





















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)


















































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)




































































































































































































![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)
















































































































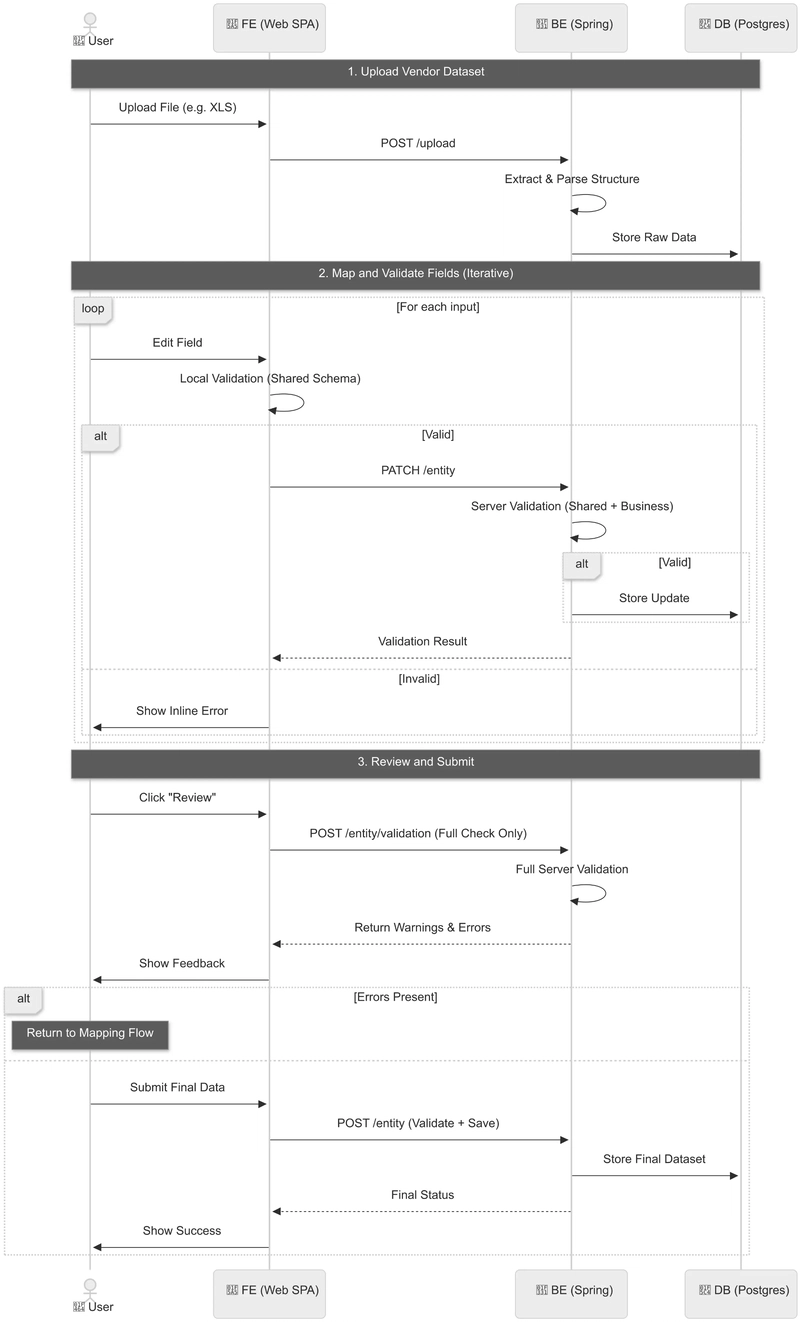
Reusable Form Validation Architecture for RESTful Systems
TL;DR Expose validation as a separate endpoint, not just tied to data submission Return structured response to give the frontend control over UX. Support partial and full dataset validation Use shared schema to sync similar frontend and backend validations Keep validation logic modular and testable Implement severity levels for flexible feedback Design for extensibility from the start For more than a year, I’ve been working on an internal application built to map external vendor datasets into our system. Vendors supply data in different formats, with inconsistent structure. Our team started fast and from scratch. But without unified validation patterns, every new feature required meetings to align on validation contracts, was difficult to extend, and occasionally resulted in inconsistent UX. If any of these sound familiar, this post might help: “Why is our validation logic duplicated?” “Why does the backend reject data the frontend already validated?” Why is it so hard to extend validation behavior when new requirements arrive?” “Why do our forms get messier with every new feature?” This article describes the validation architecture I proposed to solve those issues. The approach is pragmatic, reusable, and scalable. It works well for forms of varying complexity and has been tested in our production app. It separates responsibilities cleanly, avoids repetition, and brings consistent structure to form behavior across the application. Though all the solutions used in this architecture are simple on their own, they’re rarely integrated into a cohesive system. As a result, many applications lack a consistent, system-wide validation pattern. This article also serves as an internal reference for future iterations—so we don’t end up reinventing the wheel. Production Context The System Behind the Architecture The system that integrates this architecture is the single-page application (SPA) that communicates with the Spring-based backend via RESTful API. It manages large datasets through a multi-step form flow, as experienced by the user. User input is stored on the backend after each change, enabling the session to be resumed later or picked up by another operator—with no risk of data loss. The architecture combines quick frontend validation with deeper backend checks like duplicate detection and dataset-wide integrity analysis. Use cases The same validation model supports both persistent workflows and simpler one-shot forms. Multi-step mapping flow forms These forms can be large and long-lived. User input needs to be persisted step-by-step so the session can be resumed later. This adds complexity: when restoring saved data, we also need to restore validation state–warnings and informational messages (see Supported Severities). Simple forms These are small, self-contained forms. They