
























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)





































































































































































































![GrandChase tier list of the best characters available [April 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)










































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)





































































































![Global security vulnerability database gets 11 more months of funding [u]](https://photos5.appleinsider.com/gallery/63338-131616-62453-129471-61060-125967-51013-100774-49862-97722-Malware-Image-xl-xl-xl-(1)-xl-xl.jpg)
























![Apple Shares New 'Mac Does That' Ads for MacBook Pro [Video]](https://www.iclarified.com/images/news/97055/97055/97055-640.jpg)

![Apple Releases tvOS 18.4.1 for Apple TV [Download]](https://www.iclarified.com/images/news/97047/97047/97047-640.jpg)
![Apple Releases macOS Sequoia 15.4.1 [Download]](https://www.iclarified.com/images/news/97049/97049/97049-640.jpg)



















































































































When One Tech Stack Isn’t Enough: Orchestrating a Multi-Language Pipeline with Local FaaS
Hi, my name is Andrew! I oversee a large-scale online service where our queues (Kafka or similar) process millions of events each day. We have to spot anomalies quickly, track key metrics, and notify the team about critical issues—all in real time. Because data streams in from various systems, it’s never as simple as using one language or tool. Some engineers favor Go for performance and concurrency, others prefer Python for machine learning, and Node.js often wins for handling external integrations (Slack, webhooks, etc.). On top of that, our DevOps folks rely heavily on classic CLI tools like tar and gzip for archiving logs. At first, everything was scattered across different scripts, containers, and services. It worked, but it got messy—too many handoffs, too many config files, and a constant risk of something breaking when one team decided to update their part of the puzzle. So we decided to unify the entire process in one computational graph. The solution we came up with is a local-first FaaS approach where each “node” can be written in whatever language or tool we want, but everything is orchestrated under a single workflow. Below is how we designed each node in our real-time pipeline, why we chose each language or tool, and how data flows between them via simple JSON adapters. Node 1 (Rust): High-Performance Ingestion Why Rust? We needed maximum throughput and memory safety. Our ingestion service handles hundreds of thousands of events per minute from sources like IoT devices and microservices in our cluster. Rust’s ownership model helps avoid memory leaks and race conditions, which is crucial when your service runs 24/7. Example Rust code (node_rust_ingest.rs): use std::fs; use serde::{Deserialize, Serialize}; #[derive(Deserialize)] struct IngestConfig { pub source_path: String, } fn main() -> Result { // Read config from JSON let config_data = fs::read_to_string("config.json")?; let config: IngestConfig = serde_json::from_str(&config_data)?; // Imagine reading from a high-volume stream here: let raw_events = vec![ "temperature:24.5 sensor_id=alpha", "temperature:25.1 sensor_id=beta", ]; // Convert the raw events into JSON and save let json_str = serde_json::to_string_pretty(&raw_events)?; fs::write("raw_events.json", json_str)?; Ok(()) } Input: A JSON file named config.json (handled by an adapter, e.g., adapter_input_json("config.json")). Output: raw_events.json with the raw events. In practice, this Rust code might pull real messages from Kafka or a custom TCP socket, but the idea is the same: read something from a stream, then write it out as JSON. Node 2 (Go): Filtering and Normalization Why Go? It’s great for concurrency (goroutines and channels) and compiles into a single binary we can deploy anywhere. This node focuses on quick filtering of raw data, dropping empty or invalid records, and transforming some fields before sending them off for deeper analysis. Example Go code (node_go_filter.go): package main import ( "encoding/json" "fmt" "io/ioutil" "os" "strings" ) type FilteredEvent struct { Valid bool `json:\"valid\"` Data string `json:\"data\"` } func main() { // Read raw events JSON from file (adapter does the path resolution) rawData, err := ioutil.ReadFile(\"raw_events.json\") if err != nil { fmt.Println(\"Error reading file:\", err) os.Exit(1) } var events []string if err := json.Unmarshal(rawData, &events); err != nil { fmt.Println(\"Error unmarshalling JSON:\", err) os.Exit(1) } // Filter out any malformed or empty events var filtered []FilteredEvent for _, e := range events { if strings.TrimSpace(e) == \"\" { continue } filtered = append(filtered, FilteredEvent{ Valid: true, Data: e, }) } // Write filtered events out to JSON output, err := json.MarshalIndent(filtered, \"\", \" \") if err != nil { fmt.Println(\"Error marshalling JSON:\", err) os.Exit(1) } if err := ioutil.WriteFile(\"filtered_events.json\", output, 0644); err != nil { fmt.Println(\"Error writing file:\", err) os.Exit(1) } } Input: raw_events.json. Output: filtered_events.json with an array of cleaned-up records. Node 3 (Python): ML Classification Why Python? Most data science and ML teams rely on Python’s ecosystem (NumPy, scikit-learn, PyTorch, etc.). It’s easy to iterate quickly and load pretrained models. Example Python code (node_python_ml.py): import json def main(): # Load filtered events from JSON with open('filtered_events.json', 'r') as f: filtered_data = json.load(f) # Imagine we have a pre-trained model loaded here # For illustration, let's just mock predictions predicted_events = [] for i

