












































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

















































































































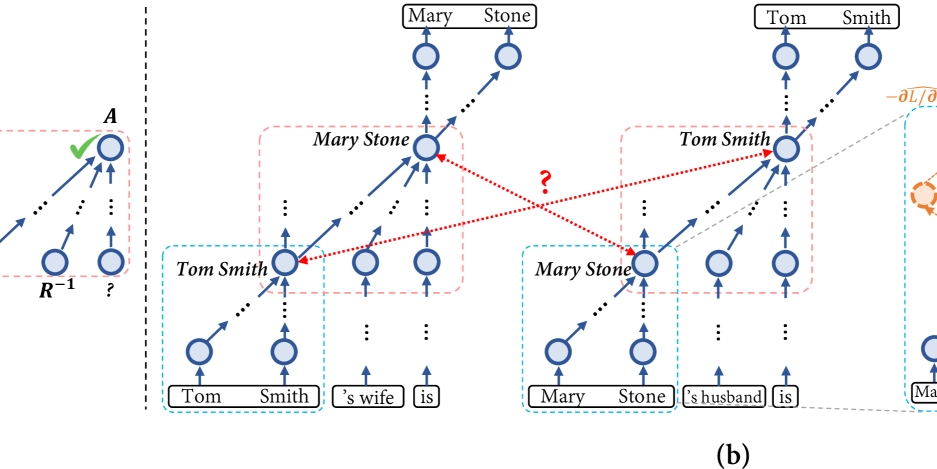





































![What tool should I be using for mapping a function across the complex domain? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)























































































.jpg?#)









































































































































![YouTube Announces New Creation Tools for Shorts [Video]](https://www.iclarified.com/images/news/96923/96923/96923-640.jpg)

![Apple Faces New Tariffs but Has Options to Soften the Blow [Kuo]](https://www.iclarified.com/images/news/96921/96921/96921-640.jpg)






















































































