don’t persist data on change, and there’s no need to restore previous state or validation results. One-time submission is enough. Understanding validation and beyond When building complex forms, one of the most important questions to answer is: What do we validate, when, and how? Go beyond validation - check! Although we use the word validation, which often implies blocking bad input, real-world B2B applications typically require more. In practice, we need to return errors, warnings, and hints—offering feedback that guides rather than blocks. Even if you don’t need this level of flexibility today, adopting a generalized model early makes it easier to evolve later. The pattern is extensible by design. Severity levels We define 3 severity levels: error — prevents the user from submitting data (e.g. missing required field, invalid value) warning — the user can proceed but is encouraged to review and confirm (e.g. dangerous side effects) info — informational only (e.g. minor side effects, AI hints) Throughout the article, validation refers broadly to checks, informational feedback—not just blocking errors. Commonly recognized validation types Readers familiar with the most common frontend/backend validation splits may skip to next section. This section is left here to cover wider points of view and concepts. Structural vs. Business Validation While all validation ultimately supports business needs, it might be useful to distinguish between structural checks (focused on data shape and storage) and business rules (a common naming for all context and domain-dependent types of validation). Structural validation This is the “engineering layer” of defense. It answers: “Can this be stored in the database?” This validation is context-independent and purely checks the shape, format, and data types. Typical checks are: required fields, type constraints, max length, regex pattern, etc. Business validation Also called Domain Validation or Contextual Validation. This lay
TL;DR
- Expose validation as a separate endpoint, not just tied to data submission
- Return structured response to give the frontend control over UX.
- Support partial and full dataset validation
- Use shared schema to sync similar frontend and backend validations
- Keep validation logic modular and testable
- Implement severity levels for flexible feedback
- Design for extensibility from the start
For more than a year, I’ve been working on an internal application built to map external vendor datasets into our system. Vendors supply data in different formats, with inconsistent structure.
Our team started fast and from scratch. But without unified validation patterns, every new feature required meetings to align on validation contracts, was difficult to extend, and occasionally resulted in inconsistent UX.
If any of these sound familiar, this post might help:
- “Why is our validation logic duplicated?”
- “Why does the backend reject data the frontend already validated?”
- Why is it so hard to extend validation behavior when new requirements arrive?”
- “Why do our forms get messier with every new feature?”
This article describes the validation architecture I proposed to solve those issues. The approach is pragmatic, reusable, and scalable. It works well for forms of varying complexity and has been tested in our production app. It separates responsibilities cleanly, avoids repetition, and brings consistent structure to form behavior across the application.
