



































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)











































































































































































































































































_Muhammad_R._Fakhrurrozi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




















































































![macOS 15.5 beta 4 now available for download [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/macOS-Sequoia-15.5-b4.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)















![AirPods Pro 2 With USB-C Back On Sale for Just $169! [Deal]](https://www.iclarified.com/images/news/96315/96315/96315-640.jpg)
![Apple Releases iOS 18.5 Beta 4 and iPadOS 18.5 Beta 4 [Download]](https://www.iclarified.com/images/news/97145/97145/97145-640.jpg)
![Apple Seeds watchOS 11.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97147/97147/97147-640.jpg)
![Apple Seeds visionOS 2.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97150/97150/97150-640.jpg)





































![Apple Seeds Fourth Beta of iOS 18.5 to Developers [Update: Public Beta Available]](https://images.macrumors.com/t/uSxxRefnKz3z3MK1y_CnFxSg8Ak=/2500x/article-new/2025/04/iOS-18.5-Feature-Real-Mock.jpg)
![Apple Seeds Fourth Beta of macOS Sequoia 15.5 [Update: Public Beta Available]](https://images.macrumors.com/t/ne62qbjm_V5f4GG9UND3WyOAxE8=/2500x/article-new/2024/08/macOS-Sequoia-Night-Feature.jpg)






















































When OpenAI Isn’t Always the Answer: Enterprise Risks Behind Wrapper-Based AI Agents
Data privacy, compliance, and trust gaps in today’s AI agent integrations The post When OpenAI Isn’t Always the Answer: Enterprise Risks Behind Wrapper-Based AI Agents appeared first on Towards Data Science.

“Wait… are you sending journal entries to OpenAI?”
I shrugged.
“It was an AI-themed hackathon, I had to build something fast.”
She didn’t miss a beat:
“Sure. But how do I trust what you built? Why not self-host your own LLM?”
That stopped me cold.
I was proud of how quickly the app came together. But that single question, and the ones that followed unraveled everything I thought I knew about building responsibly with AI. The hackathon judges flagged it too.
That moment made me realize how casually we treat trust when building with AI, especially with tools that handle sensitive data.
I realized something bigger:
We don’t talk enough about trust when building with AI.
Her answer stuck with me. Georgia von Minden is a data scientist at the ACLU, where she works closely with issues around personally identifiable information in legal and civil rights contexts. I’ve always valued her insight, but this conversation hit different.
So I asked her to elaborate more what does trust really mean in this context? especially when AI systems handle personal data.
She told me:
“Trust can be hard to pin down, but data governance is a good place to begin. Who has the data, how it’s stored, and what it’s used for all matter. Ten years ago, I would have answered this differently. But today, with huge computing power and massive data stores, large-scale inference is a real concern. OpenAI has significant access to both compute and data, and their lack of transparency makes it reasonable to be cautious.
When it comes to personally identifiable information, regulations and common sense both point to the need for strong data governance. Sending PII in API calls isn’t just risky — it could also violate those rules and expose individuals to harm.”
It reminded me that when we build with AI, especially systems that touch sensitive human data, we aren’t just writing code.
We’re making decisions about privacy, power, and trust.
The moment you collect user data, especially something as personal as journal entries, you’re stepping into a space of responsibility. It’s not just about what your model can do. It’s about what happens to that data, where it goes, and who has access to it.
The Illusion of Simplicity
Today, it’s easier than ever to spin up something that looks intelligent. With OpenAI or other LLMs, developers can build AI tools in hours. Startups can launch “AI-powered” features overnight. And enterprises? They’re rushing to integrate these agents into their workflows.
But in all that excitement, one thing often gets overlooked: trust.
When people talk about AI Agents, they’re often referring to lightweight wrappers around LLMs. These agents might answer questions, automate tasks, or even make decisions. But many are built hastily, with little thought given to security, compliance, or accountability.
Just because a product uses OpenAI doesn’t mean it’s safe. What you’re really trusting is the whole pipeline:
- Who built the wrapper?
- How is your data being handled?
- Is your information stored, logged — or worse, leaked?
I’ve been using the OpenAI API for client use cases myself. Recently, I was offered free access to the API — up to 1 million tokens daily until the end of April — if I agreed to share my prompt data.