Three Ways to Fight AI Crawlers
Until recently, websites were pushing for web crawlers to index their content properly. Now, a new type of crawler, AI crawlers, is changing the game, with negative repercussions on open source content and increasingly on companies that rely on content. Here is how to fight back. Why AI Crawlers Are Bad For The Internet As We Know It In short: Spikes in costs for the website owners Outages or performance issues for the users DDoS outages — In the worst cases Eventually, you get to the case of the founder of TechPays.com, where he noticed an over 10x increase in data outbound and over 90% of the traffic was AI crawlers. Why Is This A Problem? Because the content is scrapped for free and will then be sold to you through OpenAI, Meta AI, and whatever. Three Ways to Fight AI Crawlers So here are three ways to fight AI crawlers with their pros and cons. Using JavaScript Deploying AI Tarpits and Labyrinths Rate Limiting and Advanced Filtering Using JavaScript It seems AI crawlers struggle with JavaScript-heavy websites! AI crawlers like GPTBot (OpenAI), Claude (Anthropic), and PerplexityBot have difficulty processing, or don’t process at all, JavaScript-rendered content. While they fetch JavaScript files, they don’t execute the code, which results in useless content from the scraper's point of view. Fight AI Crawlers Deploying AI Tarpits and Labyrinths Tarpits are tools designed to trap AI crawlers in an endless maze of content, wasting their computational resources and time while protecting your actual content. These tools create dynamic networks of interconnected pages that lead nowhere, effectively preventing crawlers from accessing legitimate content. Popular Tarpit Solutions Nepenthes — Creates an “infinite maze” of static files with no exit links, effectively trapping AI crawlers and wasting their resources. This is brutal, and if you are searching for vengeance, this is the right tool for you! Cloudflare’s AI Labyrinth: Uses AI-generated content to slow down, confuse, and waste the resources of crawlers that don’t respect “no crawl” directives. See how to use AI Labyrinth to stop AI crawlers Iocaine: Uses a reverse proxy to trap crawlers in an “infinite maze of garbage” with the intent to poison their data collection. Iocaine is also based on Nepenthes but “Iocaine is purely about generating garbage.” Fight AI Crawlers Using Rate Limiting and Advanced Filtering Setting up geographical filtering with challenges (like CAPTCHAs or JavaScript tests) for visitors from countries outside your target market can significantly reduce unwanted crawler traffic. A few examples: The sysadmin of the Linux Fedora project had to block the entire country of Brazil to combat aggressive AI scrapers! The founder of TechPays.com also tried this before moving to stronger measures like turning on Cloudflare’s AI crawler block Find more techniques to deal with AI crawlers, but this is a pretty good starting point. Final Considerations Most likely, a good approach consists of a combination of several techniques like IP blocking and Cloudflare’s AI crawler blocking. Furthermore, tarpit technologies and advanced rate limiting seem to be more robust against aggressive crawlers. Obviously, you don’t want to block completely all AI crawlers because it could potentially hide your content from human visitors who rely on AI-powered searches to find your site.
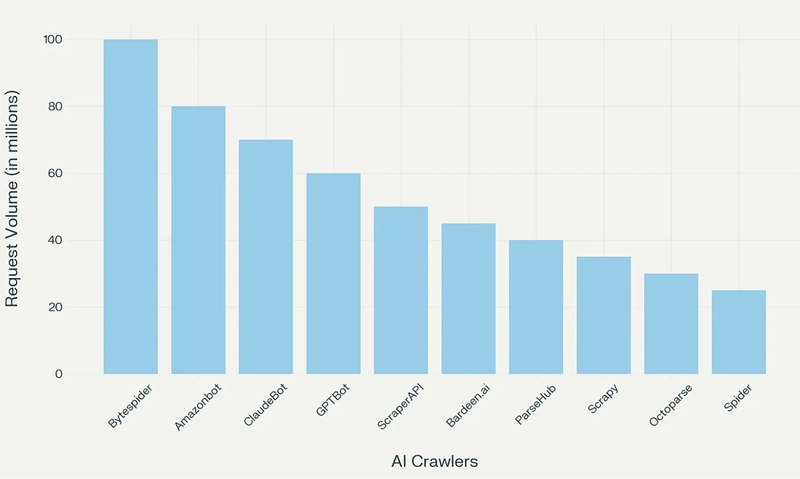
Until recently, websites were pushing for web crawlers to index their content properly.
Now, a new type of crawler, AI crawlers, is changing the game, with negative repercussions on open source content and increasingly on companies that rely on content.
Here is how to fight back.
Why AI Crawlers Are Bad For The Internet As We Know It
In short:
- Spikes in costs for the website owners
- Outages or performance issues for the users
- DDoS outages — In the worst cases
Eventually, you get to the case of the founder of TechPays.com, where he noticed an over 10x increase in data outbound and over 90% of the traffic was AI crawlers.
Why Is This A Problem?
Because the content is scrapped for free and will then be sold to you through OpenAI, Meta AI, and whatever.
Three Ways to Fight AI Crawlers
So here are three ways to fight AI crawlers with their pros and cons.
- Using JavaScript
- Deploying AI Tarpits and Labyrinths
- Rate Limiting and Advanced Filtering
Using JavaScript
It seems AI crawlers struggle with JavaScript-heavy websites!
AI crawlers like GPTBot (OpenAI), Claude (Anthropic), and PerplexityBot have difficulty processing, or don’t process at all, JavaScript-rendered content.
While they fetch JavaScript files, they don’t execute the code, which results in useless content from the scraper's point of view.
Fight AI Crawlers Deploying AI Tarpits and Labyrinths
Tarpits are tools designed to trap AI crawlers in an endless maze of content, wasting their computational resources and time while protecting your actual content.
These tools create dynamic networks of interconnected pages that lead nowhere, effectively preventing crawlers from accessing legitimate content.
Popular Tarpit Solutions
- Nepenthes — Creates an “infinite maze” of static files with no exit links, effectively trapping AI crawlers and wasting their resources. This is brutal, and if you are searching for vengeance, this is the right tool for you!
- Cloudflare’s AI Labyrinth: Uses AI-generated content to slow down, confuse, and waste the resources of crawlers that don’t respect “no crawl” directives. See how to use AI Labyrinth to stop AI crawlers
- Iocaine: Uses a reverse proxy to trap crawlers in an “infinite maze of garbage” with the intent to poison their data collection. Iocaine is also based on Nepenthes but “Iocaine is purely about generating garbage.”

Fight AI Crawlers Using Rate Limiting and Advanced Filtering
Setting up geographical filtering with challenges (like CAPTCHAs or JavaScript tests) for visitors from countries outside your target market can significantly reduce unwanted crawler traffic.
A few examples:
- The sysadmin of the Linux Fedora project had to block the entire country of Brazil to combat aggressive AI scrapers!
- The founder of TechPays.com also tried this before moving to stronger measures like turning on Cloudflare’s AI crawler block
Find more techniques to deal with AI crawlers, but this is a pretty good starting point.
Final Considerations
Most likely, a good approach consists of a combination of several techniques like IP blocking and Cloudflare’s AI crawler blocking.
Furthermore, tarpit technologies and advanced rate limiting seem to be more robust against aggressive crawlers.
Obviously, you don’t want to block completely all AI crawlers because it could potentially hide your content from human visitors who rely on AI-powered searches to find your site.