Though all the solutions used in this architecture are simple on their own, they’re rarely integrated into a cohesive system. As a result, many applications lack a consistent, system-wide validation pattern.
This article also serves as an internal reference for future iterations—so we don’t end up reinventing the wheel.
Production Context
The System Behind the Architecture
The system that integrates this architecture is the single-page application (SPA) that communicates with the Spring-based backend via RESTful API. It manages large datasets through a multi-step form flow, as experienced by the user. User input is stored on the backend after each change, enabling the session to be resumed later or picked up by another operator—with no risk of data loss.
The architecture combines quick frontend validation with deeper backend checks like duplicate detection and dataset-wide integrity analysis.
Use cases
The same validation model supports both persistent workflows and simpler one-shot forms.
Multi-step mapping flow forms
These forms can be large and long-lived. User input needs to be persisted step-by-step so the session can be resumed later. This adds complexity: when restoring saved data, we also need to restore validation state–warnings and informational messages (see Supported Severities).
Simple forms
These are small, self-contained forms. They don’t persist data on change, and there’s no need to restore previous state or validation results. One-time submission is enough.
Understanding validation and beyond
When building complex forms, one of the most important questions to answer is: What do we validate, when, and how?
Go beyond validation - check!
Although we use the word validation, which often implies blocking bad input, real-world B2B applications typically require more. In practice, we need to return errors, warnings, and hints—offering feedback that guides rather than blocks. Even if you don’t need this level of flexibility today, adopting a generalized model early makes it easier to evolve later. The pattern is extensible by design.
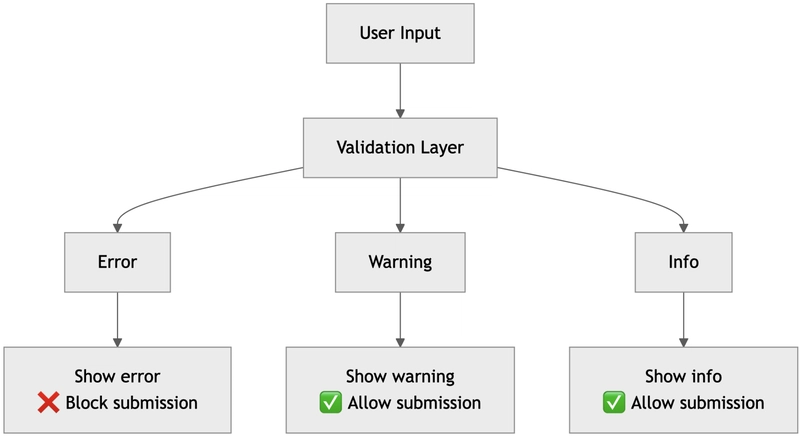
Severity levels
We define 3 severity levels:
- error — prevents the user from submitting data (e.g. missing required field, invalid value)
- warning — the user can proceed but is encouraged to review and confirm (e.g. dangerous side effects)
- info — informational only (e.g. minor side effects, AI hints)
Throughout the article, validation refers broadly to checks, informational feedback—not just blocking errors.
Commonly recognized validation types
Readers familiar with the most common frontend/backend validation splits may skip to next section. This section is left here to cover wider points of view and concepts.
Structural vs. Business Validation
While all validation ultimately supports business needs, it might be useful to distinguish between structural checks (focused on data shape and storage) and business rules (a common naming for all context and domain-dependent types of validation).
Structural validation
This is the “engineering layer” of defense. It answers: “Can this be stored in the database?”
This validation is context-independent and purely checks the shape, format, and data types.
Typical checks are: required fields, type constraints, max length, regex pattern, etc.
Business validation
Also called Domain Validation or Contextual Validation.
This layer answers: “Does the data make sense in the context of the system?”
It checks everything beyond the structure. It is context-dependent, meaning it requires domain knowledge, business rules, and external references.
This wide category includes: semantic constraints (uniqueness, custom logic), referential integrity (foreign key checks, lookups), temporal checks (dates, lifecycle conditions), security checks (input sanitization), consistency checks (inter-field logic), conditional/contextual rules (role-based validation).
Synchronous vs. Asynchronous Validation
Some validation tasks might be too heavy to be executed in a synchronous way. Consider this when designing API.
Synchronous validation
Executed either on the frontend or as part of a single and rapid backend request. It should be fast, predictable, and provide instant feedback.
Asynchronous validation
Often it is a background job or queued task. This type typically handles heavier logic (e.g. dataset-wide deduplication). Since it takes time, the frontend must poll or subscribe for completion.