Hi, my name is Andrew! I oversee a large-scale online service where our queues (Kafka or similar) process millions of events each day. We have to spot anomalies quickly, track key metrics, and notify the team about critical issues—all in real time. Because data streams in from various systems, it’s never as simple as using one language or tool. Some engineers favor Go for performance and concurrency, others prefer Python for machine learning, and Node.js often wins for handling external integrations (Slack, webhooks, etc.). On top of that, our DevOps folks rely heavily on classic CLI tools like tar and gzip for archiving logs.
At first, everything was scattered across different scripts, containers, and services. It worked, but it got messy—too many handoffs, too many config files, and a constant risk of something breaking when one team decided to update their part of the puzzle. So we decided to unify the entire process in one computational graph. The solution we came up with is a local-first FaaS approach where each “node” can be written in whatever language or tool we want, but everything is orchestrated under a single workflow. Below is how we designed each node in our real-time pipeline, why we chose each language or tool, and how data flows between them via simple JSON adapters.
Node 1 (Rust): High-Performance Ingestion
Why Rust?
We needed maximum throughput and memory safety. Our ingestion service handles hundreds of thousands of events per minute from sources like IoT devices and microservices in our cluster. Rust’s ownership model helps avoid memory leaks and race conditions, which is crucial when your service runs 24/7.
Example Rust code (node_rust_ingest.rs):
use std::fs;
use serde::{Deserialize, Serialize};
#[derive(Deserialize)]
struct IngestConfig {
pub source_path: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Read config from JSON
let config_data = fs::read_to_string("config.json")?;
let config: IngestConfig = serde_json::from_str(&config_data)?;
// Imagine reading from a high-volume stream here:
let raw_events = vec![
"temperature:24.5 sensor_id=alpha",
"temperature:25.1 sensor_id=beta",
];
// Convert the raw events into JSON and save
let json_str = serde_json::to_string_pretty(&raw_events)?;
fs::write("raw_events.json", json_str)?;
Ok(())
}
-
Input: A JSON file named
config.json(handled by an adapter, e.g.,adapter_input_json("config.json")). -
Output:
raw_events.jsonwith the raw events.
In practice, this Rust code might pull real messages from Kafka or a custom TCP socket, but the idea is the same: read something from a stream, then write it out as JSON.
Node 2 (Go): Filtering and Normalization
Why Go?
It’s great for concurrency (goroutines and channels) and compiles into a single binary we can deploy anywhere. This node focuses on quick filtering of raw data, dropping empty or invalid records, and transforming some fields before sending them off for deeper analysis.
Example Go code (node_go_filter.go):
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"os"
"strings"
)
type FilteredEvent struct {
Valid bool `json:\"valid\"`
Data string `json:\"data\"`
}
func main() {
// Read raw events JSON from file (adapter does the path resolution)
rawData, err := ioutil.ReadFile(\"raw_events.json\")
if err != nil {
fmt.Println(\"Error reading file:\", err)
os.Exit(1)
}
var events []string
if err := json.Unmarshal(rawData, &events); err != nil {
fmt.Println(\"Error unmarshalling JSON:\", err)
os.Exit(1)
}
// Filter out any malformed or empty events
var filtered []FilteredEvent
for _, e := range events {
if strings.TrimSpace(e) == \"\" {
continue
}
filtered = append(filtered, FilteredEvent{
Valid: true,
Data: e,
})
}
// Write filtered events out to JSON
output, err := json.MarshalIndent(filtered, \"\", \" \")
if err != nil {
fmt.Println(\"Error marshalling JSON:\", err)
os.Exit(1)
}
if err := ioutil.WriteFile(\"filtered_events.json\", output, 0644); err != nil {
fmt.Println(\"Error writing file:\", err)
os.Exit(1)
}
}
-
Input:
raw_events.json. -
Output:
filtered_events.jsonwith an array of cleaned-up records.
Node 3 (Python): ML Classification
Why Python?
Most data science and ML teams rely on Python’s ecosystem (NumPy, scikit-learn, PyTorch, etc.). It’s easy to iterate quickly and load pretrained models.
Example Python code (node_python_ml.py):
import json
def main():
# Load filtered events from JSON
with open('filtered_events.json', 'r') as f:
filtered_data = json.load(f)
# Imagine we have a pre-trained model loaded here
# For illustration, let's just mock predictions
predicted_events = []
for item in filtered_data:
data_str = item['data']
