





















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)


















































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)




































































































































































































![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)
















































































































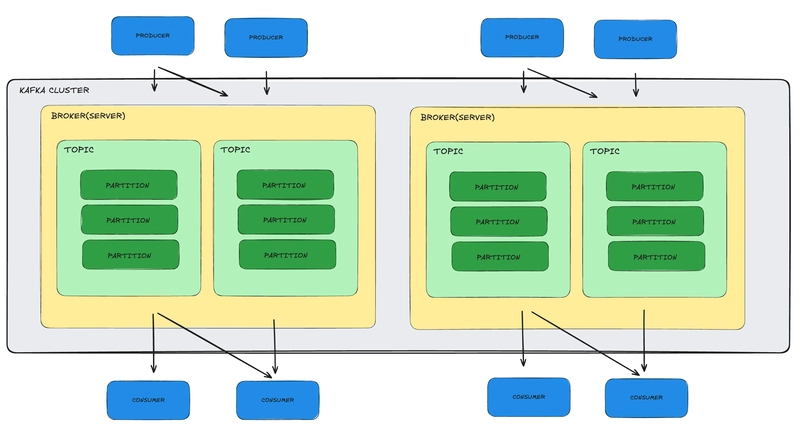
Understanding Apache Kafka: Topics, Partitions, Brokers,
Introduction In this post, we're going to take a deeper dive into Apache Kafka. If you'd like an introduction to Event-Driven Architectures, feel free to check out my previous article. Kafka is a powerful stream processing tool. It's like a super efficient digital post office for real time data. Instead of sending single letters, it handles streams of messages (like a continuous flow of packages) between different applications or systems. It's designed to be incredibly fast, reliable, and can manage huge amounts of data, making it perfect for things like tracking user activity on a website, processing financial transactions, or collecting data from sensors. Concept Description Producer Sends data or publishes messages to Kafka. Consumer Reads or subscribes to data from Kafka to process it. Multiple consumers can subscribe to the same data. Topic a specific channel or a category where different kinds of data are organized(like a queue). It's like having different mailboxes in a post office, each labeled for a particular type of mail. Producers send their messages to a specific topic, and consumers who are interested in that type of data will subscribe to that particular topic to receive the messages. Partition A physical division of a Topic. Messages within a Topic are split into Partitions for scalability and parallel processing. This division allows Kafka to handle more data and process it faster because different parts of the data can be processed at the same time. Broker A Kafka server responsible for storing topic partitions and handling read and write requests from producers and consumers. Cluster A group of Kafka brokers working together to provide fault tolerance and high availability. Zookeeper A centralized service used for coordinating the Kafka cluster (configuration, synchronization, and group services; optional in newer versions). Kafka newer versions (2.8+) started moving away from Zookeeper, they introduced KRaft Mode, meaning Kafka can now manage itself without needing Zookeeper. Example of topic and partition to understand it better. A topic is like a book (it’s about a single subject — "Orders"). Partitions are chapters of the same book, breaking the content into smaller pieces so people can read/write different parts at the same time. Multiple topics would be different books ("Orders", "Payments", "Shipments"). Why Partitions Matter? Scalability: More partitions = more parallelism = faster reading/writing. Ordering: Kafka guarantees that messages will stay in order inside a single partition. But across different partitions, Kafka does not guarantee order. Persistance: Messages are kept for a configured time, even after being read. Fault tolerance: Kafka replicates each partition, copies are made and stored on other brokers (servers). How? Each partition has a leader broker that handles writes/reads. Another broker acts as a follower (replica) to back up the partition.