Partial vs. Full Dataset Validation
The key distinction here is: are we validating a dataset partially or the whole dataset?
Partial dataset validation
This type checks only what is available—e.g. a single field or partial dataset. Used in progressive forms where input is stored as the user works to restore the latest validation state (with all warnings and checks) or to get a validation result from the BE.
It’s like asking: “Can we store this right now without breaking anything?” It should be fast.
Full dataset validation
Typically triggered when the user clicks “Submit” or "Complete step". At this point, all data is available and should be validated holistically—regardless of processing time, limited only by the common sense of a good product design.
Frontend vs. Backend Validation
From an architectural perspective, we can define how validation responsibilities are split between the client and the server.
To ensure good user experience (UX), this split should be designed to deliver validation feedback:
- at the right time (immediate when needed, deferred when appropriate)
- in the right place (inline, near the relevant field or step)
- with the right message (clear, actionable, and context-aware)
Frontend (FE)
Frontend validation exists to improve responsiveness and avoid obviously invalid submissions. FE should execute as many checks as possible, which can be performed immediately on the client.
We should keep in mind that in some cases, like field mapping, the frontend works only with abstracted input (e.g. column names).
Backend (BE)
The backend owns all validation logic. In our case, it also runs additional checks to return warnings and info.
Shared vs. Server-only validation
This concept is based on the Frontend vs. Backend Validation concept and uses tools that allow the same validation logic to run on both FE and BE.
| Validation Name | Purpose | Implementation |
|---|---|---|
| Shared | Type, shape, basic semantics | JSON Schema, shared between FE & BE) |
| Server-only | Advanced logic, DB checks, context-driven rules | Custom functions, DB queries, complex logic |
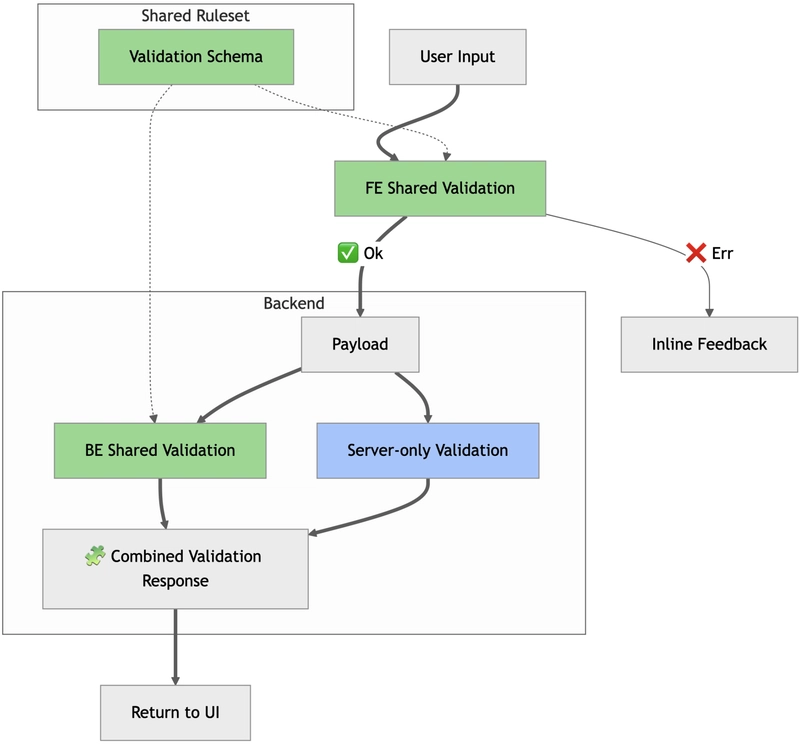
Shared validation
Shared validation is anything that can be defined once and applied consistently on both the frontend and the backend. Think of it as the contract for how input should be shaped and constrained.
This is the kind of validation that:
- runs fast on the FE side
- prevents invalid submissions early
- keeps shared part of validation logic in sync across FE and BE
It can be implemented using JSON Schema, which may significantly reduce duplication and edge-case bugs.
⚠️ We haven’t implemented shared validation with JSON Schema in our system yet. I encourage you to explore real-world case studies and community feedback to understand potential pitfalls and best practices.
For long-lived forms, be mindful of schema versioning and follow best practices from your validation library.
Server-only validation
Server validation covers all logic that can’t be expressed in a shared schema.
These types of checks are:
- usually complex
- requires access to context or external systems (e.g. DB queries, role-based checks)
REST API Design
The validation API is built around a small, predictable set of endpoints. It’s designed to be easy to start with, and easy to extend incrementally—without introducing breaking changes or complexity. The API promotes modular validation: checks are not tied exclusively to data submission (/entity) but are also exposed via validation-only endpoints (/entity/validation). This lets you evolve your REST API safely, without breaking changes.
