




































































































































































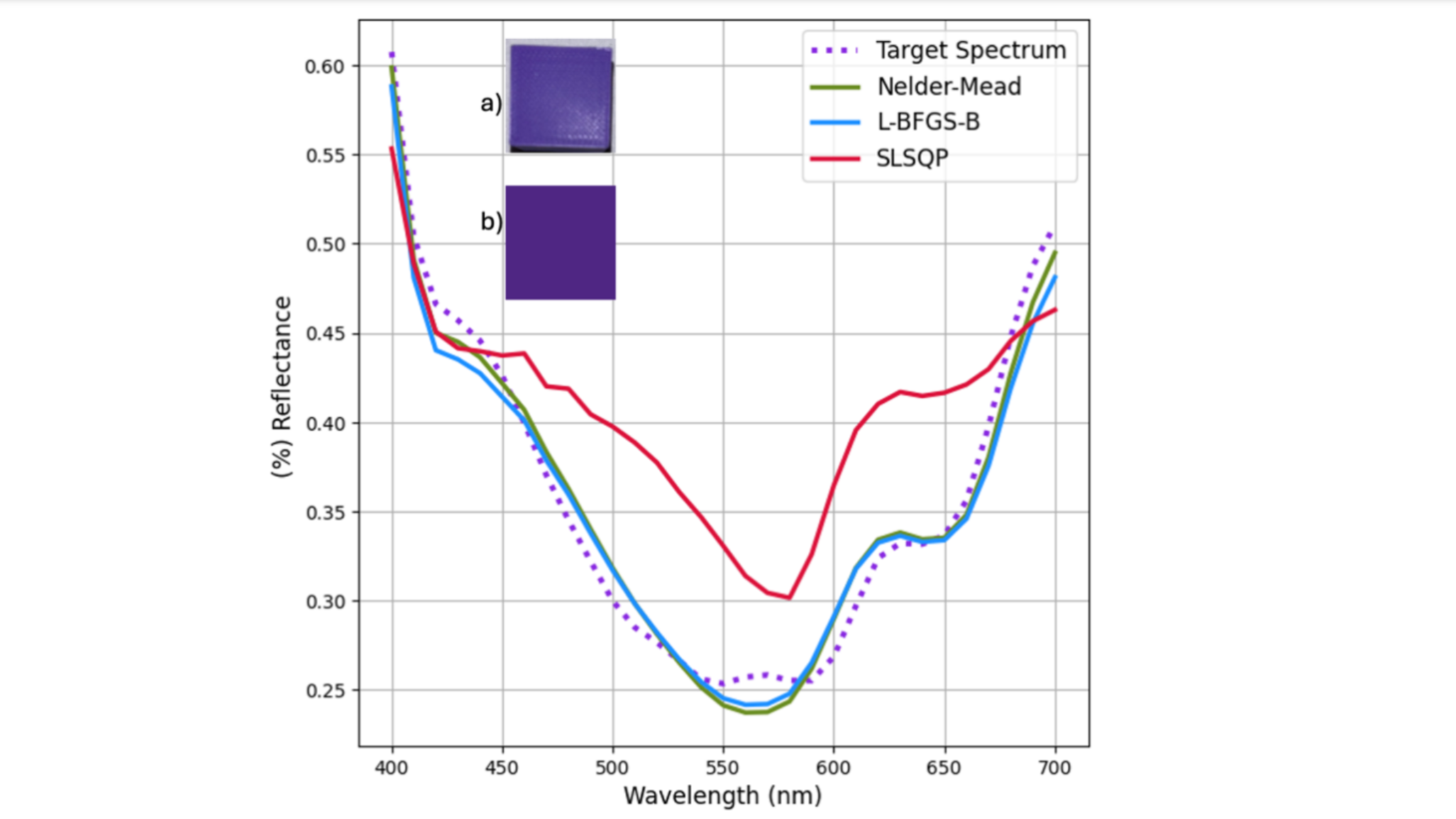
![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)














































































































































































































































































_Muhammad_R._Fakhrurrozi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)







































































































![AirPods Pro 2 With USB-C Back On Sale for Just $169! [Deal]](https://www.iclarified.com/images/news/96315/96315/96315-640.jpg)
![Apple Releases iOS 18.5 Beta 4 and iPadOS 18.5 Beta 4 [Download]](https://www.iclarified.com/images/news/97145/97145/97145-640.jpg)
![Apple Seeds watchOS 11.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97147/97147/97147-640.jpg)
![Apple Seeds visionOS 2.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97150/97150/97150-640.jpg)






























































































