Papers summary of a research paper called AI Math Skills Stalled: New Test Exposes Weakness, Hints Hurt!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- New benchmark called FormalMATH containing 5,560 verified math problems
- Problems range from Olympiad to undergraduate level
- Uses novel human-in-the-loop automation process
- Current AI models achieve only 16.46% success rate
- Reveals surprising inverse relationship between natural language hints and proof success
Plain English Explanation
FormalMATH is like a massive test bank for AI systems trying to solve math problems. Think of it as training grounds where AI can practice formal mathematical reasoning - from high ...