Endpoint Overview
| Endpoint | Method | Purpose | Stores Data | Validation Type |
|---|---|---|---|---|
| /entity | PATCH | Save partial updates (1+ fields) | ✅ Yes | Partial (Shared + Server-only) |
| /entity | POST | Submit complete dataset | ✅ Yes | Full |
| /entity/validation | PATCH | Validate partial input | ❌ No | Partial (Shared + Server-only) |
| /entity/validation | POST | Validate full dataset | ❌ No | Full |
Implementation Details
- The frontend applies the shared ruleset and determines when to trigger BE validation.
- The backend combines shared + server-only validations in two reusable modules:
- Partial dataset validation
- Full dataset validation
These modules are reused between /entity and /entity/validation, avoiding code duplication and making it easy to unit-test validation logic in isolation.
See also Partial vs. Full Dataset Validation for more context.
API Usage Examples
In real-world projects, validation requirements often evolve over time. This design lets you start simple, and grow features gradually without breaking changes.
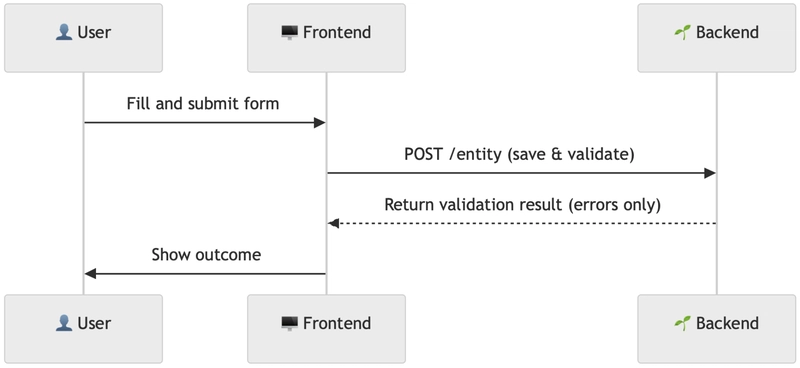
Example 1: Basic form
A minimal setup using only a single endpoint.
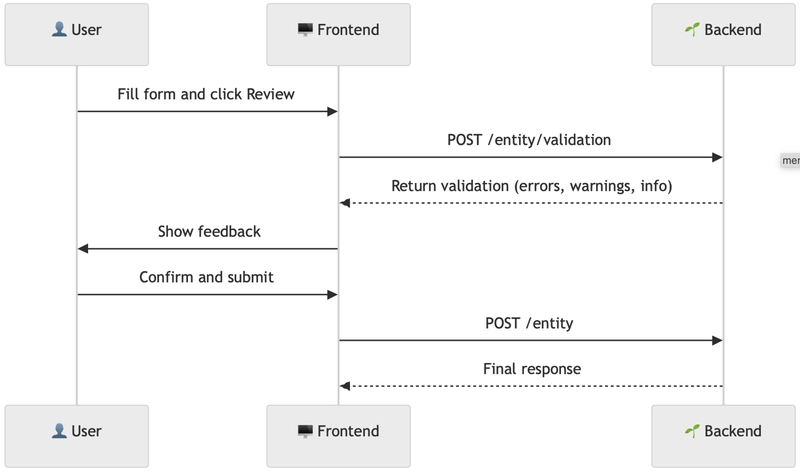
Example 2: Feedback with severities
Adds a “Review” step to get full validation feedback before submission.