(Image by Author)
I almost opted in for a personal side project, but then it hit me: if a solution provider accepted that same deal to cut costs, their users would have no idea their data was being shared. On a personal level, that might seem harmless. But in an enterprise context? That’s a serious breach of privacy, and possibly of contractual or regulatory obligations.
All it takes is one engineer saying “yes” to a deal like that, and your customer data is in someone else’s hands.

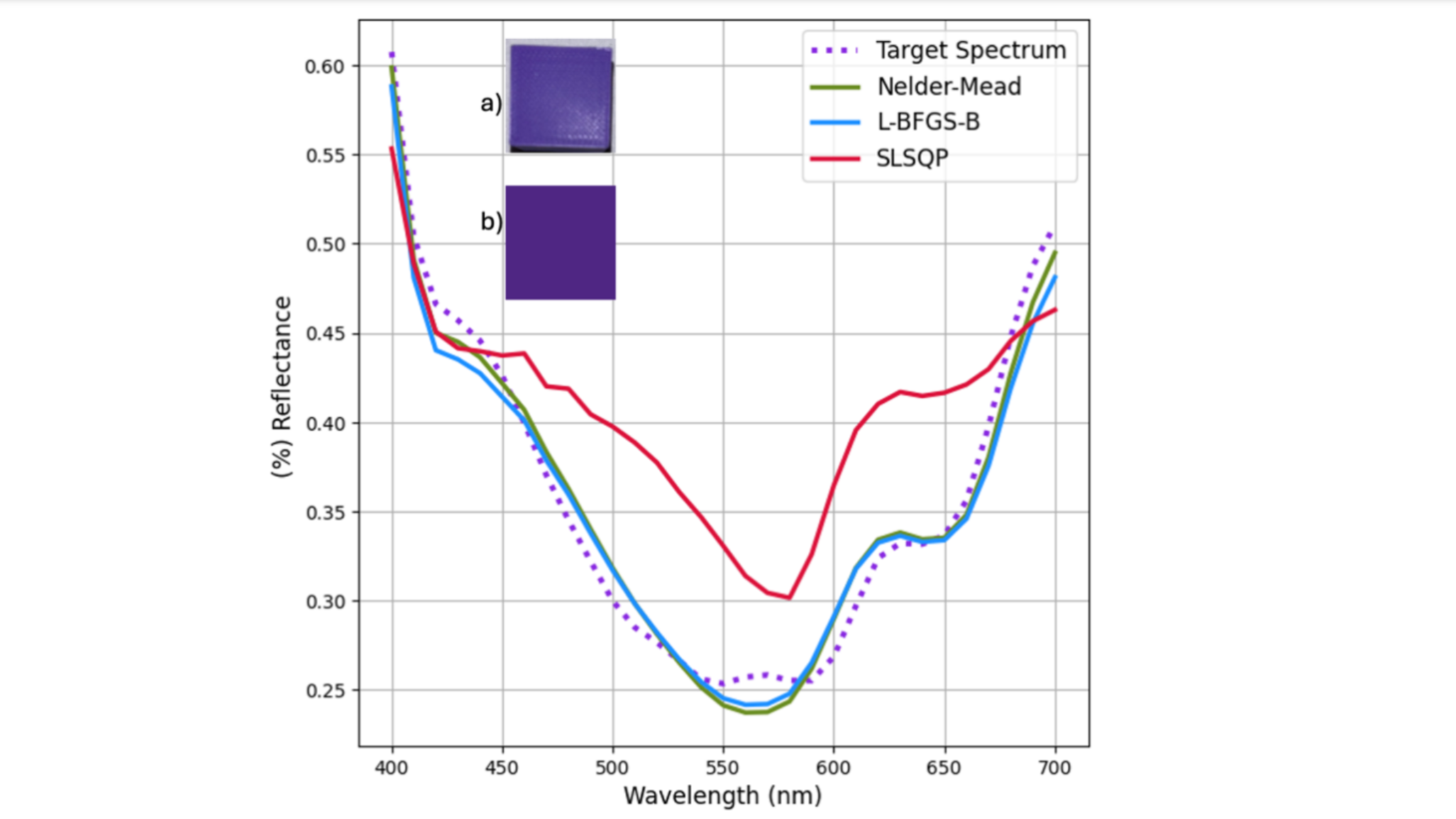
(Image by Author)
Enterprise AI Raises the Stakes
I’m seeing more SaaS companies and devtool startups experiment with AI agents. Some are getting it right. Some AI Agents let you bring their own LLM, giving them control over where the model runs and how data is handled.
That’s a thoughtful approach: you define the trust boundaries.
But not everyone is so careful.
Many companies just plug into OpenAI’s API, add a few buttons, and call it “enterprise-ready.”
Spoiler: it’s not.
What Can Go Wrong? A Lot.
If you’re integrating AI agents into your stack without asking hard questions, here’s what’s at risk:
- Data leakage: Your prompts might include sensitive customer data, API keys, or internal logic — and if that’s sent to a third-party model, it could be exposed.
In 2023, Samsung engineers unknowingly pasted internal source code and notes into ChatGPT (Forbes). That data could now be part of future training sets — a major risk for intellectual property. - Compliance violations: Sending personally identifiable information (PII) through a model like OpenAI without proper controls can violate GDPR, HIPAA, or your own contracts.
Elon Musk’s company X learned that the hard way. They launched their AI chatbot “Grok” by using all user posts including from EU users to train it, without proper opt-in. Regulators stepped in quickly. Under pressure, they paused Grok’s training in the EU (Politico). - Opaque behavior: Non-deterministic agents are hard to debug or explain. What happens when a client asks why a chatbot gave a wrong recommendation or exposed something confidential? You need transparency to answer that — and many agents today don’t offer it.
- Data ownership confusion: Who owns the output? Who logs the data? Does your provider retrain on your inputs?
Zoom was caught doing exactly that in 2023. They quietly changed their Terms of Service to allow customer meeting data to be used for AI training (Fast Company). After public backlash, they reversed the policy but it was a reminder that trust can be lost overnight. - Security oversights in wrappers: In 2024, Flowise — a popular low-code LLM orchestration tool — was found to have dozens of deployments left exposed to the internet, many without authentication (Cybersecurity News). Researchers discovered API keys, database credentials, and user data sitting in the open. That’s not an OpenAI problem — that’s a builder problem. But end users still pay the price.