# Some ML logic here...
prediction = 'normal'
if 'sensor_id=beta' in data_str:
prediction = 'warning' # as an example
predicted_events.append({
'data': data_str,
'prediction': prediction
})
# Save predictions to JSON
with open('predicted_events.json', 'w') as f:
json.dump(predicted_events, f, indent=2)
if __name__ == '__main__':
main()
-
Input:
filtered_events.json. -
Output:
predicted_events.jsonwith apredictionfield for each record.
In a real scenario, you might load a Torch or TensorFlow model and do actual inference. The concept stays the same: read JSON, process, write JSON.
Node 4 (Node.js): External Service Notifications
Why Node.js?
We use it for real-time hooks (Slack notifications, webhooks, etc.), thanks to its event-driven nature and wide range of packages on npm.
Example JavaScript code (node_js_notify.js):
const fs = require('fs');
const axios = require('axios'); // For sending data to a webhook, Slack, etc.
async function main() {
// Read the predicted events JSON
const rawData = fs.readFileSync('predicted_events.json', 'utf8');
const predictedEvents = JSON.parse(rawData);
// For each event, if it's a warning, send an alert
for (const event of predictedEvents) {
if (event.prediction === 'warning') {
await sendAlert(event.data);
}
}
}
async function sendAlert(data) {
// Example: post to Slack (replace with your actual webhook)
const slackWebhook = 'https://hooks.slack.com/services/your/webhook/url';
await axios.post(slackWebhook, {
text: `Alert! Check sensor data: ${data}`
});
console.log('Alert sent to Slack for:', data);
}
main().catch(err => {
console.error('Error sending alerts:', err);
process.exit(1);
});
-
Input:
predicted_events.json. - Output: Not necessarily a JSON output (though you could log to a file). Typically, it just triggers external actions.
Node 5 (Shell Script): Archiving Logs
Why Shell/CLI?
Classic tools like tar and gzip are reliable workhorses. There’s no need to rewrite them in some other language. They’ve been proven in production for decades.
Example Shell script (node_shell_archive.sh):
#!/usr/bin/env bash
# We assume raw_events.json, filtered_events.json, predicted_events.json
# are present in the current directory. We'll archive them together.
ARCHIVE_NAME="events_archive.tar.gz"
tar -czf "$ARCHIVE_NAME" raw_events.json filtered_events.json predicted_events.json
echo "Archive created: $ARCHIVE_NAME"
- Input: The JSON files we produced in the previous steps.
-
Output:
events_archive.tar.gz, ready to be stored or uploaded to a long-term storage solution.
The Role of Data Adapters
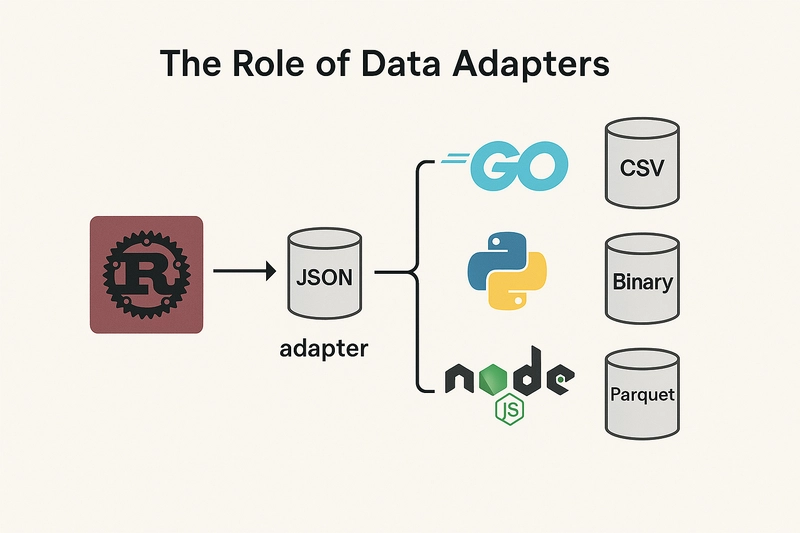
In our setup, each node declares what type of data it expects to read and what it produces. But instead of tying every node to a single format like JSON, we rely on adapters to handle the actual loading and saving of data in the target language. An adapter is just a small function or library call that knows how to read or write a specific data type (files, streams, binary formats, you name it) within a particular runtime.
-
Example:
-
adapter_input_json("filtered_events.json")might parse a JSON file into native objects in Python or Go. -
adapter_output_csv("results.csv")could serialize an array of events into a CSV string and save it.
-
The beauty of this approach is that each node can seamlessly work with different data representations, as long as there’s an adapter for them. Whether you prefer JSON, CSV, binary blobs, or even specialized formats (like Parquet or Avro), adapters keep the underlying implementation details out of the node’s logic. That way, Rust stays focused on ingestion performance, Python remains laser-focused on ML tasks, and Node.js is free to handle whatever output format suits your external APIs—without forcing the entire pipeline to stick to one rigid standard.
Final Thoughts
By unifying everything into a single computational graph and adopting a local FaaS mindset, we drastically reduced the friction between teams. The Rust folks can keep optimizing throughput without breaking anything downstream, Go developers can refine their filtering logic, Python ML engineers can retrain or tweak models, and our Node.js layer can easily tie into Slack. Even our DevOps guys are happy to keep using battle-tested CLI tools for archives.
Before we set this up, we spent way too much time managing glue code and random integration points. Now, each team can just focus on their own node, with minimal dependencies on everyone else. If you’re dealing with a multi-language environment—or foresee that one tool won’t suffice for your entire pipeline—this sort of local-first FaaS approach might be exactly what you need.