A Pitfall: Child Goroutines Causing Service Crashes
Background Recently, during microservice development, I encountered a very dangerous issue. We were using the echo framework, and in a handler, we launched a goroutine via errgroup. However, when a panic occurred inside that goroutine, even though we had added the Recover middleware to protect the service process, the entire service still crashed, causing all users sharing the same server to have their requests aborted. This exposed a very common but easily overlooked pitfall: defer recover cannot handle panics inside child goroutines. Issue Reproduction You can reproduce this behavior by running this code: package main import ( "context" "fmt" "golang.org/x/sync/errgroup" ) func TestPanicRecovered() { defer func() { if r := recover(); r != nil { fmt.Println(r) } }() panic("panic") } func TestPanicRecoverFailed() { defer func() { if r := recover(); r != nil { fmt.Println(r) } }() g, _ := errgroup.WithContext(context.TODO()) g.Go(func() error { panic("panic") }) err := g.Wait() fmt.Println(err) } func main() { TestPanicRecovered() TestPanicRecoverFailed() } In TestPanicRecovered, defer-recover successfully catches the panic. However, in TestPanicRecoverFailed, even with recover placed in the parent goroutine, the panic inside the child goroutine still causes a crash. Why Echo's Recover Middleware Not Work? Let's take a look at Echo’s Recover middleware implementation (source code): // RecoverWithConfig returns a Recover middleware with config. // See: `Recover()`. func RecoverWithConfig(config RecoverConfig) echo.MiddlewareFunc { // Defaults if config.Skipper == nil { config.Skipper = DefaultRecoverConfig.Skipper } if config.StackSize == 0 { config.StackSize = DefaultRecoverConfig.StackSize } return func(next echo.HandlerFunc) echo.HandlerFunc { return func(c echo.Context) (returnErr error) { if config.Skipper(c) { return next(c) } defer func() { if r := recover(); r != nil { if r == http.ErrAbortHandler { panic(r) } err, ok := r.(error) if !ok { err = fmt.Errorf("%v", r) } ... As you can see, it only captures panics that occur inside the current HTTP request goroutine. Panics that occur in child goroutines are completely out of reach of the middleware. According to the official Go documentation: The process continues up the stack until all functions in the current goroutine have returned, at which point the program crashes. A panic can only be recovered inside the same goroutine stack where it occurred. Otherwise, the panic will propagate upward, and eventually cause the entire program to crash. Solution As of April 28, 2025, the latest errgroup still does not automatically recover from panics inside functions, it is still highly recommended to manage goroutines through errgroup (or similar mechanisms) in your handler. This way, you can easily wrap each task with a recover mechanism, ensuring graceful error handling. The official errgroup has already fixed this issue in the master branch, but the fix has not been officially released yet. In the meantime, you can check out my safegroup. It automatically wraps each task with a safe recover mechanism and provides a type-safe way to handle panic errors.

Background
Recently, during microservice development, I encountered a very dangerous issue. We were using the echo framework, and in a handler, we launched a goroutine via errgroup. However, when a panic occurred inside that goroutine, even though we had added the Recover middleware to protect the service process, the entire service still crashed, causing all users sharing the same server to have their requests aborted.
This exposed a very common but easily overlooked pitfall:
defer recovercannot handle panics inside child goroutines.
Issue Reproduction
You can reproduce this behavior by running this code:
package main
import (
"context"
"fmt"
"golang.org/x/sync/errgroup"
)
func TestPanicRecovered() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
panic("panic")
}
func TestPanicRecoverFailed() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
g, _ := errgroup.WithContext(context.TODO())
g.Go(func() error {
panic("panic")
})
err := g.Wait()
fmt.Println(err)
}
func main() {
TestPanicRecovered()
TestPanicRecoverFailed()
}
In TestPanicRecovered, defer-recover successfully catches the panic. However, in TestPanicRecoverFailed, even with recover placed in the parent goroutine, the panic inside the child goroutine still causes a crash.
Why Echo's Recover Middleware Not Work?
Let's take a look at Echo’s Recover middleware implementation (source code):
// RecoverWithConfig returns a Recover middleware with config.
// See: `Recover()`.
func RecoverWithConfig(config RecoverConfig) echo.MiddlewareFunc {
// Defaults
if config.Skipper == nil {
config.Skipper = DefaultRecoverConfig.Skipper
}
if config.StackSize == 0 {
config.StackSize = DefaultRecoverConfig.StackSize
}
return func(next echo.HandlerFunc) echo.HandlerFunc {
return func(c echo.Context) (returnErr error) {
if config.Skipper(c) {
return next(c)
}
defer func() {
if r := recover(); r != nil {
if r == http.ErrAbortHandler {
panic(r)
}
err, ok := r.(error)
if !ok {
err = fmt.Errorf("%v", r)
}
...
As you can see, it only captures panics that occur inside the current HTTP request goroutine. Panics that occur in child goroutines are completely out of reach of the middleware.
According to the official Go documentation:
The process continues up the stack until all functions in the current goroutine have returned, at which point the program crashes.
A panic can only be recovered inside the same goroutine stack where it occurred. Otherwise, the panic will propagate upward, and eventually cause the entire program to crash.
Solution
As of April 28, 2025, the latest
errgroupstill does not automatically recover from panics inside functions, it is still highly recommended to manage goroutines througherrgroup(or similar mechanisms) in your handler. This way, you can easily wrap each task with a recover mechanism, ensuring graceful error handling.The official errgroup has already fixed this issue in the master branch, but the fix has not been officially released yet.
In the meantime, you can check out my safegroup. It automatically wraps each task with a safe
recovermechanism and provides a type-safe way to handlepanicerrors.