- AI features that go too far: Microsoft’s “Recall” feature — part of their Copilot rollout — took automatic screenshots of users’ activity to help the AI assistant answer questions (DoublePulsar). It sounded helpful… until security professionals flagged it as a privacy nightmare. Microsoft had to quickly backpedal and make the feature opt-in only.
Not Everything Needs to Be OpenAI
OpenAI is incredibly powerful. But it’s not always the right answer.
Sometimes a smaller, local model is more than enough. Sometimes rule-based logic does the job better. And often, the most secure option is one that runs entirely within your infrastructure, under your rules.
We shouldn’t blindly connect an LLM and label it a “smart assistant.”
In the enterprise, trust, transparency, and control aren’t optional — they’re essential.
There’s a growing number of platforms enabling that kind of control. Salesforce’s Einstein 1 Studio now supports bring-your-own-model, letting you connect your own LLM from AWS or Azure. IBM’s Watson lets enterprises deploy models internally with full audit trails. Databricks, with MosaicML, lets you train private LLMs inside your own cloud, so your sensitive data never leaves your infrastructure.
That’s what real enterprise AI should look like.
Bottom Line
AI agents are powerful. They unlock workflows and automations we couldn’t do before. But ease of development doesn’t mean it’s safe, especially when handling sensitive data at scale.
Before you roll out that shiny new agent, ask yourself:
- Who controls the model?
- Where is the data going?
- Are we compliant?
- Can we audit what it’s doing?
In the age of AI, the biggest risk isn’t bad technology.
It’s blind trust.
About the Author
I’m Ellen, a machine learning engineer with 6 years of experience, currently working at a fintech startup in San Francisco. My background spans data science roles in oil & gas consulting, as well as leading AI and data training programs across APAC, the Middle East, and Europe.
I’m currently completing my Master’s in Data Science (graduating May 2025) and actively looking for my next opportunity as a machine learning engineer. If you’re open to referring or connecting, I’d truly appreciate it!
I love creating real-world impact through AI and I’m always open to project-based collaborations as well.
Check out my portfolio: liviaellen.com/portfolio
My Previous AR Works: liviaellen.com/ar-profile
Support my work with a coffee: https://ko-fi.com/liviaellen
The post When OpenAI Isn’t Always the Answer: Enterprise Risks Behind Wrapper-Based AI Agents appeared first on Towards Data Science.