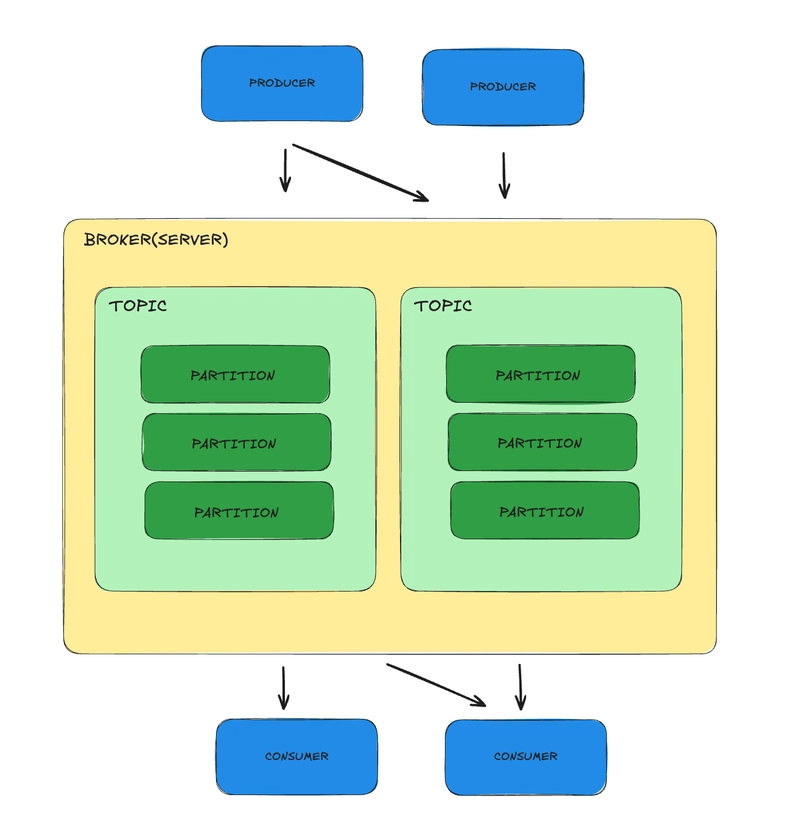
Introduction
In this post, we're going to take a deeper dive into Apache Kafka. If you'd like an introduction to Event-Driven Architectures, feel free to check out my previous article.
Kafka is a powerful stream processing tool. It's like a super efficient digital post office for real time data. Instead of sending single letters, it handles streams of messages (like a continuous flow of packages) between different applications or systems. It's designed to be incredibly fast, reliable, and can manage huge amounts of data, making it perfect for things like tracking user activity on a website, processing financial transactions, or collecting data from sensors.
| Concept | Description |
|---|---|
| Producer | Sends data or publishes messages to Kafka. |
| Consumer | Reads or subscribes to data from Kafka to process it. Multiple consumers can subscribe to the same data. |
| Topic | a specific channel or a category where different kinds of data are organized(like a queue). It's like having different mailboxes in a post office, each labeled for a particular type of mail. Producers send their messages to a specific topic, and consumers who are interested in that type of data will subscribe to that particular topic to receive the messages. |
| Partition | A physical division of a Topic. Messages within a Topic are split into Partitions for scalability and parallel processing. This division allows Kafka to handle more data and process it faster because different parts of the data can be processed at the same time. |
| Broker | A Kafka server responsible for storing topic partitions and handling read and write requests from producers and consumers. |
| Cluster | A group of Kafka brokers working together to provide fault tolerance and high availability. |
| Zookeeper | A centralized service used for coordinating the Kafka cluster (configuration, synchronization, and group services; optional in newer versions). Kafka newer versions (2.8+) started moving away from Zookeeper, they introduced KRaft Mode, meaning Kafka can now manage itself without needing Zookeeper. |
Example of topic and partition to understand it better.
A topic is like a book (it’s about a single subject — "Orders").
Partitions are chapters of the same book, breaking the content into smaller pieces so people can read/write different parts at the same time.
Multiple topics would be different books ("Orders", "Payments", "Shipments").
Why Partitions Matter?
- Scalability: More partitions = more parallelism = faster reading/writing.
- Ordering: Kafka guarantees that messages will stay in order inside a single partition. But across different partitions, Kafka does not guarantee order.
- Persistance: Messages are kept for a configured time, even after being read.
- Fault tolerance: Kafka replicates each partition, copies are made and stored on other brokers (servers). How? Each partition has a leader broker that handles writes/reads. Another broker acts as a follower (replica) to back up the partition.