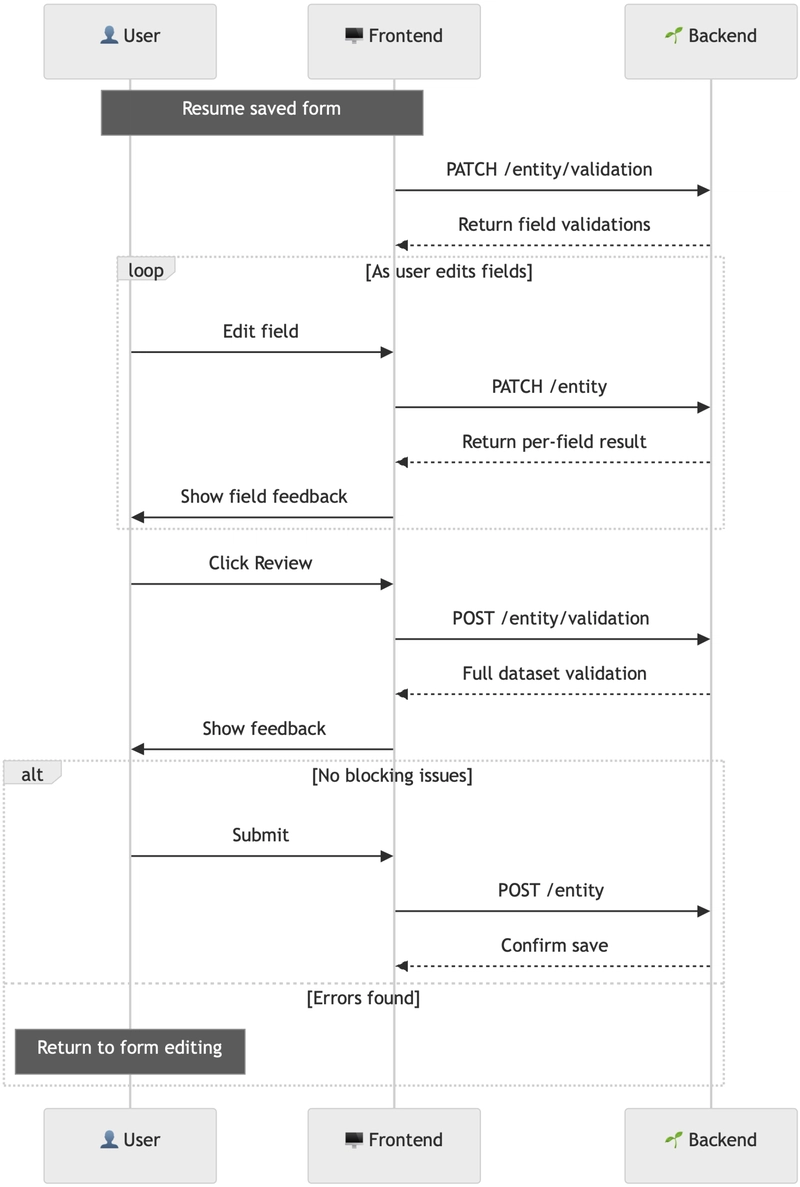
Example 3: Full-featured form
Demonstrates the complete flow with saved state, field-level feedback, and final validation.
Validation Response Model
All responses follow the same format. Each validation entry includes:
| Name | Required | Description |
|---|---|---|
code |
✅ | Machine-readable identifier |
severity |
✅ | See Severity Levels |
message |
✅ | Human-readable fallback text |
field |
Dot-path to the field (included for field-level validation only) | |
data |
Optional structured payload for enhanced feedback |
Example Response:
{
"validations": {
"fields": [
{
"field": "path.to.colorCode",
"code": "651232",
"severity": "error",
"message": "This color already exists in the system",
"data": {
"duplicates": [
{
"id": "A34-932r492",
"label": "Beige"
}
]
}
}
],
"dataset": [
{
"code": "615343",
"severity": "warning",
"message": "You are going to change global mappings."
}
]
}
}
Trade-offs & Considerations
Duplicated Validation Work
This architecture intentionally requires the frontend to submit the full dataset. The trade-off is increased payload size and potential duplicate validation work—e.g., validating both before and during final submission.
This reduces complexity in large mapping forms, especially those involving recommendation engines or dynamic data, where values may change between inputs. It helps to eliminate a major source of bugs: mismatches between what the user sees and what the backend processes. We ensure the backend always validates exactly what the user reviewed, no hidden assumptions.
In small forms where validation is lightweight, the extra work can be ignored. For heavier flows, techniques like checksum-based can be introduced later.
Heavy-lifting validation
Some validations may require intensive processing or external lookups. If execution time becomes an issue, consider a sync/async split or move certain checks into background jobs.
Summary
The TL;DR section at the top summarizes key takeaways. This pattern is built for clarity, consistency, and scalability. It supports:
- Fast, schema-based checks on the frontend
- Complete context-aware checks on the backend
- Extended feedback (warnings, info—not just errors)
- Partial and full dataset validation flows
- Support for persisted, restorable forms
- Modular, testable validation logic reused across endpoints
- Predictable validation structure across all features
- Easy to evolve without breaking changes
- Tight alignment between FE and BE logic, reducing hidden bugs
Whether you’re dealing with contact forms or complex data mapping workflows, it brings predictability and clarity to one of the messiest layers in web apps.
Noticed a blind spot? Disagree with something? I’d be genuinely interested in other perspectives — especially if they help sharpen or challenge the ideas here.